 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
CUA-Skill: Develop Skills for Computer Using Agent
Jan 28, 2026Computer-Using Agents (CUAs) aim to autonomously operate computer systems to complete real-world tasks. However, existing agentic systems remain difficult to scale and lag behind human performance. A key limitation is the absence of reusable and structured skill abstractions that capture how humans interact with graphical user interfaces and how to leverage these skills. We introduce CUA-Skill, a computer-using agentic skill base that encodes human computer-use knowledge as skills coupled with parameterized execution and composition graphs. CUA-Skill is a large-scale library of carefully engineered skills spanning common Windows applications, serving as a practical infrastructure and tool substrate for scalable, reliable agent development. Built upon this skill base, we construct CUA-Skill Agent, an end-to-end computer-using agent that supports dynamic skill retrieval, argument instantiation, and memory-aware failure recovery. Our results demonstrate that CUA-Skill substantially improves execution success rates and robustness on challenging end-to-end agent benchmarks, establishing a strong foundation for future computer-using agent development. On WindowsAgentArena, CUA-Skill Agent achieves state-of-the-art 57.5% (best of three) successful rate while being significantly more efficient than prior and concurrent approaches. The project page is available at https://microsoft.github.io/cua_skill/.
PCR-CA: Parallel Codebook Representations with Contrastive Alignment for Multiple-Category App Recommendation
Aug 25, 2025Modern app store recommender systems struggle with multiple-category apps, as traditional taxonomies fail to capture overlapping semantics, leading to suboptimal personalization. We propose PCR-CA (Parallel Codebook Representations with Contrastive Alignment), an end-to-end framework for improved CTR prediction. PCR-CA first extracts compact multimodal embeddings from app text, then introduces a Parallel Codebook VQ-AE module that learns discrete semantic representations across multiple codebooks in parallel -- unlike hierarchical residual quantization (RQ-VAE). This design enables independent encoding of diverse aspects (e.g., gameplay, art style), better modeling multiple-category semantics. To bridge semantic and collaborative signals, we employ a contrastive alignment loss at both the user and item levels, enhancing representation learning for long-tail items. Additionally, a dual-attention fusion mechanism combines ID-based and semantic features to capture user interests, especially for long-tail apps. Experiments on a large-scale dataset show PCR-CA achieves a +0.76% AUC improvement over strong baselines, with +2.15% AUC gains for long-tail apps. Online A/B testing further validates our approach, showing a +10.52% lift in CTR and a +16.30% improvement in CVR, demonstrating PCR-CA's effectiveness in real-world deployment. The new framework has now been fully deployed on the Microsoft Store.
Aerial Multi-View Stereo via Adaptive Depth Range Inference and Normal Cues
Jun 06, 2025Three-dimensional digital urban reconstruction from multi-view aerial images is a critical application where deep multi-view stereo (MVS) methods outperform traditional techniques. However, existing methods commonly overlook the key differences between aerial and close-range settings, such as varying depth ranges along epipolar lines and insensitive feature-matching associated with low-detailed aerial images. To address these issues, we propose an Adaptive Depth Range MVS (ADR-MVS), which integrates monocular geometric cues to improve multi-view depth estimation accuracy. The key component of ADR-MVS is the depth range predictor, which generates adaptive range maps from depth and normal estimates using cross-attention discrepancy learning. In the first stage, the range map derived from monocular cues breaks through predefined depth boundaries, improving feature-matching discriminability and mitigating convergence to local optima. In later stages, the inferred range maps are progressively narrowed, ultimately aligning with the cascaded MVS framework for precise depth regression. Moreover, a normal-guided cost aggregation operation is specially devised for aerial stereo images to improve geometric awareness within the cost volume. Finally, we introduce a normal-guided depth refinement module that surpasses existing RGB-guided techniques. Experimental results demonstrate that ADR-MVS achieves state-of-the-art performance on the WHU, LuoJia-MVS, and M\"unchen datasets, while exhibits superior computational complexity.
FNIN: A Fourier Neural Operator-based Numerical Integration Network for Surface-form-gradients
Jan 21, 2025
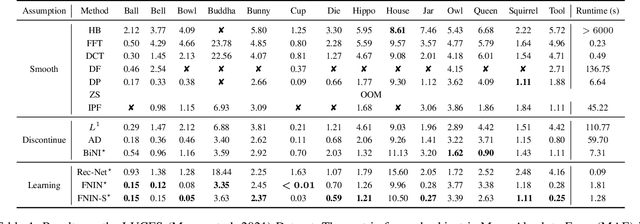
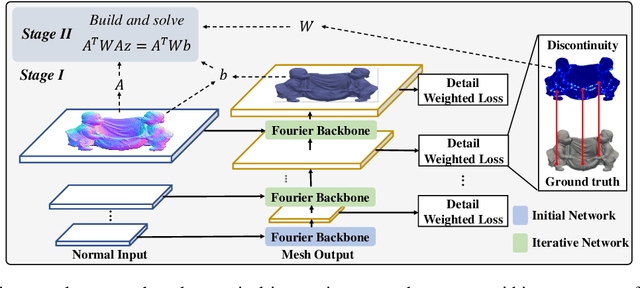
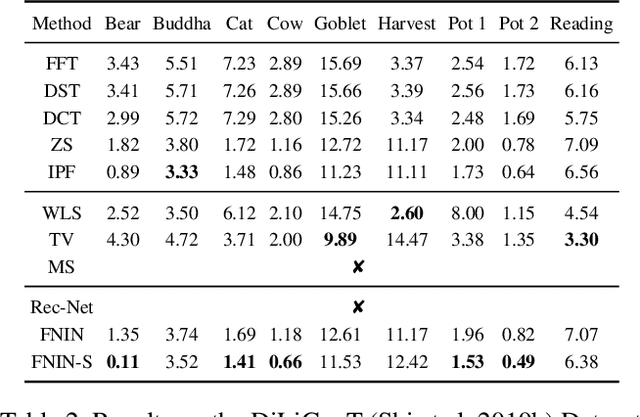
Surface-from-gradients (SfG) aims to recover a three-dimensional (3D) surface from its gradients. Traditional methods encounter significant challenges in achieving high accuracy and handling high-resolution inputs, particularly facing the complex nature of discontinuities and the inefficiencies associated with large-scale linear solvers. Although recent advances in deep learning, such as photometric stereo, have enhanced normal estimation accuracy, they do not fully address the intricacies of gradient-based surface reconstruction. To overcome these limitations, we propose a Fourier neural operator-based Numerical Integration Network (FNIN) within a two-stage optimization framework. In the first stage, our approach employs an iterative architecture for numerical integration, harnessing an advanced Fourier neural operator to approximate the solution operator in Fourier space. Additionally, a self-learning attention mechanism is incorporated to effectively detect and handle discontinuities. In the second stage, we refine the surface reconstruction by formulating a weighted least squares problem, addressing the identified discontinuities rationally. Extensive experiments demonstrate that our method achieves significant improvements in both accuracy and efficiency compared to current state-of-the-art solvers. This is particularly evident in handling high-resolution images with complex data, achieving errors of fewer than 0.1 mm on tested objects.
Few-shot Human Motion Recognition through Multi-Aspect mmWave FMCW Radar Data
Jan 19, 2025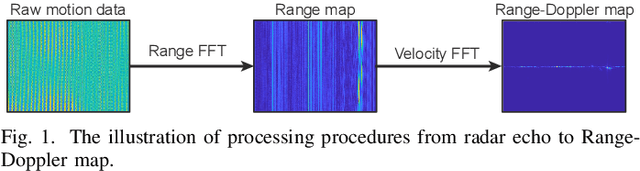
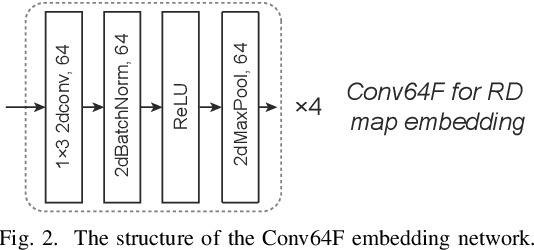
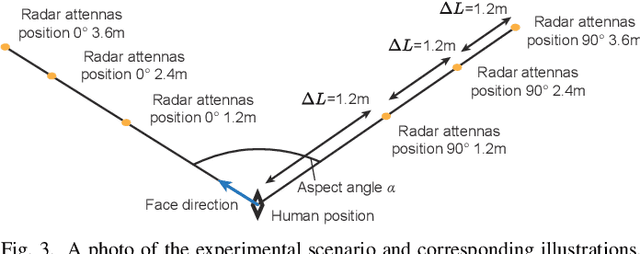
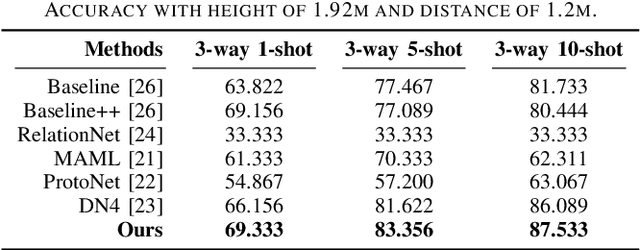
Radar human motion recognition methods based on deep learning models has been a heated spot of remote sensing in recent years, yet the existing methods are mostly radial-oriented. In practical application, the test data could be multi-aspect and the sample number of each motion could be very limited, causing model overfitting and reduced recognition accuracy. This paper proposed channel-DN4, a multi-aspect few-shot human motion recognition method. First, local descriptors are introduced for a precise classification metric. Moreover, episodic training strategy was adopted to reduce model overfitting. To utilize the invariant sematic information in multi-aspect conditions, we considered channel attention after the embedding network to obtain precise implicit high-dimensional representation of sematic information. We tested the performance of channel-DN4 and methods for comparison on measured mmWave FMCW radar data. The proposed channel-DN4 produced competitive and convincing results, reaching the highest 87.533% recognition accuracy in 3-way 10-shot condition while other methods suffer from overfitting. Codes are available at: https://github.com/MountainChenCad/channel-DN4
TiM4Rec: An Efficient Sequential Recommendation Model Based on Time-Aware Structured State Space Duality Model
Sep 24, 2024
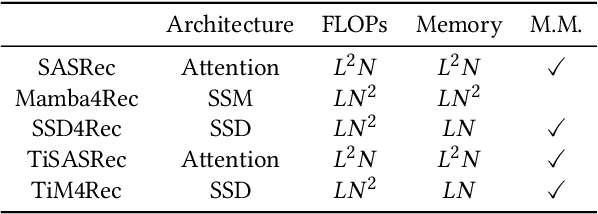
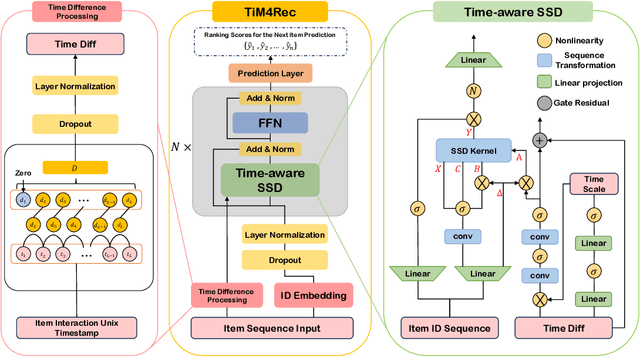
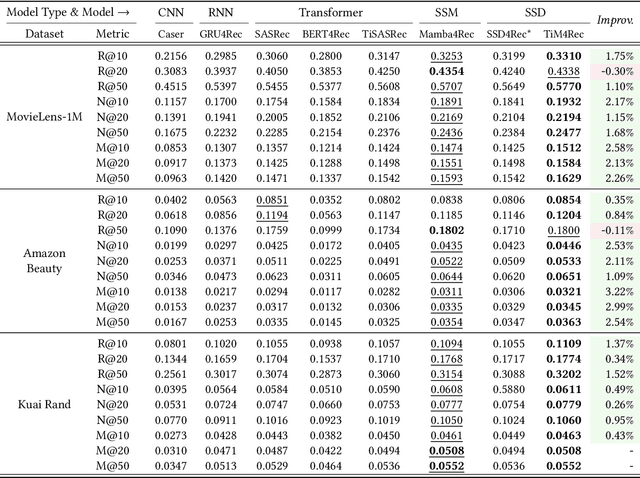
Sequential recommendation represents a pivotal branch of recommendation systems, centered around dynamically analyzing the sequential dependencies between user preferences and their interactive behaviors. Despite the Transformer architecture-based models achieving commendable performance within this domain, their quadratic computational complexity relative to the sequence dimension impedes efficient modeling. In response, the innovative Mamba architecture, characterized by linear computational complexity, has emerged. Mamba4Rec further pioneers the application of Mamba in sequential recommendation. Nonetheless, Mamba 1's hardware-aware algorithm struggles to efficiently leverage modern matrix computational units, which lead to the proposal of the improved State Space Duality (SSD), also known as Mamba 2. While the SSD4Rec successfully adapts the SSD architecture for sequential recommendation, showing promising results in high-dimensional contexts, it suffers significant performance drops in low-dimensional scenarios crucial for pure ID sequential recommendation tasks. Addressing this challenge, we propose a novel sequential recommendation backbone model, TiM4Rec, which ameliorates the low-dimensional performance loss of the SSD architecture while preserving its computational efficiency. Drawing inspiration from TiSASRec, we develop a time-aware enhancement method tailored for the linear computation demands of the SSD architecture, thereby enhancing its adaptability and achieving state-of-the-art (SOTA) performance in both low and high-dimensional modeling. The code for our model is publicly accessible at https://github.com/AlwaysFHao/TiM4Rec.
ZipGait: Bridging Skeleton and Silhouette with Diffusion Model for Advancing Gait Recognition
Aug 22, 2024Current gait recognition research predominantly focuses on extracting appearance features effectively, but the performance is severely compromised by the vulnerability of silhouettes under unconstrained scenes. Consequently, numerous studies have explored how to harness information from various models, particularly by sufficiently utilizing the intrinsic information of skeleton sequences. While these model-based methods have achieved significant performance, there is still a huge gap compared to appearance-based methods, which implies the potential value of bridging silhouettes and skeletons. In this work, we make the first attempt to reconstruct dense body shapes from discrete skeleton distributions via the diffusion model, demonstrating a new approach that connects cross-modal features rather than focusing solely on intrinsic features to improve model-based methods. To realize this idea, we propose a novel gait diffusion model named DiffGait, which has been designed with four specific adaptations suitable for gait recognition. Furthermore, to effectively utilize the reconstructed silhouettes and skeletons, we introduce Perception Gait Integration (PGI) to integrate different gait features through a two-stage process. Incorporating those modifications leads to an efficient model-based gait recognition framework called ZipGait. Through extensive experiments on four public benchmarks, ZipGait demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both cross-domain and intra-domain settings, while achieving significant plug-and-play performance improvements.
Heterogeneous Subgraph Transformer for Fake News Detection
Apr 19, 2024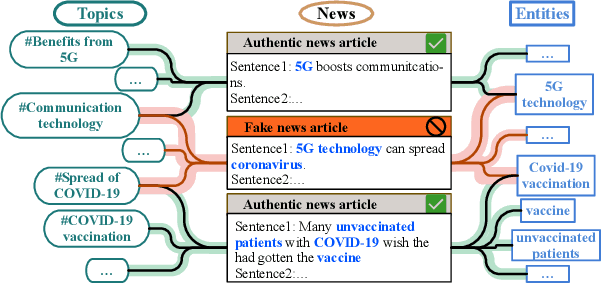
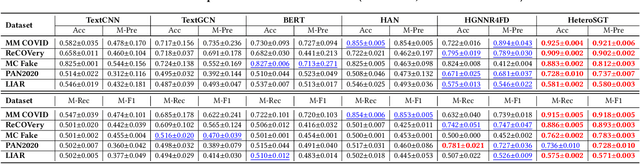
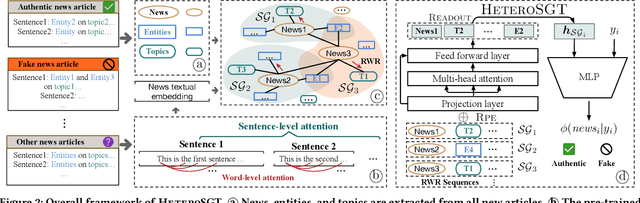
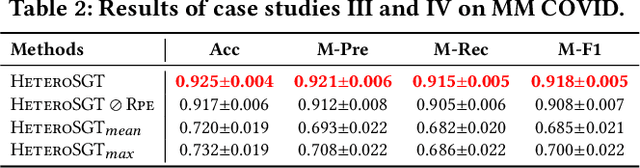
Fake news is pervasive on social media, inflicting substantial harm on public discourse and societal well-being. We investigate the explicit structural information and textual features of news pieces by constructing a heterogeneous graph concerning the relations among news topics, entities, and content. Through our study, we reveal that fake news can be effectively detected in terms of the atypical heterogeneous subgraphs centered on them, which encapsulate the essential semantics and intricate relations between news elements. However, suffering from the heterogeneity, exploring such heterogeneous subgraphs remains an open problem. To bridge the gap, this work proposes a heterogeneous subgraph transformer (HeteroSGT) to exploit subgraphs in our constructed heterogeneous graph. In HeteroSGT, we first employ a pre-trained language model to derive both word-level and sentence-level semantics. Then the random walk with restart (RWR) is applied to extract subgraphs centered on each news, which are further fed to our proposed subgraph Transformer to quantify the authenticity. Extensive experiments on five real-world datasets demonstrate the superior performance of HeteroSGT over five baselines. Further case and ablation studies validate our motivation and demonstrate that performance improvement stems from our specially designed components.
Efficient Batch Homomorphic Encryption for Vertically Federated XGBoost
Dec 08, 2021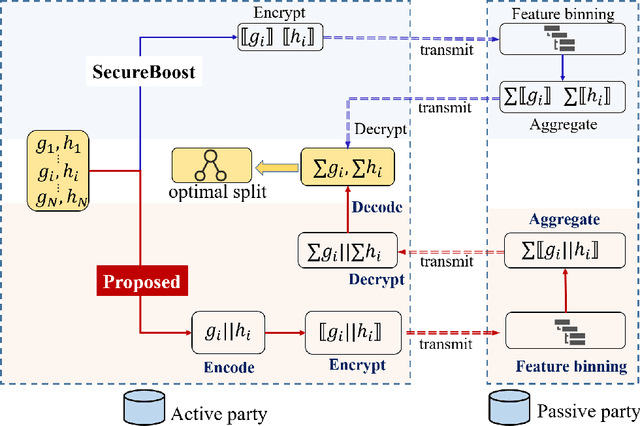
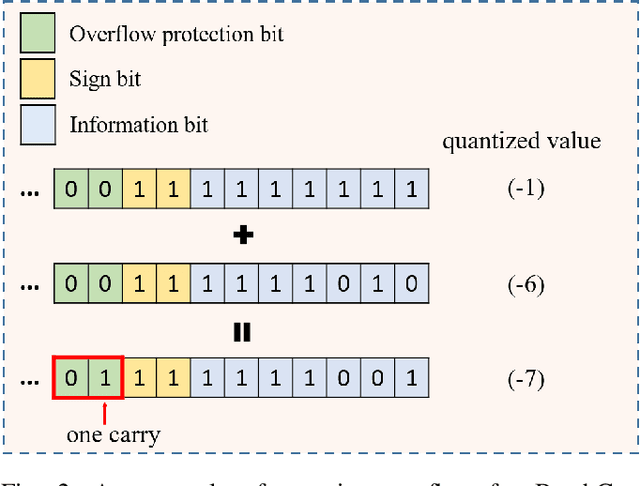
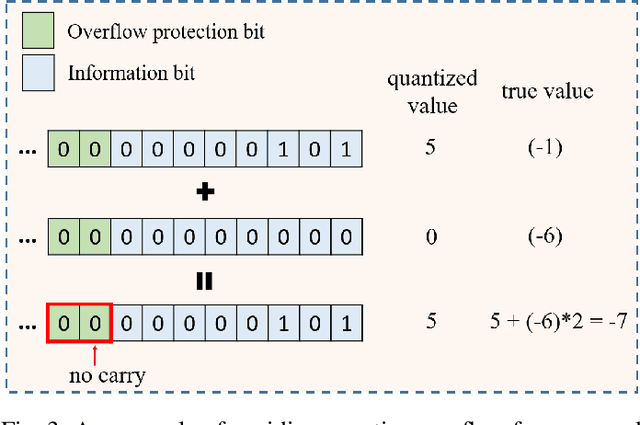
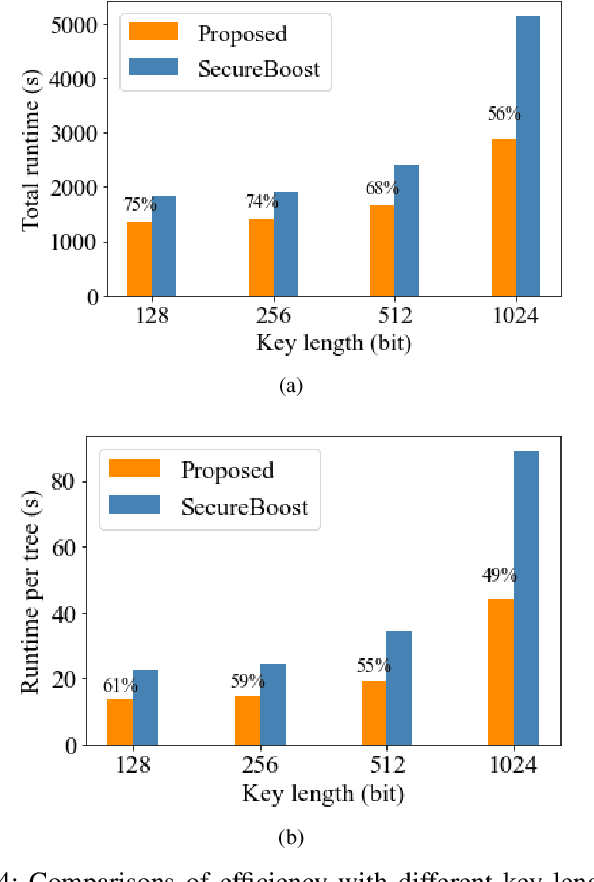
More and more orgainizations and institutions make efforts on using external data to improve the performance of AI services. To address the data privacy and security concerns, federated learning has attracted increasing attention from both academia and industry to securely construct AI models across multiple isolated data providers. In this paper, we studied the efficiency problem of adapting widely used XGBoost model in real-world applications to vertical federated learning setting. State-of-the-art vertical federated XGBoost frameworks requires large number of encryption operations and ciphertext transmissions, which makes the model training much less efficient than training XGBoost models locally. To bridge this gap, we proposed a novel batch homomorphic encryption method to cut the cost of encryption-related computation and transmission in nearly half. This is achieved by encoding the first-order derivative and the second-order derivative into a single number for encryption, ciphertext transmission, and homomorphic addition operations. The sum of multiple first-order derivatives and second-order derivatives can be simultaneously decoded from the sum of encoded values. We are motivated by the batch idea in the work of BatchCrypt for horizontal federated learning, and design a novel batch method to address the limitations of allowing quite few number of negative numbers. The encode procedure of the proposed batch method consists of four steps, including shifting, truncating, quantizing and batching, while the decoding procedure consists of de-quantization and shifting back. The advantages of our method are demonstrated through theoretical analysis and extensive numerical experiments.