 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving nonlinear subsonic compressible flow in infinite domain via multi-stage neural networks
Jan 01, 2026In aerodynamics, accurately modeling subsonic compressible flow over airfoils is critical for aircraft design. However, solving the governing nonlinear perturbation velocity potential equation presents computational challenges. Traditional approaches often rely on linearized equations or finite, truncated domains, which introduce non-negligible errors and limit applicability in real-world scenarios. In this study, we propose a novel framework utilizing Physics-Informed Neural Networks (PINNs) to solve the full nonlinear compressible potential equation in an unbounded (infinite) domain. We address the unbounded-domain and convergence challenges inherent in standard PINNs by incorporating a coordinate transformation and embedding physical asymptotic constraints directly into the network architecture. Furthermore, we employ a Multi-Stage PINN (MS-PINN) approach to iteratively minimize residuals, achieving solution accuracy approaching machine precision. We validate this framework by simulating flow over circular and elliptical geometries, comparing our results against traditional finite-domain and linearized solutions. Our findings quantify the noticeable discrepancies introduced by domain truncation and linearization, particularly at higher Mach numbers, and demonstrate that this new framework is a robust, high-fidelity tool for computational fluid dynamics.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024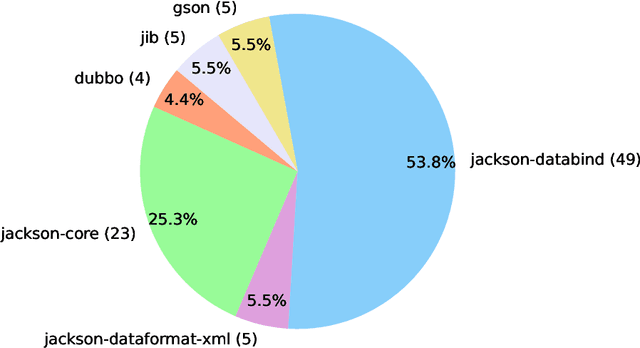



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
Spectrum-Informed Multistage Neural Networks: Multiscale Function Approximators of Machine Precision
Jul 24, 2024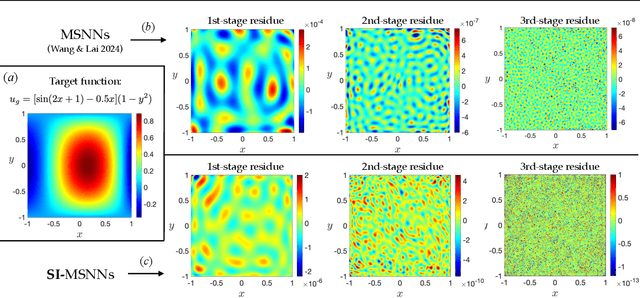
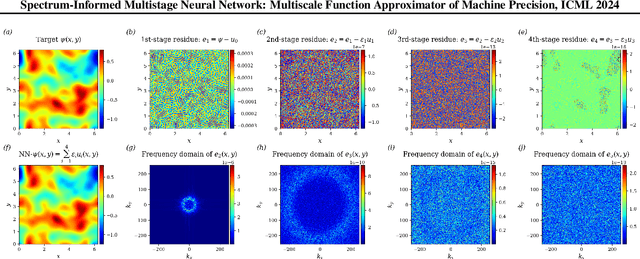
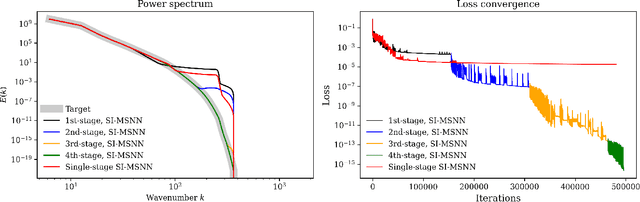
Deep learning frameworks have become powerful tools for approaching scientific problems such as turbulent flow, which has wide-ranging applications. In practice, however, existing scientific machine learning approaches have difficulty fitting complex, multi-scale dynamical systems to very high precision, as required in scientific contexts. We propose using the novel multistage neural network approach with a spectrum-informed initialization to learn the residue from the previous stage, utilizing the spectral biases associated with neural networks to capture high frequency features in the residue, and successfully tackle the spectral bias of neural networks. This approach allows the neural network to fit target functions to double floating-point machine precision $O(10^{-16})$.
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024



The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Improving Natural Language Capability of Code Large Language Model
Jan 25, 2024Code large language models (Code LLMs) have demonstrated remarkable performance in code generation. Nonetheless, most existing works focus on boosting code LLMs from the perspective of programming capabilities, while their natural language capabilities receive less attention. To fill this gap, we thus propose a novel framework, comprising two modules: AttentionExtractor, which is responsible for extracting key phrases from the user's natural language requirements, and AttentionCoder, which leverages these extracted phrases to generate target code to solve the requirement. This framework pioneers an innovative idea by seamlessly integrating code LLMs with traditional natural language processing tools. To validate the effectiveness of the framework, we craft a new code generation benchmark, called MultiNL-H, covering five natural languages. Extensive experimental results demonstrate the effectiveness of our proposed framework.
A GAN-based data poisoning framework against anomaly detection in vertical federated learning
Jan 17, 2024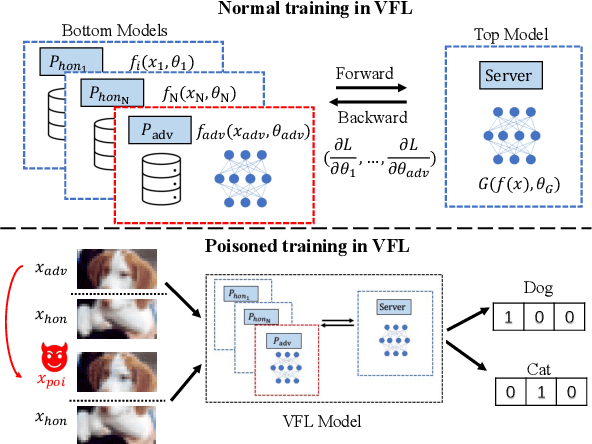
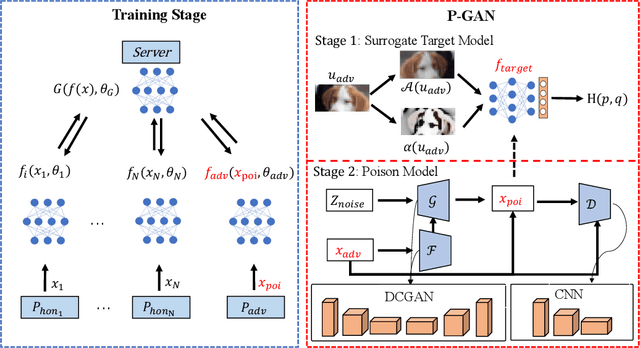
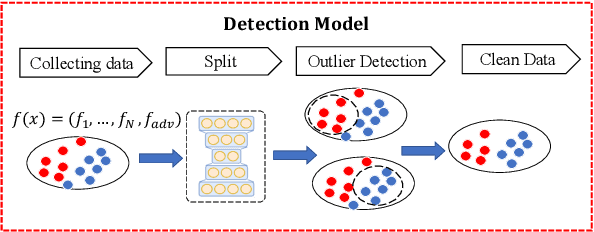
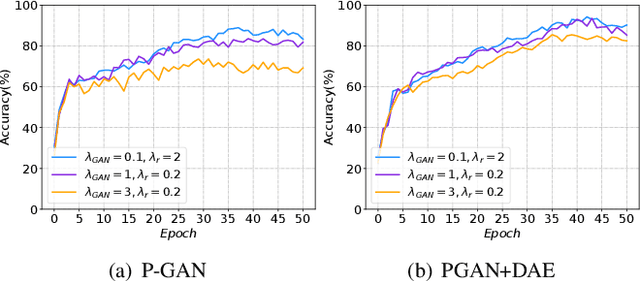
In vertical federated learning (VFL), commercial entities collaboratively train a model while preserving data privacy. However, a malicious participant's poisoning attack may degrade the performance of this collaborative model. The main challenge in achieving the poisoning attack is the absence of access to the server-side top model, leaving the malicious participant without a clear target model. To address this challenge, we introduce an innovative end-to-end poisoning framework P-GAN. Specifically, the malicious participant initially employs semi-supervised learning to train a surrogate target model. Subsequently, this participant employs a GAN-based method to produce adversarial perturbations to degrade the surrogate target model's performance. Finally, the generator is obtained and tailored for VFL poisoning. Besides, we develop an anomaly detection algorithm based on a deep auto-encoder (DAE), offering a robust defense mechanism to VFL scenarios. Through extensive experiments, we evaluate the efficacy of P-GAN and DAE, and further analyze the factors that influence their performance.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Integrated lithium niobate photonic millimeter-wave radar
Nov 16, 2023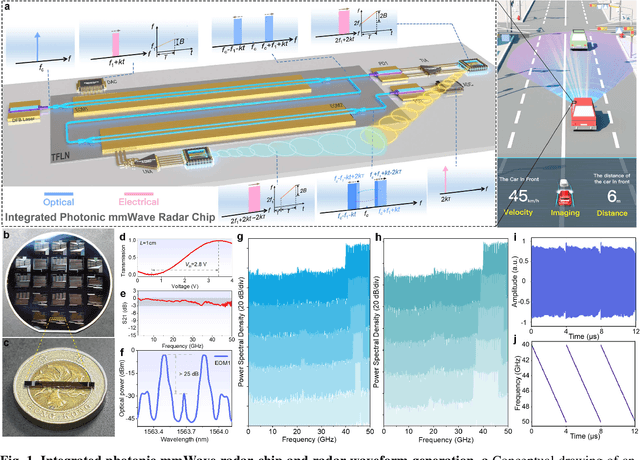
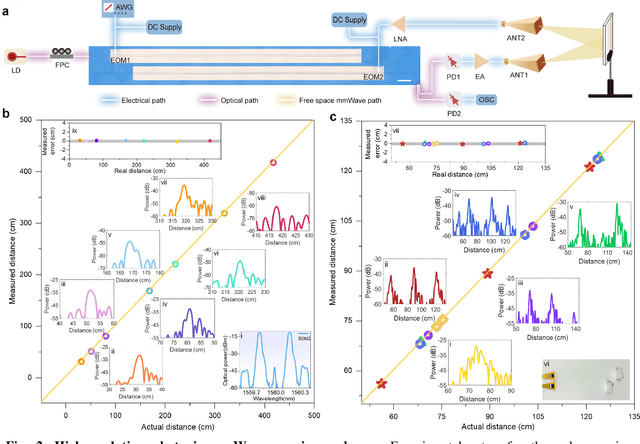
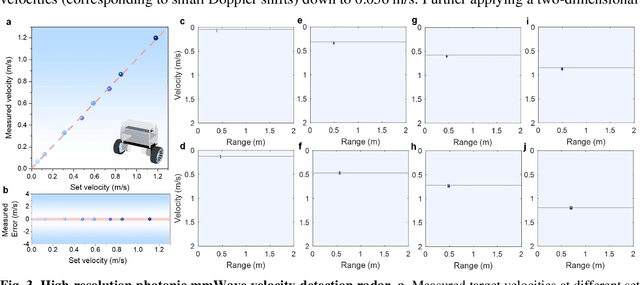
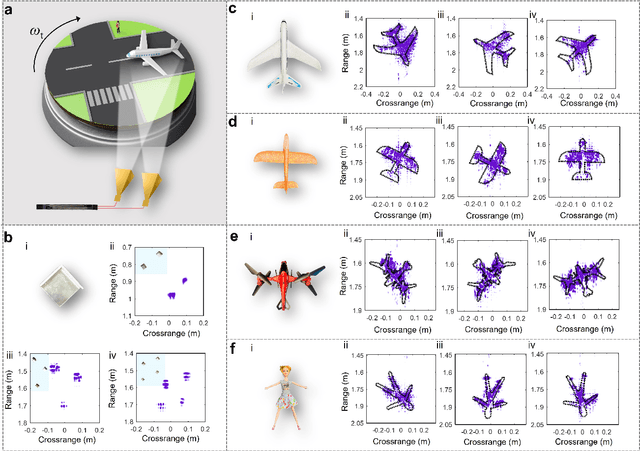
Millimeter-wave (mmWave,>30 GHz) radars are the key enabler in the coming 6G era for high-resolution sensing and detection of targets. Photonic radar provides an effective approach to overcome the limitations of electronic radars thanks to the high frequency, broad bandwidth, and excellent reconfigurability of photonic systems. However, conventional photonic radars are mostly realized in tabletop systems composed of bulky discrete components, whereas the more compact integrated photonic radars are difficult to reach the mmWave bands due to the unsatisfactory bandwidths and signal integrity of the underlining electro-optic modulators. Here, we overcome these challenges and demonstrate a centimeter-resolution integrated photonic radar operating in the mmWave V band (40-50 GHz) based on a 4-inch wafer-scale thin-film lithium niobate (TFLN) technology. The fabricated TFLN mmWave photonic integrated circuit consists of a first electro-optic modulator capable of generating a broadband linear frequency modulated mmWave radar waveform through optical frequency multiplication of a low-frequency input signal, and a second electro-optic modulator responsible for frequency de-chirp of the received reflected echo wave, therefore greatly relieving the bandwidth requirements for the analog-to-digital converter in the receiver. Thanks to the absence of optical and electrical filters in the system, our integrated photonic mmWave radar features continuous on-demand tunability of the center frequency and bandwidth, currently only limited by the bandwidths of electrical amplifiers. We achieve multi-target ranging with a resolution of 1.50 cm and velocity measurement with a resolution of 0.067 m/s. Furthermore, we construct an inverse synthetic aperture radar (ISAR) and successfully demonstrate the imaging of targets with various shapes and postures with a two-dimensional resolution of 1.50 cm * 1.06 cm.
Can Programming Languages Boost Each Other via Instruction Tuning?
Sep 03, 2023
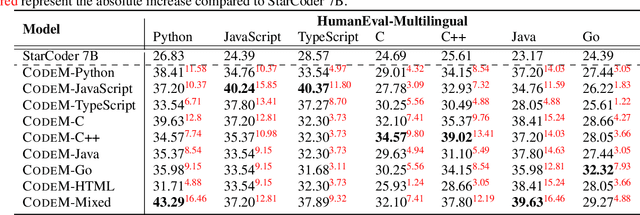


When human programmers have mastered a programming language, it would be easier when they learn a new programming language. In this report, we focus on exploring whether programming languages can boost each other during the instruction fine-tuning phase of code large language models. We conduct extensive experiments of 8 popular programming languages (Python, JavaScript, TypeScript, C, C++, Java, Go, HTML) on StarCoder. Results demonstrate that programming languages can significantly improve each other. For example, CodeM-Python 15B trained on Python is able to increase Java by an absolute 17.95% pass@1 on HumanEval-X. More surprisingly, we found that CodeM-HTML 7B trained on the HTML corpus can improve Java by an absolute 15.24% pass@1. Our training data is released at https://github.com/NL2Code/CodeM.