 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024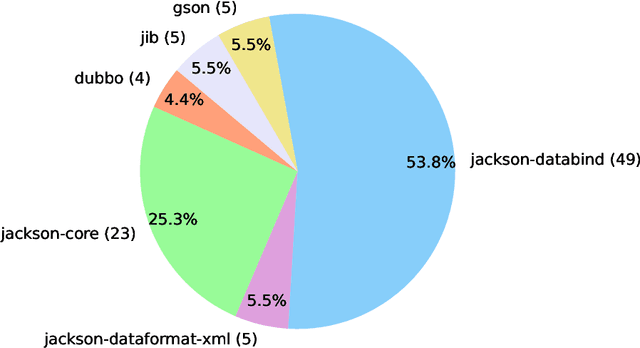



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
CodeS: Natural Language to Code Repository via Multi-Layer Sketch
Mar 25, 2024



The impressive performance of large language models (LLMs) on code-related tasks has shown the potential of fully automated software development. In light of this, we introduce a new software engineering task, namely Natural Language to code Repository (NL2Repo). This task aims to generate an entire code repository from its natural language requirements. To address this task, we propose a simple yet effective framework CodeS, which decomposes NL2Repo into multiple sub-tasks by a multi-layer sketch. Specifically, CodeS includes three modules: RepoSketcher, FileSketcher, and SketchFiller. RepoSketcher first generates a repository's directory structure for given requirements; FileSketcher then generates a file sketch for each file in the generated structure; SketchFiller finally fills in the details for each function in the generated file sketch. To rigorously assess CodeS on the NL2Repo task, we carry out evaluations through both automated benchmarking and manual feedback analysis. For benchmark-based evaluation, we craft a repository-oriented benchmark, SketchEval, and design an evaluation metric, SketchBLEU. For feedback-based evaluation, we develop a VSCode plugin for CodeS and engage 30 participants in conducting empirical studies. Extensive experiments prove the effectiveness and practicality of CodeS on the NL2Repo task.
Improving Natural Language Capability of Code Large Language Model
Jan 25, 2024Code large language models (Code LLMs) have demonstrated remarkable performance in code generation. Nonetheless, most existing works focus on boosting code LLMs from the perspective of programming capabilities, while their natural language capabilities receive less attention. To fill this gap, we thus propose a novel framework, comprising two modules: AttentionExtractor, which is responsible for extracting key phrases from the user's natural language requirements, and AttentionCoder, which leverages these extracted phrases to generate target code to solve the requirement. This framework pioneers an innovative idea by seamlessly integrating code LLMs with traditional natural language processing tools. To validate the effectiveness of the framework, we craft a new code generation benchmark, called MultiNL-H, covering five natural languages. Extensive experimental results demonstrate the effectiveness of our proposed framework.
Can Programming Languages Boost Each Other via Instruction Tuning?
Sep 03, 2023
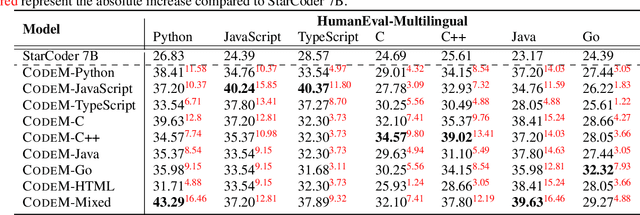


When human programmers have mastered a programming language, it would be easier when they learn a new programming language. In this report, we focus on exploring whether programming languages can boost each other during the instruction fine-tuning phase of code large language models. We conduct extensive experiments of 8 popular programming languages (Python, JavaScript, TypeScript, C, C++, Java, Go, HTML) on StarCoder. Results demonstrate that programming languages can significantly improve each other. For example, CodeM-Python 15B trained on Python is able to increase Java by an absolute 17.95% pass@1 on HumanEval-X. More surprisingly, we found that CodeM-HTML 7B trained on the HTML corpus can improve Java by an absolute 15.24% pass@1. Our training data is released at https://github.com/NL2Code/CodeM.
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
Jul 27, 2023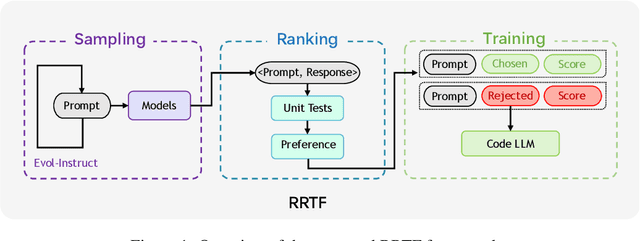

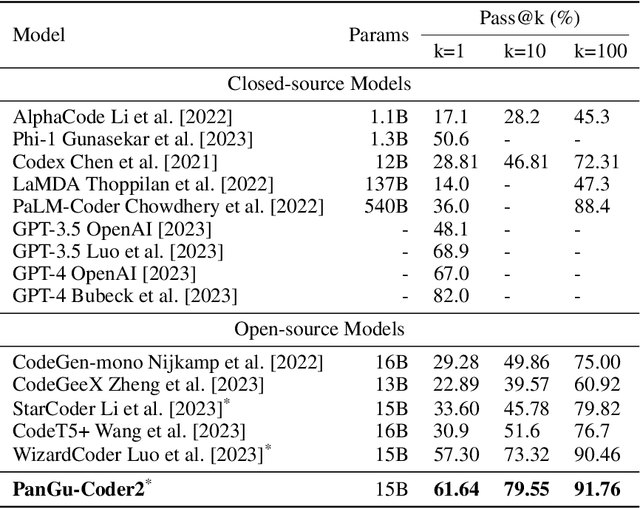
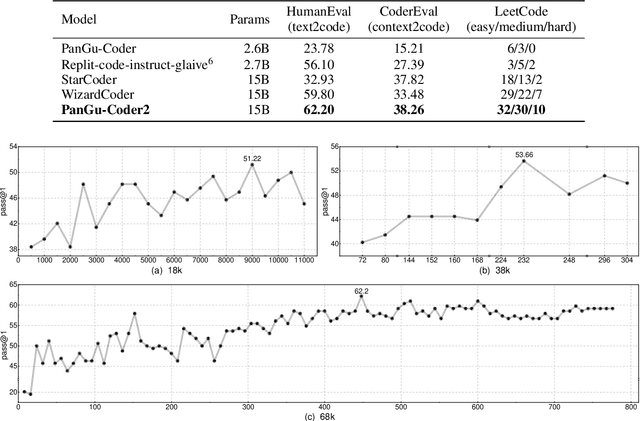
Large Language Models for Code (Code LLM) are flourishing. New and powerful models are released on a weekly basis, demonstrating remarkable performance on the code generation task. Various approaches have been proposed to boost the code generation performance of pre-trained Code LLMs, such as supervised fine-tuning, instruction tuning, reinforcement learning, etc. In this paper, we propose a novel RRTF (Rank Responses to align Test&Teacher Feedback) framework, which can effectively and efficiently boost pre-trained large language models for code generation. Under this framework, we present PanGu-Coder2, which achieves 62.20% pass@1 on the OpenAI HumanEval benchmark. Furthermore, through an extensive evaluation on CoderEval and LeetCode benchmarks, we show that PanGu-Coder2 consistently outperforms all previous Code LLMs.