 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Jun 04, 2026Despite generating increasingly photorealistic images, text-to-image (T2I) models still exhibit localized, subtle, and structurally complex failures. Diagnosing these failures requires instance-level feedback that answers where a defect occurs, what type it is, why it is defective, and its importance to overall image quality. While recent dense-feedback methods move beyond scalar supervision, their heatmap-centric representations still formulate diagnosis as pixel-field regression, making it difficult to localize variable-cardinality defects and bind semantic reasons to individual failures. To address this representation bottleneck, we propose Structured Defect Grounding (SDG), which casts T2I diagnosis as structured set prediction by modeling each defect as a (location, type, reason, importance) tuple. To make this formulation trainable and measurable, we introduce SDG-30K, a 30K-image dataset with box-grounded annotations across four modern T2I generators, together with a dedicated evaluation protocol, SDG-Eval. Building on this structured representation, we further present a diagnosis-to-alignment framework in which a Vision-Language Model (VLM) serves as the SDG detector, and BoxFlow-GRPO converts predicted defect sets into box-derived, importance-weighted spatial rewards for diffusion model alignment. Extensive experiments show that our SDG detector outperforms leading proprietary VLMs on structured defect grounding, while SDG-guided rewards consistently improve T2I alignment and support localized image refinement. These results establish SDG as a unified, instance-level interface for diagnosing, evaluating, and enhancing modern generative models.
Closed-Loop Hybrid Digital Twin Platform for Connected and Automated Vehicle Validation
May 19, 2026Comprehensive and efficient validation of connected and automated vehicles (CAVs) is critical prior to real-world deployment. While simulation-based testing offers scalability, existing approaches often lack seamless integration with real vehicles and field data, limiting their fidelity in capturing dynamic, real-world interactions. To bridge this gap, this paper proposes a novel real-time hybrid digital twin platform. Its core innovation lies in the tight coupling of a high-fidelity CARLA-SUMO co-simulation with a physical test site and vehicle via a low-latency Vehicle-to-Everything (V2X) communication link. A custom-developed middleware serves as the critical bridge, synchronizing a real CAV's kinematic state as a shadow vehicle in the simulation and translating virtual control commands into chassis-actuating Controller Area Network (CAN) messages for closed-loop control. Detailed implementation includes using photogrammetry for full-scale asset reconstruction and a cloud-edge collaborative architecture for scalable, multi-user operation. Experimental results demonstrate stable synchronization and effective closed-loop control with low latency, confirming the platform's practicality for multi-scenario CAV verification.
A Unified Pair-GRPO Family: From Implicit to Explicit Preference Constraints for Stable and General RL Alignment
May 07, 2026Large language model (LLM) alignment via reinforcement learning from human preferences (RLHF) suffers from unstable policy updates, ambiguous gradient directions, poor interpretability, and high gradient variance in mainstream pairwise preference learning paradigms. To systematically address these limitations, we establish a unified theoretical framework for preference-based RL optimization centered on the Pair-GRPO family, comprising two tightly coupled variants: Soft-Pair-GRPO and Hard-Pair-GRPO. Soft-Pair-GRPO is a minimal modification of Group Relative Policy Optimization (GRPO) that replaces group-normalized scalar rewards with binary pairwise preference rewards, retaining GRPO's clipped surrogate and KL-regularized structure. We prove a critical gradient equivalence theorem: under first-order Taylor expansion around the current policy, Soft-Pair-GRPO's gradient is a positive scalar multiple of standard GRPO's gradient, explaining its empirical stability despite discarding continuous reward magnitudes. Building on this foundation, we propose Hard-Pair-GRPO, an advanced variant introducing explicit local probability constraints and constrained KL-fitting optimization to further suppress gradient noise and global policy drift. We provide comprehensive theoretical guarantees for both variants--including monotonic policy improvement, deterministic gradient direction, gradient-variance reduction, and dynamic step-size convergence. Extensive experiments on standard LLM alignment benchmarks (HH-RLHF,UltraFeedback) and the MuJoCo continuous control task HalfCheetah-v4 demonstrate that our Pair-GRPO family consistently outperforms state-of-the-art baselines in alignment quality, human preference win rate, training stability, and generalization to general reinforcement learning. Ablation studies validate the critical contributions of each core component.
Joint Energy Management and Coordinated AIGC Workload Scheduling for Distributed Data Centers: A Diffusion-Aided Reward Shaping Approach
May 03, 2026Artificial intelligence-generated content (AIGC) has emerged as a transformative paradigm for automating the creation of diverse and customized content, giving rise to rapidly growing computational workloads in cloud data centers. It is imperative for AIGC service providers (ASPs) to strategically schedule AIGC workloads to reduce data center energy costs while guaranteeing high-quality content generation. However, the distinctive characteristics of AIGC services pose critical challenges, including model heterogeneity across ASPs, implicit service quality evaluation, and complex inference process control. To tackle these challenges, we propose a joint energy management and coordinated AIGC workload scheduling framework, which introduces an explicit mathematical characterization of service quality to promote both job transfer among ASPs and fine-grained inference process configuration. Moreover, various energy resources within data centers are jointly considered to enhance power usage flexibility. Subsequently, a system utility maximization problem is formulated to balance AIGC service revenue with operational penalties and costs. Nevertheless, the strong coupling among job scheduling decisions induces severe reward sparsity, which limits the effectiveness of existing deep reinforcement learning (DRL) algorithms. To address this issue, we develop a diffusion model-aided reward shaping approach to synthesize complementary reward signals through a multi-step denoising process. This approach is seamlessly integrated with DRL to enable efficient learning of scheduling policies under sparse environmental feedback. Experiments based on real-world models and datasets demonstrate that our scheme effectively accommodates electricity price fluctuations and AIGC model heterogeneity, while achieving superior learning convergence and system utility compared with benchmark methods.
FDeID-Toolbox: Face De-Identification Toolbox
Mar 13, 2026Face de-identification (FDeID) aims to remove personally identifiable information from facial images while preserving task-relevant utility attributes such as age, gender, and expression. It is critical for privacy-preserving computer vision, yet the field suffers from fragmented implementations, inconsistent evaluation protocols, and incomparable results across studies. These challenges stem from the inherent complexity of the task: FDeID spans multiple downstream applications (e.g., age estimation, gender recognition, expression analysis) and requires evaluation across three dimensions (e.g., privacy protection, utility preservation, and visual quality), making existing codebases difficult to use and extend. To address these issues, we present FDeID-Toolbox, a comprehensive toolbox designed for reproducible FDeID research. Our toolbox features a modular architecture comprising four core components: (1) standardized data loaders for mainstream benchmark datasets, (2) unified method implementations spanning classical approaches to SOTA generative models, (3) flexible inference pipelines, and (4) systematic evaluation protocols covering privacy, utility, and quality metrics. Through experiments, we demonstrate that FDeID-Toolbox enables fair and reproducible comparison of diverse FDeID methods under consistent conditions.
Enhancing Geometric Perception in VLMs via Translator-Guided Reinforcement Learning
Feb 26, 2026Vision-language models (VLMs) often struggle with geometric reasoning due to their limited perception of fundamental diagram elements. To tackle this challenge, we introduce GeoPerceive, a benchmark comprising diagram instances paired with domain-specific language (DSL) representations, along with an efficient automatic data generation pipeline. This design enables the isolated evaluation of geometric perception independently from reasoning. To exploit the data provided by GeoPerceive for enhancing the geometric perception capabilities of VLMs, we propose GeoDPO, a translator-guided reinforcement learning (RL) framework. GeoDPO employs an NL-to-DSL translator, which is trained on synthetic pairs generated by the data engine of GeoPerceive, to bridge natural language and DSL. This translator facilitates the computation of fine-grained, DSL-level scores, which serve as reward signals in reinforcement learning. We assess GeoDPO on both in-domain and out-of-domain datasets, spanning tasks in geometric perception as well as downstream reasoning. Experimental results demonstrate that, while supervised fine-tuning (SFT) offers only marginal improvements and may even impair performance in out-of-domain scenarios, GeoDPO achieves substantial gains: $+26.5\%$ on in-domain data, $+8.0\%$ on out-of-domain data, and $+39.0\%$ on downstream reasoning tasks. These findings underscore the superior performance and generalization ability of GeoDPO over SFT. All codes are released at https://github.com/Longin-Yu/GeoPerceive to ensure reproducibility.
GUI-GENESIS: Automated Synthesis of Efficient Environments with Verifiable Rewards for GUI Agent Post-Training
Feb 15, 2026Post-training GUI agents in interactive environments is critical for developing generalization and long-horizon planning capabilities. However, training on real-world applications is hindered by high latency, poor reproducibility, and unverifiable rewards relying on noisy visual proxies. To address the limitations, we present GUI-GENESIS, the first framework to automatically synthesize efficient GUI training environments with verifiable rewards. GUI-GENESIS reconstructs real-world applications into lightweight web environments using multimodal code models and equips them with code-native rewards, executable assertions that provide deterministic reward signals and eliminate visual estimation noise. Extensive experiments show that GUI-GENESIS reduces environment latency by 10 times and costs by over $28,000 per epoch compared to training on real applications. Notably, agents trained with GUI-GENESIS outperform the base model by 14.54% and even real-world RL baselines by 3.27% on held-out real-world tasks. Finally, we observe that models can synthesize environments they cannot yet solve, highlighting a pathway for self-improving agents.
AfriqueLLM: How Data Mixing and Model Architecture Impact Continued Pre-training for African Languages
Jan 10, 2026Large language models (LLMs) are increasingly multilingual, yet open models continue to underperform relative to proprietary systems, with the gap most pronounced for African languages. Continued pre-training (CPT) offers a practical route to language adaptation, but improvements on demanding capabilities such as mathematical reasoning often remain limited. This limitation is driven in part by the uneven domain coverage and missing task-relevant knowledge that characterize many low-resource language corpora. We present \texttt{AfriqueLLM}, a suite of open LLMs adapted to 20 African languages through CPT on 26B tokens. We perform a comprehensive empirical study across five base models spanning sizes and architectures, including Llama 3.1, Gemma 3, and Qwen 3, and systematically analyze how CPT data composition shapes downstream performance. In particular, we vary mixtures that include math, code, and synthetic translated data, and evaluate the resulting models on a range of multilingual benchmarks. Our results identify data composition as the primary driver of CPT gains. Adding math, code, and synthetic translated data yields consistent improvements, including on reasoning-oriented evaluations. Within a fixed architecture, larger models typically improve performance, but architectural choices dominate scale when comparing across model families. Moreover, strong multilingual performance in the base model does not reliably predict post-CPT outcomes; robust architectures coupled with task-aligned data provide a more dependable recipe. Finally, our best models improve long-context performance, including document-level translation. Models have been released on [Huggingface](https://huggingface.co/collections/McGill-NLP/afriquellm).
InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Jan 06, 2026Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.
AI Code in the Wild: Measuring Security Risks and Ecosystem Shifts of AI-Generated Code in Modern Software
Dec 21, 2025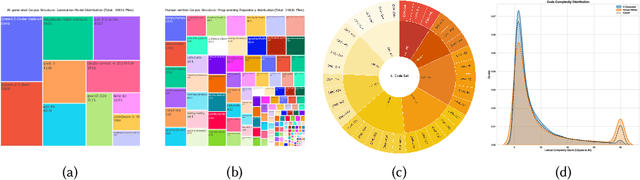
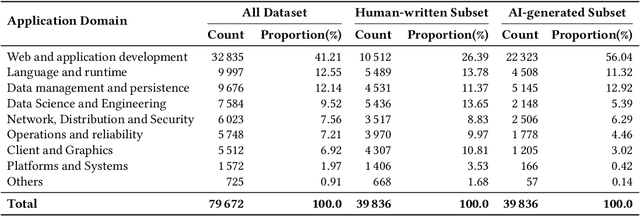
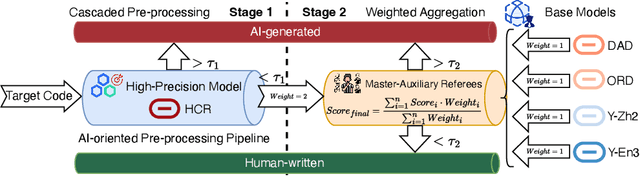
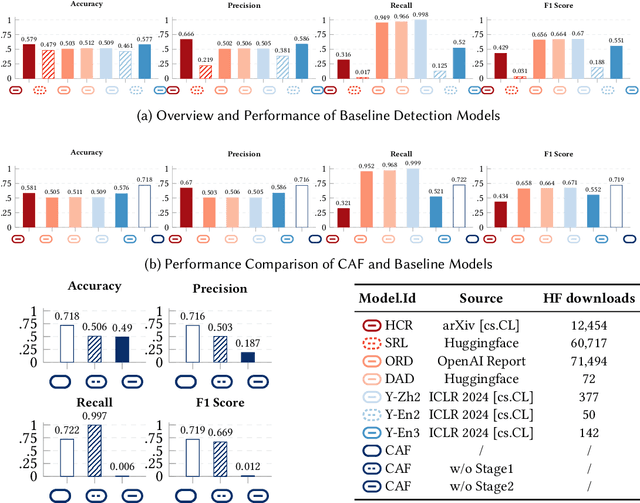
Large language models (LLMs) for code generation are becoming integral to modern software development, but their real-world prevalence and security impact remain poorly understood. We present the first large-scale empirical study of AI-generated code (AIGCode) in the wild. We build a high-precision detection pipeline and a representative benchmark to distinguish AIGCode from human-written code, and apply them to (i) development commits from the top 1,000 GitHub repositories (2022-2025) and (ii) 7,000+ recent CVE-linked code changes. This lets us label commits, files, and functions along a human/AI axis and trace how AIGCode moves through projects and vulnerability life cycles. Our measurements show three ecological patterns. First, AIGCode is already a substantial fraction of new code, but adoption is structured: AI concentrates in glue code, tests, refactoring, documentation, and other boilerplate, while core logic and security-critical configurations remain mostly human-written. Second, adoption has security consequences: some CWE families are overrepresented in AI-tagged code, and near-identical insecure templates recur across unrelated projects, suggesting "AI-induced vulnerabilities" propagated by shared models rather than shared maintainers. Third, in human-AI edit chains, AI introduces high-throughput changes while humans act as security gatekeepers; when review is shallow, AI-introduced defects persist longer, remain exposed on network-accessible surfaces, and spread to more files and repositories. We will open-source the complete dataset and release analysis artifacts and fine-grained documentation of our methodology and findings.