 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppForge: From Assistant to Independent Developer - Are GPTs Ready for Software Development?
Oct 09, 2025



Large language models (LLMs) have demonstrated remarkable capability in function-level code generation tasks. Unlike isolated functions, real-world applications demand reasoning over the entire software system: developers must orchestrate how different components interact, maintain consistency across states over time, and ensure the application behaves correctly within the lifecycle and framework constraints. Yet, no existing benchmark adequately evaluates whether LLMs can bridge this gap and construct entire software systems from scratch. To address this gap, we propose APPFORGE, a benchmark consisting of 101 software development problems drawn from real-world Android apps. Given a natural language specification detailing the app functionality, a language model is tasked with implementing the functionality into an Android app from scratch. Developing an Android app from scratch requires understanding and coordinating app states, lifecycle management, and asynchronous operations, calling for LLMs to generate context-aware, robust, and maintainable code. To construct APPFORGE, we design a multi-agent system to automatically summarize the main functionalities from app documents and navigate the app to synthesize test cases validating the functional correctness of app implementation. Following rigorous manual verification by Android development experts, APPFORGE incorporates the test cases within an automated evaluation framework that enables reproducible assessment without human intervention, making it easily adoptable for future research. Our evaluation on 12 flagship LLMs show that all evaluated models achieve low effectiveness, with the best-performing model (GPT-5) developing only 18.8% functionally correct applications, highlighting fundamental limitations in current models' ability to handle complex, multi-component software engineering challenges.
Benchmarking Large Language Models via Random Variables
Jan 20, 2025With the continuous advancement of large language models (LLMs) in mathematical reasoning, evaluating their performance in this domain has become a prominent research focus. Recent studies have raised concerns about the reliability of current mathematical benchmarks, highlighting issues such as simplistic design and potential data leakage. Therefore, creating a reliable benchmark that effectively evaluates the genuine capabilities of LLMs in mathematical reasoning remains a significant challenge. To address this, we propose RV-Bench, a framework for Benchmarking LLMs via Random Variables in mathematical reasoning. Specifically, the background content of a random variable question (RV question) mirrors the original problem in existing standard benchmarks, but the variable combinations are randomized into different values. LLMs must fully understand the problem-solving process for the original problem to correctly answer RV questions with various combinations of variable values. As a result, the LLM's genuine capability in mathematical reasoning is reflected by its accuracy on RV-Bench. Extensive experiments are conducted with 29 representative LLMs across 900+ RV questions. A leaderboard for RV-Bench ranks the genuine capability of these LLMs. Further analysis of accuracy dropping indicates that current LLMs still struggle with complex mathematical reasoning problems.
Data and System Perspectives of Sustainable Artificial Intelligence
Jan 13, 2025Sustainable AI is a subfield of AI for concerning developing and using AI systems in ways of aiming to reduce environmental impact and achieve sustainability. Sustainable AI is increasingly important given that training of and inference with AI models such as large langrage models are consuming a large amount of computing power. In this article, we discuss current issues, opportunities and example solutions for addressing these issues, and future challenges to tackle, from the data and system perspectives, related to data acquisition, data processing, and AI model training and inference.
Unconstrained Model Merging for Enhanced LLM Reasoning
Oct 17, 2024



Recent advancements in building domain-specific large language models (LLMs) have shown remarkable success, especially in tasks requiring reasoning abilities like logical inference over complex relationships and multi-step problem solving. However, creating a powerful all-in-one LLM remains challenging due to the need for proprietary data and vast computational resources. As a resource-friendly alternative, we explore the potential of merging multiple expert models into a single LLM. Existing studies on model merging mainly focus on generalist LLMs instead of domain experts, or the LLMs under the same architecture and size. In this work, we propose an unconstrained model merging framework that accommodates both homogeneous and heterogeneous model architectures with a focus on reasoning tasks. A fine-grained layer-wise weight merging strategy is designed for homogeneous models merging, while heterogeneous model merging is built upon the probabilistic distribution knowledge derived from instruction-response fine-tuning data. Across 7 benchmarks and 9 reasoning-optimized LLMs, we reveal key findings that combinatorial reasoning emerges from merging which surpasses simple additive effects. We propose that unconstrained model merging could serve as a foundation for decentralized LLMs, marking a notable progression from the existing centralized LLM framework. This evolution could enhance wider participation and stimulate additional advancement in the field of artificial intelligence, effectively addressing the constraints posed by centralized models.
Collapsed Language Models Promote Fairness
Oct 06, 2024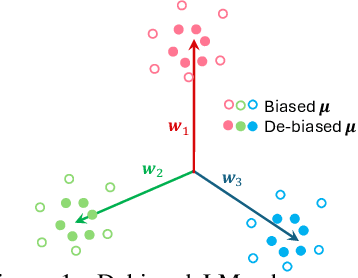
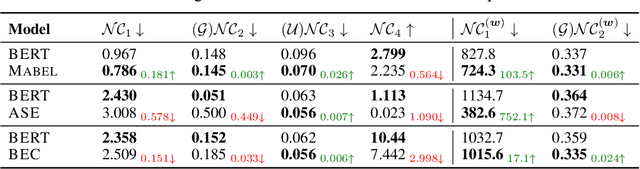
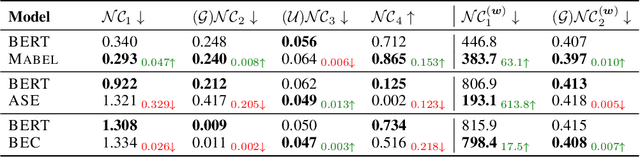
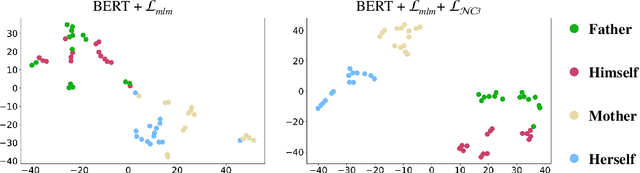
To mitigate societal biases implicitly encoded in recent successful pretrained language models, a diverse array of approaches have been proposed to encourage model fairness, focusing on prompting, data augmentation, regularized fine-tuning, and more. Despite the development, it is nontrivial to reach a principled understanding of fairness and an effective algorithm that can consistently debias language models. In this work, by rigorous evaluations of Neural Collapse -- a learning phenomenon happen in last-layer representations and classifiers in deep networks -- on fairness-related words, we find that debiased language models exhibit collapsed alignment between token representations and word embeddings. More importantly, this observation inspires us to design a principled fine-tuning method that can effectively improve fairness in a wide range of debiasing methods, while still preserving the performance of language models on standard natural language understanding tasks. We attach our code at https://anonymous.4open.science/r/Fairness_NC-457E .
SoccerNet 2024 Challenges Results
Sep 16, 2024

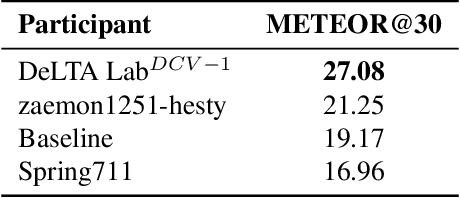
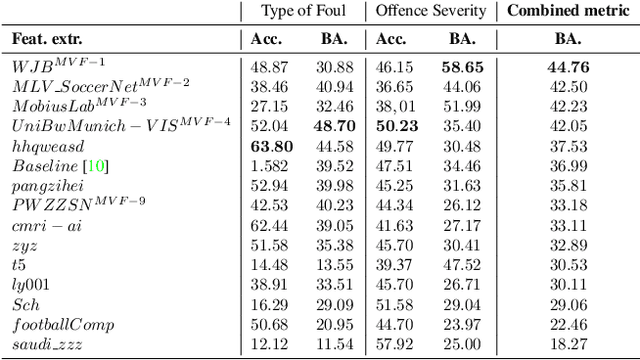
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Effects of Exponential Gaussian Distribution on (Double Sampling) Randomized Smoothing
Jun 04, 2024

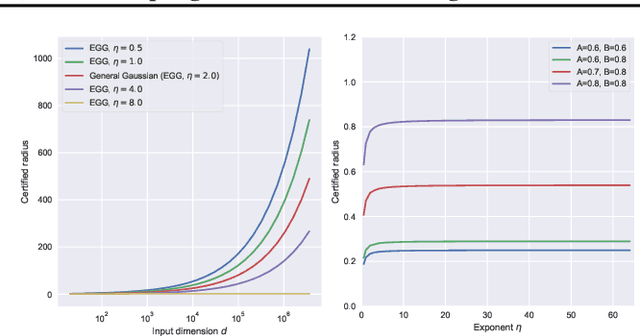

Randomized Smoothing (RS) is currently a scalable certified defense method providing robustness certification against adversarial examples. Although significant progress has been achieved in providing defenses against $\ell_p$ adversaries, the interaction between the smoothing distribution and the robustness certification still remains vague. In this work, we comprehensively study the effect of two families of distributions, named Exponential Standard Gaussian (ESG) and Exponential General Gaussian (EGG) distributions, on Randomized Smoothing and Double Sampling Randomized Smoothing (DSRS). We derive an analytic formula for ESG's certified radius, which converges to the origin formula of RS as the dimension $d$ increases. Additionally, we prove that EGG can provide tighter constant factors than DSRS in providing $\Omega(\sqrt{d})$ lower bounds of $\ell_2$ certified radius, and thus further addresses the curse of dimensionality in RS. Our experiments on real-world datasets confirm our theoretical analysis of the ESG distributions, that they provide almost the same certification under different exponents $\eta$ for both RS and DSRS. In addition, EGG
COLEP: Certifiably Robust Learning-Reasoning Conformal Prediction via Probabilistic Circuits
Mar 17, 2024



Conformal prediction has shown spurring performance in constructing statistically rigorous prediction sets for arbitrary black-box machine learning models, assuming the data is exchangeable. However, even small adversarial perturbations during the inference can violate the exchangeability assumption, challenge the coverage guarantees, and result in a subsequent decline in empirical coverage. In this work, we propose a certifiably robust learning-reasoning conformal prediction framework (COLEP) via probabilistic circuits, which comprise a data-driven learning component that trains statistical models to learn different semantic concepts, and a reasoning component that encodes knowledge and characterizes the relationships among the trained models for logic reasoning. To achieve exact and efficient reasoning, we employ probabilistic circuits (PCs) within the reasoning component. Theoretically, we provide end-to-end certification of prediction coverage for COLEP in the presence of bounded adversarial perturbations. We also provide certified coverage considering the finite size of the calibration set. Furthermore, we prove that COLEP achieves higher prediction coverage and accuracy over a single model as long as the utilities of knowledge models are non-trivial. Empirically, we show the validity and tightness of our certified coverage, demonstrating the robust conformal prediction of COLEP on various datasets, including GTSRB, CIFAR10, and AwA2. We show that COLEP achieves up to 12% improvement in certified coverage on GTSRB, 9% on CIFAR-10, and 14% on AwA2.
COMMIT: Certifying Robustness of Multi-Sensor Fusion Systems against Semantic Attacks
Mar 04, 2024



Multi-sensor fusion systems (MSFs) play a vital role as the perception module in modern autonomous vehicles (AVs). Therefore, ensuring their robustness against common and realistic adversarial semantic transformations, such as rotation and shifting in the physical world, is crucial for the safety of AVs. While empirical evidence suggests that MSFs exhibit improved robustness compared to single-modal models, they are still vulnerable to adversarial semantic transformations. Despite the proposal of empirical defenses, several works show that these defenses can be attacked again by new adaptive attacks. So far, there is no certified defense proposed for MSFs. In this work, we propose the first robustness certification framework COMMIT certify robustness of multi-sensor fusion systems against semantic attacks. In particular, we propose a practical anisotropic noise mechanism that leverages randomized smoothing with multi-modal data and performs a grid-based splitting method to characterize complex semantic transformations. We also propose efficient algorithms to compute the certification in terms of object detection accuracy and IoU for large-scale MSF models. Empirically, we evaluate the efficacy of COMMIT in different settings and provide a comprehensive benchmark of certified robustness for different MSF models using the CARLA simulation platform. We show that the certification for MSF models is at most 48.39% higher than that of single-modal models, which validates the advantages of MSF models. We believe our certification framework and benchmark will contribute an important step towards certifiably robust AVs in practice.
Pixel-wise Smoothing for Certified Robustness against Camera Motion Perturbations
Sep 22, 2023



In recent years, computer vision has made remarkable advancements in autonomous driving and robotics. However, it has been observed that deep learning-based visual perception models lack robustness when faced with camera motion perturbations. The current certification process for assessing robustness is costly and time-consuming due to the extensive number of image projections required for Monte Carlo sampling in the 3D camera motion space. To address these challenges, we present a novel, efficient, and practical framework for certifying the robustness of 3D-2D projective transformations against camera motion perturbations. Our approach leverages a smoothing distribution over the 2D pixel space instead of in the 3D physical space, eliminating the need for costly camera motion sampling and significantly enhancing the efficiency of robustness certifications. With the pixel-wise smoothed classifier, we are able to fully upper bound the projection errors using a technique of uniform partitioning in camera motion space. Additionally, we extend our certification framework to a more general scenario where only a single-frame point cloud is required in the projection oracle. This is achieved by deriving Lipschitz-based approximated partition intervals. Through extensive experimentation, we validate the trade-off between effectiveness and efficiency enabled by our proposed method. Remarkably, our approach achieves approximately 80% certified accuracy while utilizing only 30% of the projected image frames.