 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
Feb 04, 2026Large language model (LLM) inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization (PTQ) maintains high fidelity at 4-bit, it deteriorates at 2-3 bits. Fundamentally, existing methods enforce a shape-invariant quantization grid (e.g., the fixed uniform intervals of UINT2) for each group, severely restricting the feasible set for error minimization. To address this, we propose Bit-Plane Decomposition Quantization (BPDQ), which constructs a variable quantization grid via bit-planes and scalar coefficients, and iteratively refines them using approximate second-order information while progressively compensating quantization errors to minimize output discrepancy. In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy (vs. 90.83% at 16-bit). Moreover, we provide theoretical analysis showing that the variable grid expands the feasible set, and that the quantization process consistently aligns with the optimization objective in Hessian-induced geometry. Code: github.com/KingdalfGoodman/BPDQ.
Canonical Intermediate Representation for LLM-based optimization problem formulation and code generation
Feb 02, 2026Automatically formulating optimization models from natural language descriptions is a growing focus in operations research, yet current LLM-based approaches struggle with the composite constraints and appropriate modeling paradigms required by complex operational rules. To address this, we introduce the Canonical Intermediate Representation (CIR): a schema that LLMs explicitly generate between problem descriptions and optimization models. CIR encodes the semantics of operational rules through constraint archetypes and candidate modeling paradigms, thereby decoupling rule logic from its mathematical instantiation. Upon a newly generated CIR knowledge base, we develop the rule-to-constraint (R2C) framework, a multi-agent pipeline that parses problem texts, synthesizes CIR implementations by retrieving domain knowledge, and instantiates optimization models. To systematically evaluate rule-to-constraint reasoning, we test R2C on our newly constructed benchmark featuring rich operational rules, and benchmarks from prior work. Extensive experiments show that R2C achieves state-of-the-art accuracy on the proposed benchmark (47.2% Accuracy Rate). On established benchmarks from the literature, R2C delivers highly competitive results, approaching the performance of proprietary models (e.g., GPT-5). Moreover, with a reflection mechanism, R2C achieves further gains and sets new best-reported results on some benchmarks.
InfiAgent: An Infinite-Horizon Framework for General-Purpose Autonomous Agents
Jan 06, 2026LLM agents can reason and use tools, but they often break down on long-horizon tasks due to unbounded context growth and accumulated errors. Common remedies such as context compression or retrieval-augmented prompting introduce trade-offs between information fidelity and reasoning stability. We present InfiAgent, a general-purpose framework that keeps the agent's reasoning context strictly bounded regardless of task duration by externalizing persistent state into a file-centric state abstraction. At each step, the agent reconstructs context from a workspace state snapshot plus a fixed window of recent actions. Experiments on DeepResearch and an 80-paper literature review task show that, without task-specific fine-tuning, InfiAgent with a 20B open-source model is competitive with larger proprietary systems and maintains substantially higher long-horizon coverage than context-centric baselines. These results support explicit state externalization as a practical foundation for stable long-horizon agents. Github Repo:https://github.com/ChenglinPoly/infiAgent
InfiMed-Foundation: Pioneering Advanced Multimodal Medical Models with Compute-Efficient Pre-Training and Multi-Stage Fine-Tuning
Sep 26, 2025



Multimodal large language models (MLLMs) have shown remarkable potential in various domains, yet their application in the medical field is hindered by several challenges. General-purpose MLLMs often lack the specialized knowledge required for medical tasks, leading to uncertain or hallucinatory responses. Knowledge distillation from advanced models struggles to capture domain-specific expertise in radiology and pharmacology. Additionally, the computational cost of continual pretraining with large-scale medical data poses significant efficiency challenges. To address these issues, we propose InfiMed-Foundation-1.7B and InfiMed-Foundation-4B, two medical-specific MLLMs designed to deliver state-of-the-art performance in medical applications. We combined high-quality general-purpose and medical multimodal data and proposed a novel five-dimensional quality assessment framework to curate high-quality multimodal medical datasets. We employ low-to-high image resolution and multimodal sequence packing to enhance training efficiency, enabling the integration of extensive medical data. Furthermore, a three-stage supervised fine-tuning process ensures effective knowledge extraction for complex medical tasks. Evaluated on the MedEvalKit framework, InfiMed-Foundation-1.7B outperforms Qwen2.5VL-3B, while InfiMed-Foundation-4B surpasses HuatuoGPT-V-7B and MedGemma-27B-IT, demonstrating superior performance in medical visual question answering and diagnostic tasks. By addressing key challenges in data quality, training efficiency, and domain-specific knowledge extraction, our work paves the way for more reliable and effective AI-driven solutions in healthcare. InfiMed-Foundation-4B model is available at \href{https://huggingface.co/InfiX-ai/InfiMed-Foundation-4B}{InfiMed-Foundation-4B}.
InfiAgent: Self-Evolving Pyramid Agent Framework for Infinite Scenarios
Sep 26, 2025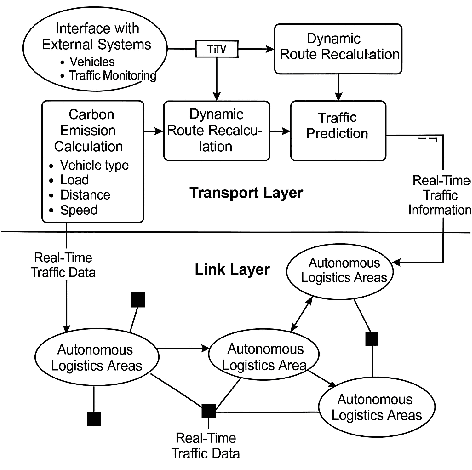
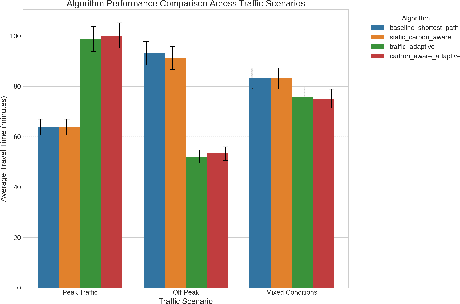
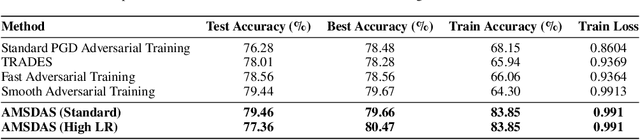
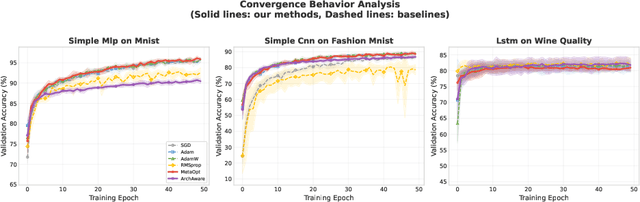
Large Language Model (LLM) agents have demonstrated remarkable capabilities in organizing and executing complex tasks, and many such agents are now widely used in various application scenarios. However, developing these agents requires carefully designed workflows, carefully crafted prompts, and iterative tuning, which requires LLM techniques and domain-specific expertise. These hand-crafted limitations hinder the scalability and cost-effectiveness of LLM agents across a wide range of industries. To address these challenges, we propose \textbf{InfiAgent}, a Pyramid-like DAG-based Multi-Agent Framework that can be applied to \textbf{infi}nite scenarios, which introduces several key innovations: a generalized "agent-as-a-tool" mechanism that automatically decomposes complex agents into hierarchical multi-agent systems; a dual-audit mechanism that ensures the quality and stability of task completion; an agent routing function that enables efficient task-agent matching; and an agent self-evolution mechanism that autonomously restructures the agent DAG based on new tasks, poor performance, or optimization opportunities. Furthermore, InfiAgent's atomic task design supports agent parallelism, significantly improving execution efficiency. This framework evolves into a versatile pyramid-like multi-agent system capable of solving a wide range of problems. Evaluations on multiple benchmarks demonstrate that InfiAgent achieves 9.9\% higher performance compared to ADAS (similar auto-generated agent framework), while a case study of the AI research assistant InfiHelper shows that it generates scientific papers that have received recognition from human reviewers at top-tier IEEE conferences.
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025



The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.
InfiAlign: A Scalable and Sample-Efficient Framework for Aligning LLMs to Enhance Reasoning Capabilities
Aug 07, 2025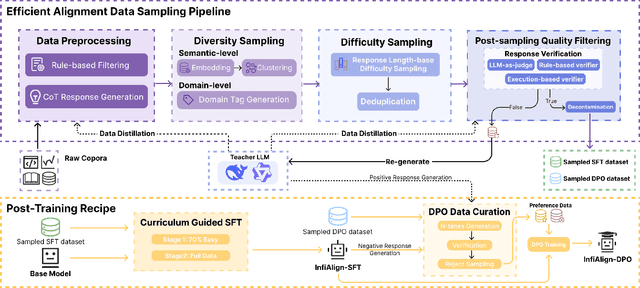
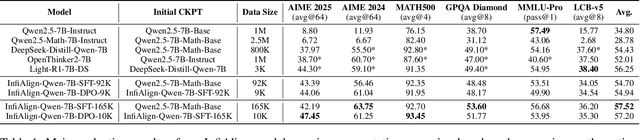
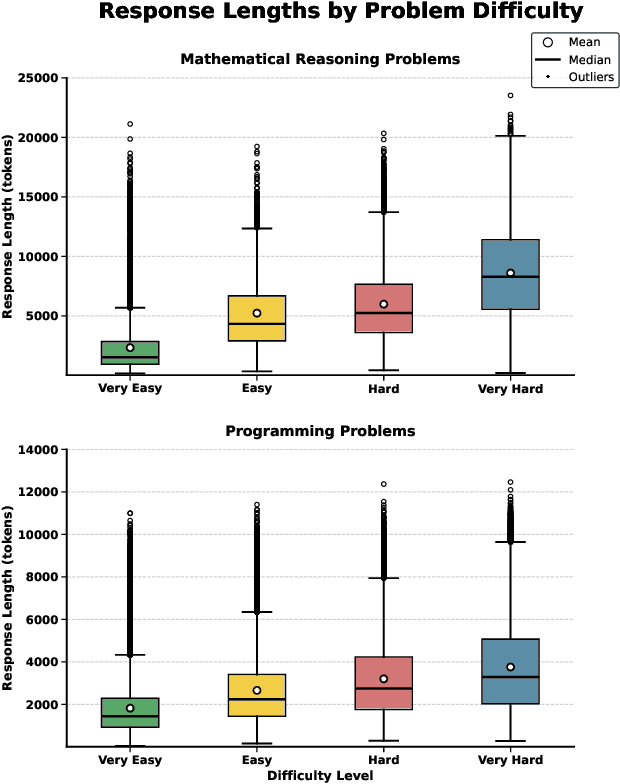
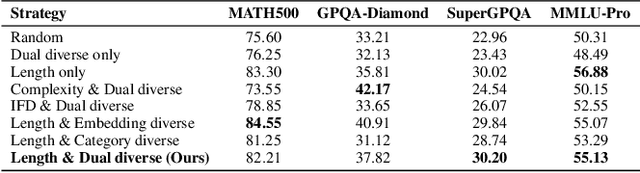
Large language models (LLMs) have exhibited impressive reasoning abilities on a wide range of complex tasks. However, enhancing these capabilities through post-training remains resource intensive, particularly in terms of data and computational cost. Although recent efforts have sought to improve sample efficiency through selective data curation, existing methods often rely on heuristic or task-specific strategies that hinder scalability. In this work, we introduce InfiAlign, a scalable and sample-efficient post-training framework that integrates supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to align LLMs for enhanced reasoning. At the core of InfiAlign is a robust data selection pipeline that automatically curates high-quality alignment data from open-source reasoning datasets using multidimensional quality metrics. This pipeline enables significant performance gains while drastically reducing data requirements and remains extensible to new data sources. When applied to the Qwen2.5-Math-7B-Base model, our SFT model achieves performance on par with DeepSeek-R1-Distill-Qwen-7B, while using only approximately 12% of the training data, and demonstrates strong generalization across diverse reasoning tasks. Additional improvements are obtained through the application of DPO, with particularly notable gains in mathematical reasoning tasks. The model achieves an average improvement of 3.89% on AIME 24/25 benchmarks. Our results highlight the effectiveness of combining principled data selection with full-stage post-training, offering a practical solution for aligning large reasoning models in a scalable and data-efficient manner. The model checkpoints are available at https://huggingface.co/InfiX-ai/InfiAlign-Qwen-7B-SFT.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025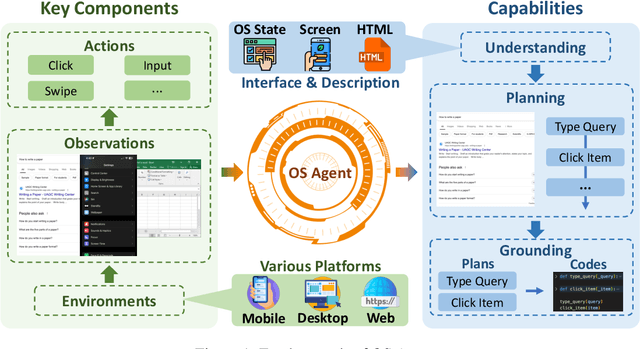
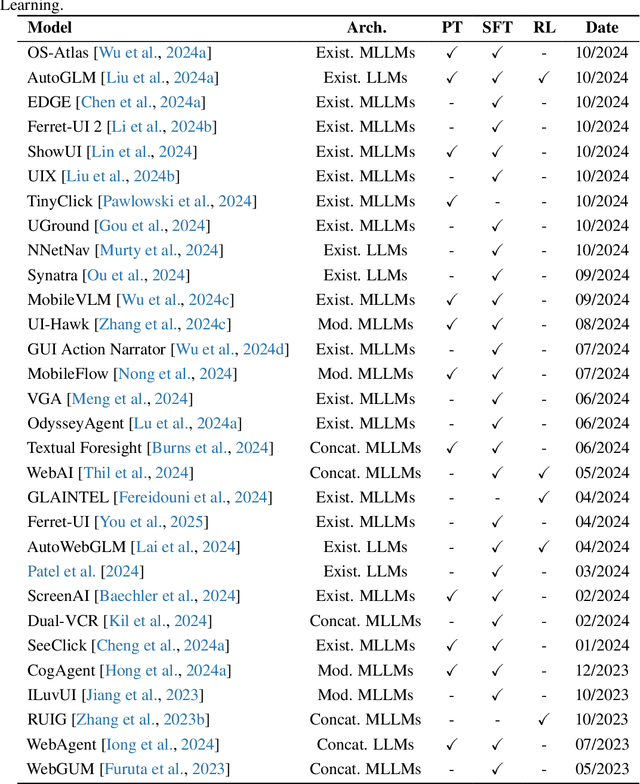
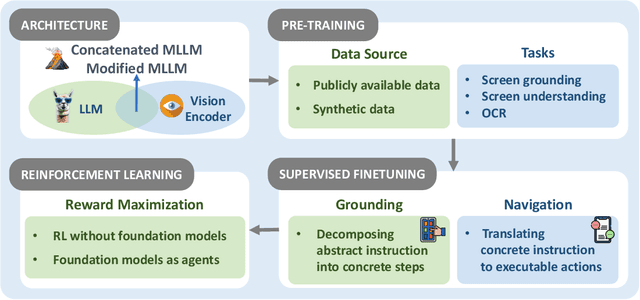
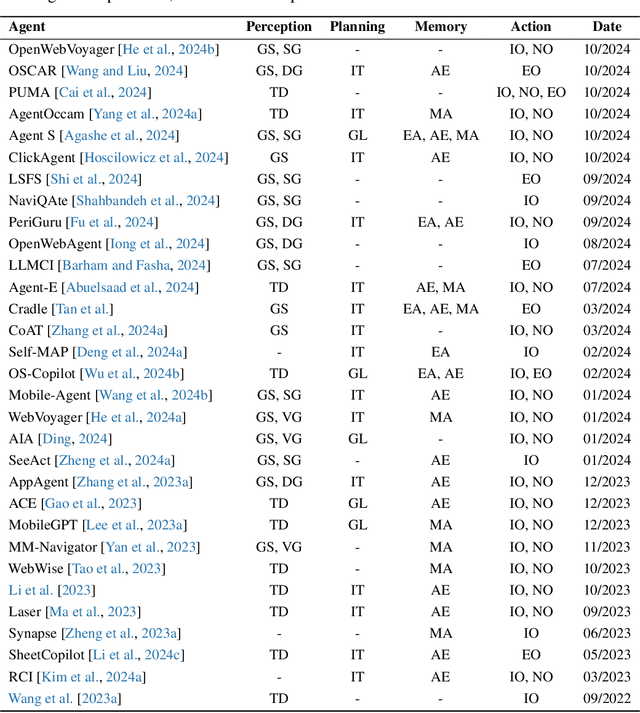
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
Infi-Med: Low-Resource Medical MLLMs with Robust Reasoning Evaluation
May 29, 2025
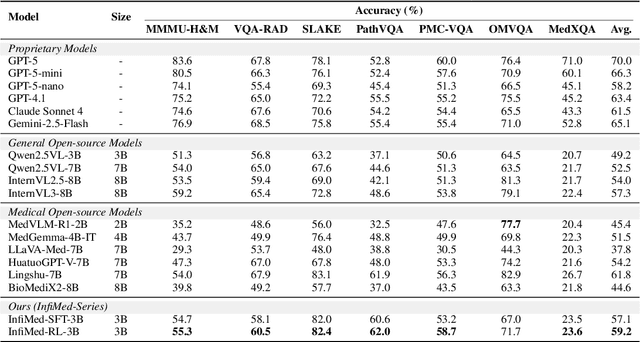
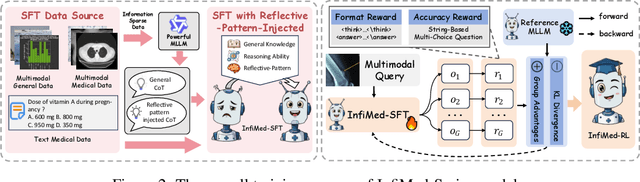
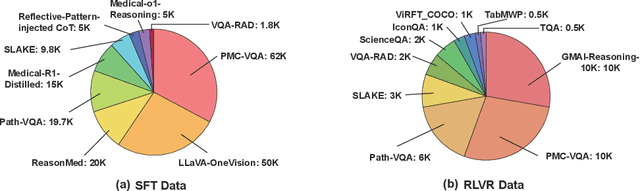
Multimodal large language models (MLLMs) have demonstrated promising prospects in healthcare, particularly for addressing complex medical tasks, supporting multidisciplinary treatment (MDT), and enabling personalized precision medicine. However, their practical deployment faces critical challenges in resource efficiency, diagnostic accuracy, clinical considerations, and ethical privacy. To address these limitations, we propose Infi-Med, a comprehensive framework for medical MLLMs that introduces three key innovations: (1) a resource-efficient approach through curating and constructing high-quality supervised fine-tuning (SFT) datasets with minimal sample requirements, with a forward-looking design that extends to both pretraining and posttraining phases; (2) enhanced multimodal reasoning capabilities for cross-modal integration and clinical task understanding; and (3) a systematic evaluation system that assesses model performance across medical modalities and task types. Our experiments demonstrate that Infi-Med achieves state-of-the-art (SOTA) performance in general medical reasoning while maintaining rapid adaptability to clinical scenarios. The framework establishes a solid foundation for deploying MLLMs in real-world healthcare settings by balancing model effectiveness with operational constraints.
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025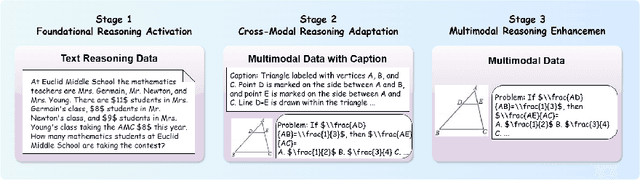
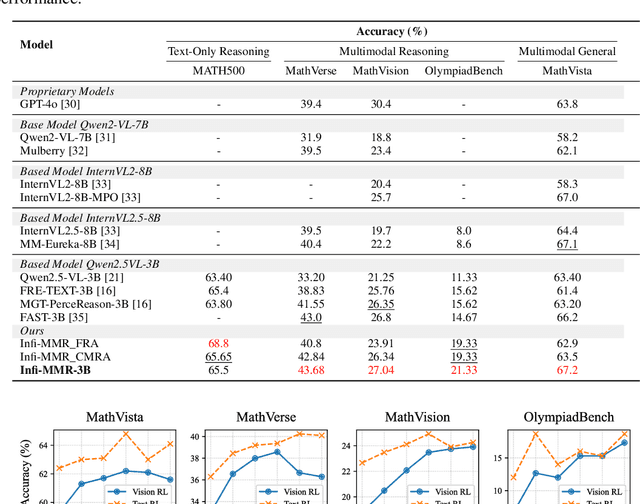
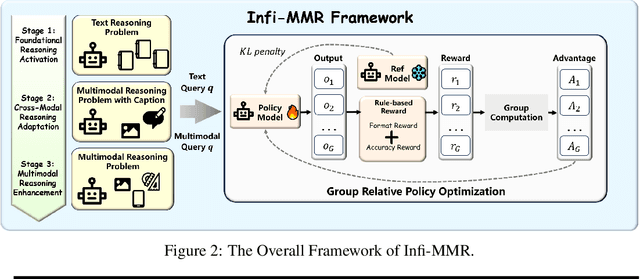
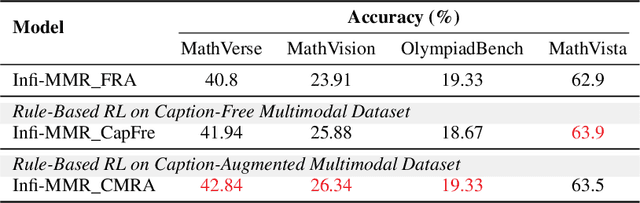
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).