 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
An Expert is Worth One Token: Synergizing Multiple Expert LLMs as Generalist via Expert Token Routing
Mar 25, 2024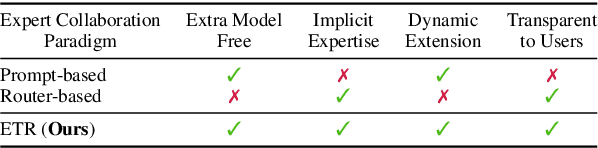
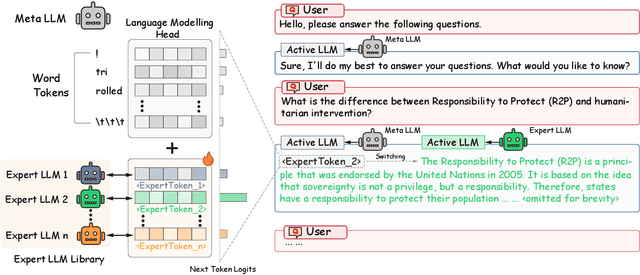
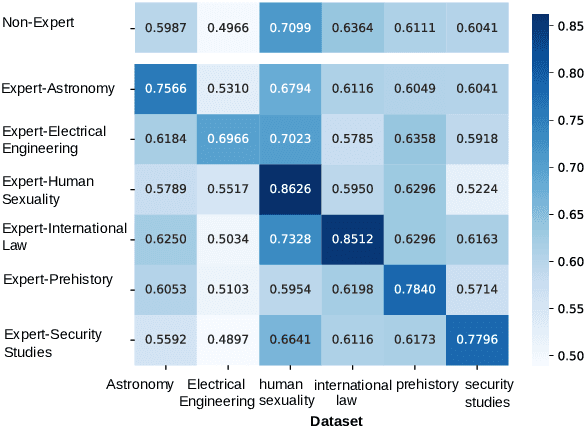
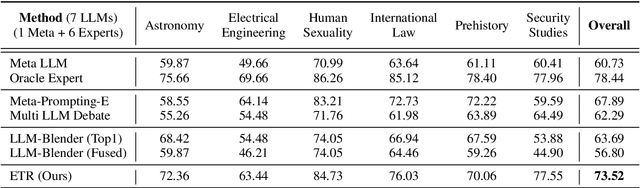
We present Expert-Token-Routing, a unified generalist framework that facilitates seamless integration of multiple expert LLMs. Our framework represents expert LLMs as special expert tokens within the vocabulary of a meta LLM. The meta LLM can route to an expert LLM like generating new tokens. Expert-Token-Routing not only supports learning the implicit expertise of expert LLMs from existing instruction dataset but also allows for dynamic extension of new expert LLMs in a plug-and-play manner. It also conceals the detailed collaboration process from the user's perspective, facilitating interaction as though it were a singular LLM. Our framework outperforms various existing multi-LLM collaboration paradigms across benchmarks that incorporate six diverse expert domains, demonstrating effectiveness and robustness in building generalist LLM system via synergizing multiple expert LLMs.
Can GNN be Good Adapter for LLMs?
Feb 20, 2024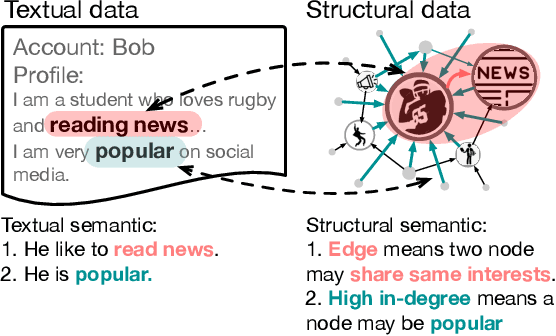
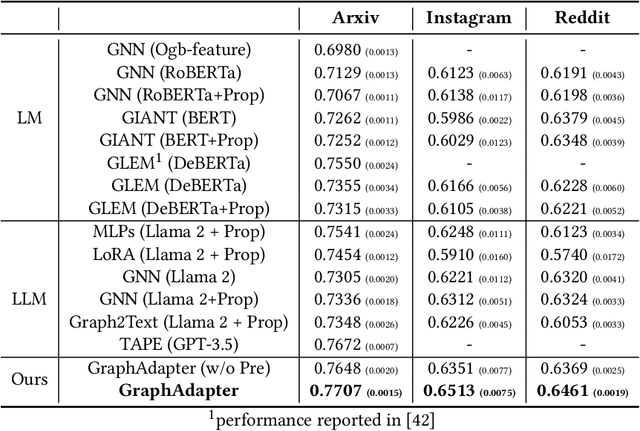
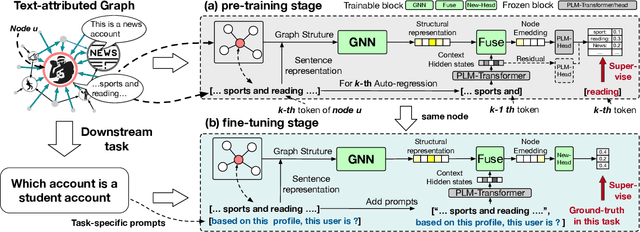

Recently, large language models (LLMs) have demonstrated superior capabilities in understanding and zero-shot learning on textual data, promising significant advances for many text-related domains. In the graph domain, various real-world scenarios also involve textual data, where tasks and node features can be described by text. These text-attributed graphs (TAGs) have broad applications in social media, recommendation systems, etc. Thus, this paper explores how to utilize LLMs to model TAGs. Previous methods for TAG modeling are based on million-scale LMs. When scaled up to billion-scale LLMs, they face huge challenges in computational costs. Additionally, they also ignore the zero-shot inference capabilities of LLMs. Therefore, we propose GraphAdapter, which uses a graph neural network (GNN) as an efficient adapter in collaboration with LLMs to tackle TAGs. In terms of efficiency, the GNN adapter introduces only a few trainable parameters and can be trained with low computation costs. The entire framework is trained using auto-regression on node text (next token prediction). Once trained, GraphAdapter can be seamlessly fine-tuned with task-specific prompts for various downstream tasks. Through extensive experiments across multiple real-world TAGs, GraphAdapter based on Llama 2 gains an average improvement of approximately 5\% in terms of node classification. Furthermore, GraphAdapter can also adapt to other language models, including RoBERTa, GPT-2. The promising results demonstrate that GNNs can serve as effective adapters for LLMs in TAG modeling.
One Graph Model for Cross-domain Dynamic Link Prediction
Feb 03, 2024



This work proposes DyExpert, a dynamic graph model for cross-domain link prediction. It can explicitly model historical evolving processes to learn the evolution pattern of a specific downstream graph and subsequently make pattern-specific link predictions. DyExpert adopts a decode-only transformer and is capable of efficiently parallel training and inference by \textit{conditioned link generation} that integrates both evolution modeling and link prediction. DyExpert is trained by extensive dynamic graphs across diverse domains, comprising 6M dynamic edges. Extensive experiments on eight untrained graphs demonstrate that DyExpert achieves state-of-the-art performance in cross-domain link prediction. Compared to the advanced baseline under the same setting, DyExpert achieves an average of 11.40% improvement Average Precision across eight graphs. More impressive, it surpasses the fully supervised performance of 8 advanced baselines on 6 untrained graphs.
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks
Jan 10, 2024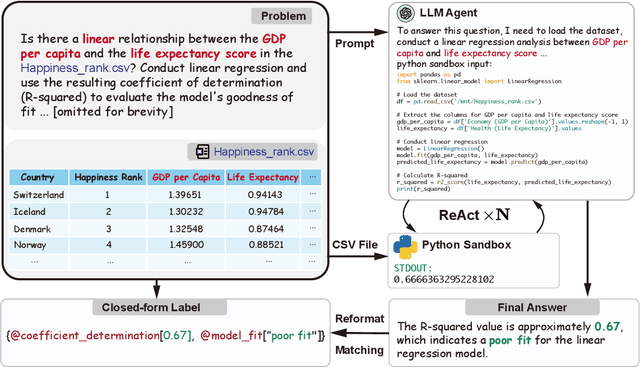

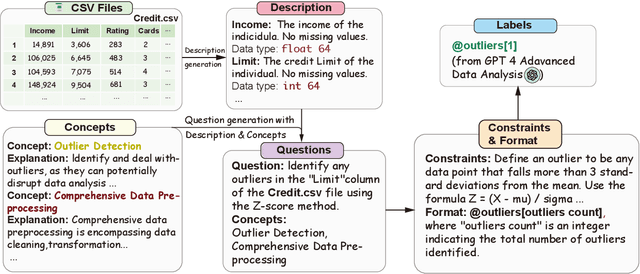

In this paper, we introduce "InfiAgent-DABench", the first benchmark specifically designed to evaluate LLM-based agents in data analysis tasks. This benchmark contains DAEval, a dataset consisting of 311 data analysis questions derived from 55 CSV files, and an agent framework to evaluate LLMs as data analysis agents. We adopt a format-prompting technique, ensuring questions to be closed-form that can be automatically evaluated. Our extensive benchmarking of 23 state-of-the-art LLMs uncovers the current challenges encountered in data analysis tasks. In addition, we have developed DAAgent, a specialized agent trained on instruction-tuning datasets. Evaluation datasets and toolkits for InfiAgent-DABench are released at https://github.com/InfiAgent/InfiAgent.
GraphLLM: Boosting Graph Reasoning Ability of Large Language Model
Oct 09, 2023



The advancement of Large Language Models (LLMs) has remarkably pushed the boundaries towards artificial general intelligence (AGI), with their exceptional ability on understanding diverse types of information, including but not limited to images and audio. Despite this progress, a critical gap remains in empowering LLMs to proficiently understand and reason on graph data. Recent studies underscore LLMs' underwhelming performance on fundamental graph reasoning tasks. In this paper, we endeavor to unearth the obstacles that impede LLMs in graph reasoning, pinpointing the common practice of converting graphs into natural language descriptions (Graph2Text) as a fundamental bottleneck. To overcome this impediment, we introduce GraphLLM, a pioneering end-to-end approach that synergistically integrates graph learning models with LLMs. This synergy equips LLMs with the ability to proficiently interpret and reason on graph data, harnessing the superior expressive power of graph learning models. Our empirical evaluations across four fundamental graph reasoning tasks validate the effectiveness of GraphLLM. The results exhibit a substantial average accuracy enhancement of 54.44%, alongside a noteworthy context reduction of 96.45% across various graph reasoning tasks.