 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Acoustic Model Architecture Optimization in Training for ASR
Jun 16, 2025Architecture design is inherently complex. Existing approaches rely on either handcrafted rules, which demand extensive empirical expertise, or automated methods like neural architecture search, which are computationally intensive. In this paper, we introduce DMAO, an architecture optimization framework that employs a grow-and-drop strategy to automatically reallocate parameters during training. This reallocation shifts resources from less-utilized areas to those parts of the model where they are most beneficial. Notably, DMAO only introduces negligible training overhead at a given model complexity. We evaluate DMAO through experiments with CTC on LibriSpeech, TED-LIUM-v2 and Switchboard datasets. The results show that, using the same amount of training resources, our proposed DMAO consistently improves WER by up to 6% relatively across various architectures, model sizes, and datasets. Furthermore, we analyze the pattern of parameter redistribution and uncover insightful findings.
Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning
Feb 12, 2025



Chain-of-Thought (CoT) prompting has emerged as a powerful technique for enhancing language model's reasoning capabilities. However, generating long and correct CoT trajectories is challenging. Recent studies have demonstrated that Looped Transformers possess remarkable length generalization capabilities, but their limited generality and adaptability prevent them from serving as an alternative to auto-regressive solutions. To better leverage the strengths of Looped Transformers, we propose RELAY (REasoning through Loop Alignment iterativelY). Specifically, we align the steps of Chain-of-Thought (CoT) reasoning with loop iterations and apply intermediate supervision during the training of Looped Transformers. This additional iteration-wise supervision not only preserves the Looped Transformer's ability for length generalization but also enables it to predict CoT reasoning steps for unseen data. Therefore, we leverage this Looped Transformer to generate accurate reasoning chains for complex problems that exceed the training length, which will then be used to fine-tune an auto-regressive model. We conduct extensive experiments, and the results demonstrate the effectiveness of our approach, with significant improvements in the performance of the auto-regressive model. Code will be released at https://github.com/qifanyu/RELAY.
Teaching Language Models to Critique via Reinforcement Learning
Feb 05, 2025



Teaching large language models (LLMs) to critique and refine their outputs is crucial for building systems that can iteratively improve, yet it is fundamentally limited by the ability to provide accurate judgments and actionable suggestions. In this work, we study LLM critics for code generation and propose $\texttt{CTRL}$, a framework for $\texttt{C}$ritic $\texttt{T}$raining via $\texttt{R}$einforcement $\texttt{L}$earning, which trains a critic model to generate feedback that maximizes correction performance for a fixed generator model without human supervision. Our results demonstrate that critics trained with $\texttt{CTRL}$ significantly enhance pass rates and mitigate compounding errors across both base and stronger generator models. Furthermore, we show that these critic models act as accurate generative reward models and enable test-time scaling through iterative critique-revision, achieving up to 106.1% relative improvements across challenging code generation benchmarks.
Efficient Supernet Training with Orthogonal Softmax for Scalable ASR Model Compression
Jan 31, 2025ASR systems are deployed across diverse environments, each with specific hardware constraints. We use supernet training to jointly train multiple encoders of varying sizes, enabling dynamic model size adjustment to fit hardware constraints without redundant training. Moreover, we introduce a novel method called OrthoSoftmax, which applies multiple orthogonal softmax functions to efficiently identify optimal subnets within the supernet, avoiding resource-intensive search. This approach also enables more flexible and precise subnet selection by allowing selection based on various criteria and levels of granularity. Our results with CTC on Librispeech and TED-LIUM-v2 show that FLOPs-aware component-wise selection achieves the best overall performance. With the same number of training updates from one single job, WERs for all model sizes are comparable to or slightly better than those of individually trained models. Furthermore, we analyze patterns in the selected components and reveal interesting insights.
A Unified Hyperparameter Optimization Pipeline for Transformer-Based Time Series Forecasting Models
Jan 02, 2025



Transformer-based models for time series forecasting (TSF) have attracted significant attention in recent years due to their effectiveness and versatility. However, these models often require extensive hyperparameter optimization (HPO) to achieve the best possible performance, and a unified pipeline for HPO in transformer-based TSF remains lacking. In this paper, we present one such pipeline and conduct extensive experiments on several state-of-the-art (SOTA) transformer-based TSF models. These experiments are conducted on standard benchmark datasets to evaluate and compare the performance of different models, generating practical insights and examples. Our pipeline is generalizable beyond transformer-based architectures and can be applied to other SOTA models, such as Mamba and TimeMixer, as demonstrated in our experiments. The goal of this work is to provide valuable guidance to both industry practitioners and academic researchers in efficiently identifying optimal hyperparameters suited to their specific domain applications. The code and complete experimental results are available on GitHub.
The Rise and Down of Babel Tower: Investigating the Evolution Process of Multilingual Code Large Language Model
Dec 10, 2024



Large language models (LLMs) have shown significant multilingual capabilities. However, the mechanisms underlying the development of these capabilities during pre-training are not well understood. In this paper, we use code LLMs as an experimental platform to explore the evolution of multilingual capabilities in LLMs during the pre-training process. Based on our observations, we propose the Babel Tower Hypothesis, which describes the entire process of LLMs acquiring new language capabilities. During the learning process, multiple languages initially share a single knowledge system dominated by the primary language and gradually develop language-specific knowledge systems. We then validate the above hypothesis by tracking the internal states of the LLMs through identifying working languages and language transferring neurons. Experimental results show that the internal state changes of the LLM are consistent with our Babel Tower Hypothesis. Building on these insights, we propose a novel method to construct an optimized pre-training corpus for multilingual code LLMs, which significantly outperforms LLMs trained on the original corpus. The proposed Babel Tower Hypothesis provides new insights into designing pre-training data distributions to achieve optimal multilingual capabilities in LLMs.
Why Does the Effective Context Length of LLMs Fall Short?
Oct 24, 2024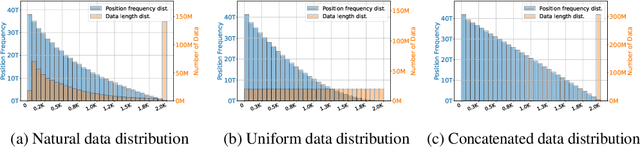
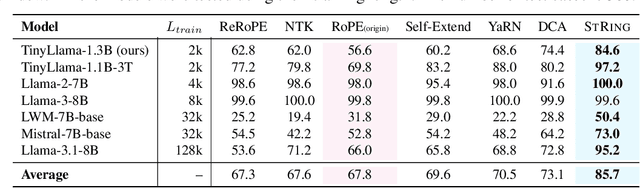
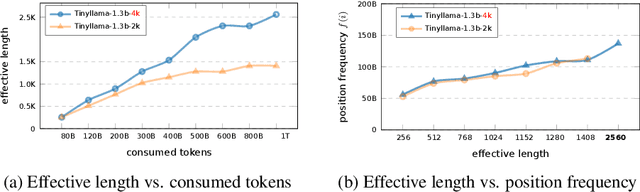
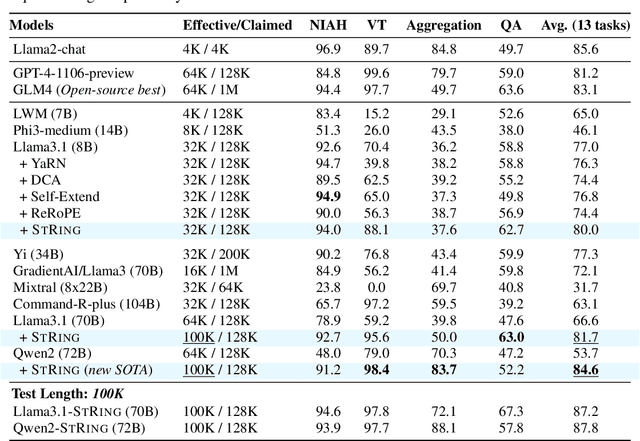
Advancements in distributed training and efficient attention mechanisms have significantly expanded the context window sizes of large language models (LLMs). However, recent work reveals that the effective context lengths of open-source LLMs often fall short, typically not exceeding half of their training lengths. In this work, we attribute this limitation to the left-skewed frequency distribution of relative positions formed in LLMs pretraining and post-training stages, which impedes their ability to effectively gather distant information. To address this challenge, we introduce ShifTed Rotray position embeddING (STRING). STRING shifts well-trained positions to overwrite the original ineffective positions during inference, enhancing performance within their existing training lengths. Experimental results show that without additional training, STRING dramatically improves the performance of the latest large-scale models, such as Llama3.1 70B and Qwen2 72B, by over 10 points on popular long-context benchmarks RULER and InfiniteBench, establishing new state-of-the-art results for open-source LLMs. Compared to commercial models, Llama 3.1 70B with \method even achieves better performance than GPT-4-128K and clearly surpasses Claude 2 and Kimi-chat.
FAN: Fourier Analysis Networks
Oct 03, 2024



Despite the remarkable success achieved by neural networks, particularly those represented by MLP and Transformer, we reveal that they exhibit potential flaws in the modeling and reasoning of periodicity, i.e., they tend to memorize the periodic data rather than genuinely understanding the underlying principles of periodicity. However, periodicity is a crucial trait in various forms of reasoning and generalization, underpinning predictability across natural and engineered systems through recurring patterns in observations. In this paper, we propose FAN, a novel network architecture based on Fourier Analysis, which empowers the ability to efficiently model and reason about periodic phenomena. By introducing Fourier Series, the periodicity is naturally integrated into the structure and computational processes of the neural network, thus achieving a more accurate expression and prediction of periodic patterns. As a promising substitute to multi-layer perceptron (MLP), FAN can seamlessly replace MLP in various models with fewer parameters and FLOPs. Through extensive experiments, we demonstrate the effectiveness of FAN in modeling and reasoning about periodic functions, and the superiority and generalizability of FAN across a range of real-world tasks, including symbolic formula representation, time series forecasting, and language modeling.
Survey and Taxonomy: The Role of Data-Centric AI in Transformer-Based Time Series Forecasting
Jul 29, 2024Alongside the continuous process of improving AI performance through the development of more sophisticated models, researchers have also focused their attention to the emerging concept of data-centric AI, which emphasizes the important role of data in a systematic machine learning training process. Nonetheless, the development of models has also continued apace. One result of this progress is the development of the Transformer Architecture, which possesses a high level of capability in multiple domains such as Natural Language Processing (NLP), Computer Vision (CV) and Time Series Forecasting (TSF). Its performance is, however, heavily dependent on input data preprocessing and output data evaluation, justifying a data-centric approach to future research. We argue that data-centric AI is essential for training AI models, particularly for transformer-based TSF models efficiently. However, there is a gap regarding the integration of transformer-based TSF and data-centric AI. This survey aims to pin down this gap via the extensive literature review based on the proposed taxonomy. We review the previous research works from a data-centric AI perspective and we intend to lay the foundation work for the future development of transformer-based architecture and data-centric AI.
Let the Code LLM Edit Itself When You Edit the Code
Jul 03, 2024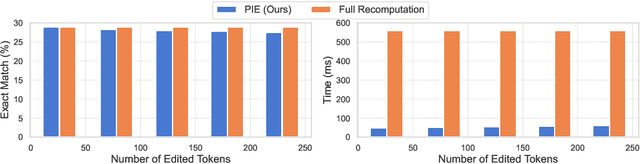
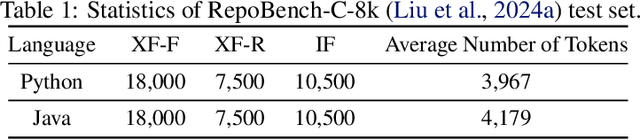
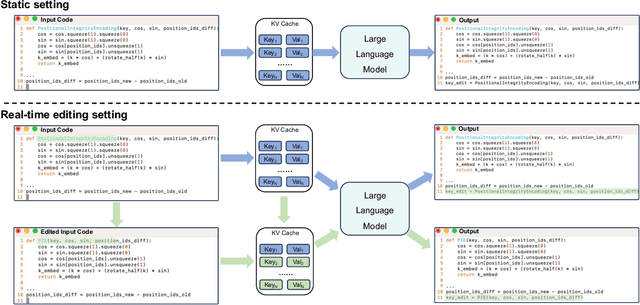
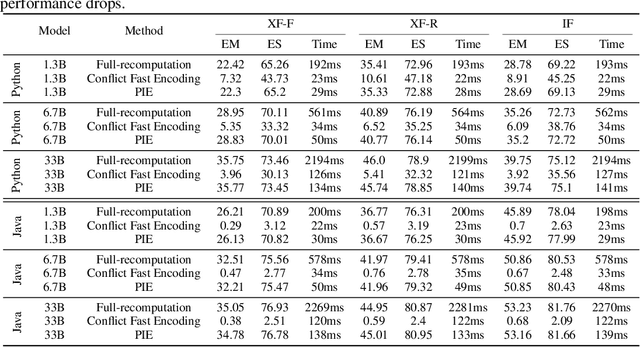
In this work, we investigate a typical scenario in code generation where a developer edits existing code in real time and requests a code assistant, e.g., a large language model, to re-predict the next token or next line on the fly. Naively, the LLM needs to re-encode the entire KV cache to provide an accurate prediction. However, this process is computationally expensive, especially when the sequence length is long. Simply encoding the edited subsequence and integrating it to the original KV cache meets the temporal confusion problem, leading to significantly worse performance. We address this efficiency and accuracy trade-off by introducing \underline{\textbf{Positional \textbf{I}ntegrity \textbf{E}ncoding} (PIE). Building upon the rotary positional encoding, PIE first removes the rotary matrices in the Key cache that introduce temporal confusion and then reapplies the correct rotary matrices. This process ensures that positional relationships between tokens are correct and requires only a single round of matrix multiplication. We validate the effectiveness of PIE through extensive experiments on the RepoBench-C-8k dataset, utilizing DeepSeek-Coder models with 1.3B, 6.7B, and 33B parameters. Our evaluation includes three real-world coding tasks: code insertion, code deletion, and multi-place code editing. Results demonstrate that PIE reduces computational overhead by over 85% compared to the standard full recomputation approach across all model sizes and tasks while well approximating the model performance.