 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
Jan 23, 2026Diffusion-based language models (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models, but existing code DLLMs still lag behind strong AR baselines under comparable budgets. We revisit this setting in a controlled study and introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline. To enable efficient knowledge learning and stable training, we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule. Under the same data and architecture, Stable-DiffCoder overall outperforms its AR counterpart on a broad suite of code benchmarks. Moreover, relying only on the CPT and supervised fine-tuning stages, Stable-DiffCoder achieves stronger performance than a wide range of \~8B ARs and DLLMs, demonstrating that diffusion-based training can improve code modeling quality beyond AR training alone. Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning, and through data augmentation, benefits low-resource coding languages.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Apr 03, 2025The task of issue resolving is to modify a codebase to generate a patch that addresses a given issue. However, existing benchmarks, such as SWE-bench, focus almost exclusively on Python, making them insufficient for evaluating Large Language Models (LLMs) across diverse software ecosystems. To address this, we introduce a multilingual issue-resolving benchmark, called Multi-SWE-bench, covering Java, TypeScript, JavaScript, Go, Rust, C, and C++. It includes a total of 1,632 high-quality instances, which were carefully annotated from 2,456 candidates by 68 expert annotators, ensuring that the benchmark can provide an accurate and reliable evaluation. Based on Multi-SWE-bench, we evaluate a series of state-of-the-art models using three representative methods (Agentless, SWE-agent, and OpenHands) and present a comprehensive analysis with key empirical insights. In addition, we launch a Multi-SWE-RL open-source community, aimed at building large-scale reinforcement learning (RL) training datasets for issue-resolving tasks. As an initial contribution, we release a set of 4,723 well-structured instances spanning seven programming languages, laying a solid foundation for RL research in this domain. More importantly, we open-source our entire data production pipeline, along with detailed tutorials, encouraging the open-source community to continuously contribute and expand the dataset. We envision our Multi-SWE-bench and the ever-growing Multi-SWE-RL community as catalysts for advancing RL toward its full potential, bringing us one step closer to the dawn of AGI.
MAP-based Problem-Agnostic diffusion model for Inverse Problems
Jan 25, 2025



Diffusion models have indeed shown great promise in solving inverse problems in image processing. In this paper, we propose a novel, problem-agnostic diffusion model called the maximum a posteriori (MAP)-based guided term estimation method for inverse problems. We divide the conditional score function into two terms according to Bayes' rule: the unconditional score function and the guided term. We design the MAP-based guided term estimation method, while the unconditional score function is approximated by an existing score network. To estimate the guided term, we base on the assumption that the space of clean natural images is inherently smooth, and introduce a MAP estimate of the $t$-th latent variable. We then substitute this estimation into the expression of the inverse problem and obtain the approximation of the guided term. We evaluate our method extensively on super-resolution, inpainting, and denoising tasks, and demonstrate comparable performance to DDRM, DMPS, DPS and $\Pi$GDM.
Each Rank Could be an Expert: Single-Ranked Mixture of Experts LoRA for Multi-Task Learning
Jan 25, 2025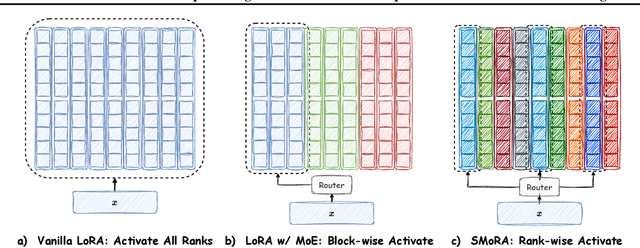
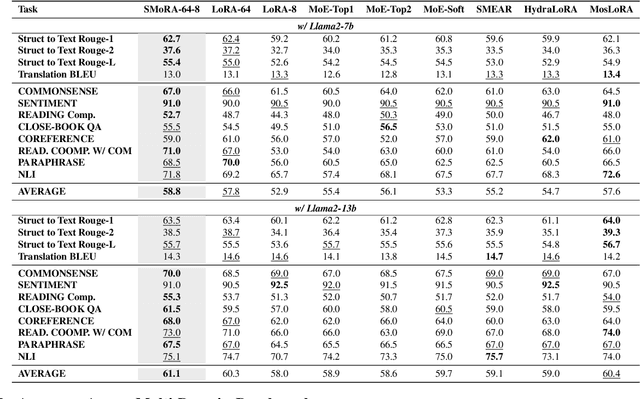
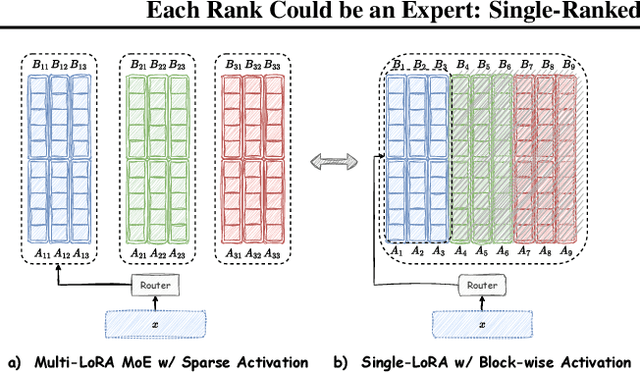
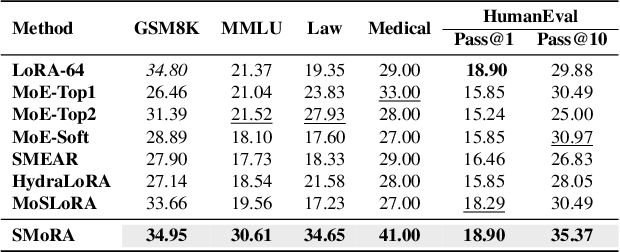
Low-Rank Adaptation (LoRA) is widely used for adapting large language models (LLMs) to specific domains due to its efficiency and modularity. Meanwhile, vanilla LoRA struggles with task conflicts in multi-task scenarios. Recent works adopt Mixture of Experts (MoE) by treating each LoRA module as an expert, thereby mitigating task interference through multiple specialized LoRA modules. While effective, these methods often isolate knowledge within individual tasks, failing to fully exploit the shared knowledge across related tasks. In this paper, we establish a connection between single LoRA and multi-LoRA MoE, integrating them into a unified framework. We demonstrate that the dynamic routing of multiple LoRAs is functionally equivalent to rank partitioning and block-level activation within a single LoRA. We further empirically demonstrate that finer-grained LoRA partitioning, within the same total and activated parameter constraints, leads to better performance gains across heterogeneous tasks. Building on these findings, we propose Single-ranked Mixture of Experts LoRA (\textbf{SMoRA}), which embeds MoE into LoRA by \textit{treating each rank as an independent expert}. With a \textit{dynamic rank-wise activation} mechanism, SMoRA promotes finer-grained knowledge sharing while mitigating task conflicts. Experiments demonstrate that SMoRA activates fewer parameters yet achieves better performance in multi-task scenarios.
Interference-Robust Broadband Rapidly-Varying MIMO Communications: A Knowledge-Data Dual Driven Framework
Dec 26, 2024A novel time-efficient framework is proposed for improving the robustness of a broadband multiple-input multiple-output (MIMO) system against unknown interference under rapidly-varying channels. A mean-squared error (MSE) minimization problem is formulated by optimizing the beamformers employed. Since the unknown interference statistics are the premise for solving the formulated problem, an interference statistics tracking (IST) module is first designed. The IST module exploits both the time- and spatial-domain correlations of the interference-plus-noise (IPN) covariance for the future predictions with data training. Compared to the conventional signal-free space sampling approach, the IST module can realize zero-pilot and low-latency estimation. Subsequently, an interference-resistant hybrid beamforming (IR-HBF) module is presented, which incorporates both the prior knowledge of the theoretical optimization method as well as the data-fed training. Taking advantage of the interpretable network structure, the IR-HBF module enables the simplified mapping from the interference statistics to the beamforming weights. The simulations are executed in high-mobility scenarios, where the numerical results unveil that: 1) the proposed IST module attains promising prediction accuracy compared to the conventional counterparts under different snapshot sampling errors; and 2) the proposed IR-HBF module achieves lower MSE with significantly reduced computational complexity.
The Rise and Down of Babel Tower: Investigating the Evolution Process of Multilingual Code Large Language Model
Dec 10, 2024



Large language models (LLMs) have shown significant multilingual capabilities. However, the mechanisms underlying the development of these capabilities during pre-training are not well understood. In this paper, we use code LLMs as an experimental platform to explore the evolution of multilingual capabilities in LLMs during the pre-training process. Based on our observations, we propose the Babel Tower Hypothesis, which describes the entire process of LLMs acquiring new language capabilities. During the learning process, multiple languages initially share a single knowledge system dominated by the primary language and gradually develop language-specific knowledge systems. We then validate the above hypothesis by tracking the internal states of the LLMs through identifying working languages and language transferring neurons. Experimental results show that the internal state changes of the LLM are consistent with our Babel Tower Hypothesis. Building on these insights, we propose a novel method to construct an optimized pre-training corpus for multilingual code LLMs, which significantly outperforms LLMs trained on the original corpus. The proposed Babel Tower Hypothesis provides new insights into designing pre-training data distributions to achieve optimal multilingual capabilities in LLMs.
A Lightweight Target-Driven Network of Stereo Matching for Inland Waterways
Oct 10, 2024Stereo matching for inland waterways is one of the key technologies for the autonomous navigation of Unmanned Surface Vehicles (USVs), which involves dividing the stereo images into reference images and target images for pixel-level matching. However, due to the challenges of the inland waterway environment, such as blurred textures, large spatial scales, and computational resource constraints of the USVs platform, the participation of geometric features from the target image is required for efficient target-driven matching. Based on this target-driven concept, we propose a lightweight target-driven stereo matching neural network, named LTNet. Specifically, a lightweight and efficient 4D cost volume, named the Geometry Target Volume (GTV), is designed to fully utilize the geometric information of target features by employing the shifted target features as the filtered feature volume. Subsequently, to address the substantial texture interference and object occlusions present in the waterway environment, a Left-Right Consistency Refinement (LRR) module is proposed. The \text{LRR} utilizes the pixel-level differences in left and right disparities to introduce soft constraints, thereby enhancing the accuracy of predictions during the intermediate stages of the network. Moreover, knowledge distillation is utilized to enhance the generalization capability of lightweight models on the USVInland dataset. Furthermore, a new large-scale benchmark, named Spring, is utilized to validate the applicability of LTNet across various scenarios. In experiments on the aforementioned two datasets, LTNet achieves competitive results, with only 3.7M parameters. The code is available at https://github.com/Open-YiQingZhou/LTNet .
FAN: Fourier Analysis Networks
Oct 03, 2024



Despite the remarkable success achieved by neural networks, particularly those represented by MLP and Transformer, we reveal that they exhibit potential flaws in the modeling and reasoning of periodicity, i.e., they tend to memorize the periodic data rather than genuinely understanding the underlying principles of periodicity. However, periodicity is a crucial trait in various forms of reasoning and generalization, underpinning predictability across natural and engineered systems through recurring patterns in observations. In this paper, we propose FAN, a novel network architecture based on Fourier Analysis, which empowers the ability to efficiently model and reason about periodic phenomena. By introducing Fourier Series, the periodicity is naturally integrated into the structure and computational processes of the neural network, thus achieving a more accurate expression and prediction of periodic patterns. As a promising substitute to multi-layer perceptron (MLP), FAN can seamlessly replace MLP in various models with fewer parameters and FLOPs. Through extensive experiments, we demonstrate the effectiveness of FAN in modeling and reasoning about periodic functions, and the superiority and generalizability of FAN across a range of real-world tasks, including symbolic formula representation, time series forecasting, and language modeling.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.