 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKARMA: Knowledge-Action Regularized Multimodal Alignment for Personalized Search at Taobao
Mar 24, 2026Large Language Models (LLMs) are equipped with profound semantic knowledge, making them a natural choice for injecting semantic generalization into personalized search systems. However, in practice we find that directly fine-tuning LLMs on industrial personalized tasks (e.g. next item prediction) often yields suboptimal results. We attribute this bottleneck to a critical Knowledge--Action Gap: the inherent conflict between preserving pre-trained semantic knowledge and aligning with specific personalized actions by discriminative objectives. Empirically, action-only training objectives induce Semantic Collapse, such as attention ``sinks''. This degradation severely cripples the LLM's generalization, failing to bring improvements to personalized search systems. We propose KARMA (Knowledge--Action Regularized Multimodal Alignment), a unified framework that treats semantic reconstruction as a train-only regularizer. KARMA optimizes a next-interest embedding for retrieval (Action) while enforcing semantic decodability (Knowledge) through two complementary objectives: (i) history-conditioned semantic generation, which anchors optimization to the LLM's native next-token distribution, and (ii) embedding-conditioned semantic reconstruction, which constrains the interest embedding to remain semantically recoverable. On Taobao search system, KARMA mitigates semantic collapse (attention-sink analysis) and improves both action metrics and semantic fidelity. In ablations, semantic decodability yields up to +22.5 HR@200. With KARMA, we achieve +0.25 CTR AUC in ranking, +1.86 HR in pre-ranking and +2.51 HR in recalling. Deployed online with low inference overhead at ranking stage, KARMA drives +0.5% increase in Item Click.
Image Aesthetic Reasoning via HCM-GRPO: Empowering Compact Model for Superior Performance
Nov 13, 2025The performance of image generation has been significantly improved in recent years. However, the study of image screening is rare and its performance with Multimodal Large Language Models (MLLMs) is unsatisfactory due to the lack of data and the weak image aesthetic reasoning ability in MLLMs. In this work, we propose a complete solution to address these problems in terms of data and methodology. For data, we collect a comprehensive image screening dataset with over 128k samples, about 640k images. Each sample consists of an original image, four generated images. The dataset evaluates the image aesthetic reasoning ability under four aspects: appearance deformation, physical shadow, placement layout, and extension rationality. Regarding data annotation, we investigate multiple approaches, including purely manual, fully automated, and answer-driven annotations, to acquire high-quality chains of thought (CoT) data in the most cost-effective manner. Methodologically, we introduce a Hard Cases Mining (HCM) strategy with a Dynamic Proportional Accuracy (DPA) reward into the Group Relative Policy Optimization (GRPO) framework, called HCM-GRPO. This enhanced method demonstrates superior image aesthetic reasoning capabilities compared to the original GRPO. Our experimental results reveal that even state-of-the-art closed-source MLLMs, such as GPT4o and Qwen-VL-Max, exhibit performance akin to random guessing in image aesthetic reasoning. In contrast, by leveraging the HCM-GRPO, we are able to surpass the scores of both large-scale open-source and leading closed-source models with a much smaller model.
ADIEE: Automatic Dataset Creation and Scorer for Instruction-Guided Image Editing Evaluation
Jul 09, 2025



Recent advances in instruction-guided image editing underscore the need for effective automated evaluation. While Vision-Language Models (VLMs) have been explored as judges, open-source models struggle with alignment, and proprietary models lack transparency and cost efficiency. Additionally, no public training datasets exist to fine-tune open-source VLMs, only small benchmarks with diverse evaluation schemes. To address this, we introduce ADIEE, an automated dataset creation approach which is then used to train a scoring model for instruction-guided image editing evaluation. We generate a large-scale dataset with over 100K samples and use it to fine-tune a LLaVA-NeXT-8B model modified to decode a numeric score from a custom token. The resulting scorer outperforms all open-source VLMs and Gemini-Pro 1.5 across all benchmarks, achieving a 0.0696 (+17.24%) gain in score correlation with human ratings on AURORA-Bench, and improving pair-wise comparison accuracy by 4.03% (+7.21%) on GenAI-Bench and 4.75% (+9.35%) on AURORA-Bench, respectively, compared to the state-of-the-art. The scorer can act as a reward model, enabling automated best edit selection and model fine-tuning. Notably, the proposed scorer can boost MagicBrush model's average evaluation score on ImagenHub from 5.90 to 6.43 (+8.98%).
Vision Generalist Model: A Survey
Jun 11, 2025Recently, we have witnessed the great success of the generalist model in natural language processing. The generalist model is a general framework trained with massive data and is able to process various downstream tasks simultaneously. Encouraged by their impressive performance, an increasing number of researchers are venturing into the realm of applying these models to computer vision tasks. However, the inputs and outputs of vision tasks are more diverse, and it is difficult to summarize them as a unified representation. In this paper, we provide a comprehensive overview of the vision generalist models, delving into their characteristics and capabilities within the field. First, we review the background, including the datasets, tasks, and benchmarks. Then, we dig into the design of frameworks that have been proposed in existing research, while also introducing the techniques employed to enhance their performance. To better help the researchers comprehend the area, we take a brief excursion into related domains, shedding light on their interconnections and potential synergies. To conclude, we provide some real-world application scenarios, undertake a thorough examination of the persistent challenges, and offer insights into possible directions for future research endeavors.
LinGuinE: Longitudinal Guidance Estimation for Volumetric Lung Tumour Segmentation
Jun 06, 2025Segmentation of lung gross tumour volumes is an important first step in radiotherapy and surgical intervention, and is starting to play a role in assessing chemotherapy response. Response to a drug is measured by tracking the tumour volumes over a series of CT scans over a time period i.e. a longitudinal study. However, there currently exist few solutions for automated or semi-automated longitudinal tumour segmentation. This paper introduces LinGuinE, an automated method to segment a longitudinal series of lung tumours. A radiologist must provide an initial input, indicating the location of the tumour in a CT scan at an arbitrary time point. LinGuinE samples points inside this tumour and propagates them to another time point using rigid registration. A click validity classifier selects points which still fall within the tumour; these are used to automatically create a segmentation in the new time point. We test LinGuinE on a dataset acquired from a phase 3 clinical trial for lung tumours and the publicly available 4-D lung CBCT dataset. We find that LinGuinE improves the Dice on both test sets by over 20% (p< 0.05) across 63 longitudinal studies. We show that any time point can be used as a starting point, conduct ablation experiments, and find that our LinGuinE setup yields the best results on both test datasets.
Image Aesthetic Reasoning: A New Benchmark for Medical Image Screening with MLLMs
May 29, 2025Multimodal Large Language Models (MLLMs) are of great application across many domains, such as multimodal understanding and generation. With the development of diffusion models (DM) and unified MLLMs, the performance of image generation has been significantly improved, however, the study of image screening is rare and its performance with MLLMs is unsatisfactory due to the lack of data and the week image aesthetic reasoning ability in MLLMs. In this work, we propose a complete solution to address these problems in terms of data and methodology. For data, we collect a comprehensive medical image screening dataset with 1500+ samples, each sample consists of a medical image, four generated images, and a multiple-choice answer. The dataset evaluates the aesthetic reasoning ability under four aspects: \textit{(1) Appearance Deformation, (2) Principles of Physical Lighting and Shadow, (3) Placement Layout, (4) Extension Rationality}. For methodology, we utilize long chains of thought (CoT) and Group Relative Policy Optimization with Dynamic Proportional Accuracy reward, called DPA-GRPO, to enhance the image aesthetic reasoning ability of MLLMs. Our experimental results reveal that even state-of-the-art closed-source MLLMs, such as GPT-4o and Qwen-VL-Max, exhibit performance akin to random guessing in image aesthetic reasoning. In contrast, by leveraging the reinforcement learning approach, we are able to surpass the score of both large-scale models and leading closed-source models using a much smaller model. We hope our attempt on medical image screening will serve as a regular configuration in image aesthetic reasoning in the future.
HMPNet: A Feature Aggregation Architecture for Maritime Object Detection from a Shipborne Perspective
May 13, 2025In the realm of intelligent maritime navigation, object detection from a shipborne perspective is paramount. Despite the criticality, the paucity of maritime-specific data impedes the deployment of sophisticated visual perception techniques, akin to those utilized in autonomous vehicular systems, within the maritime context. To bridge this gap, we introduce Navigation12, a novel dataset annotated for 12 object categories under diverse maritime environments and weather conditions. Based upon this dataset, we propose HMPNet, a lightweight architecture tailored for shipborne object detection. HMPNet incorporates a hierarchical dynamic modulation backbone to bolster feature aggregation and expression, complemented by a matrix cascading poly-scale neck and a polymerization weight sharing detector, facilitating efficient multi-scale feature aggregation. Empirical evaluations indicate that HMPNet surpasses current state-of-the-art methods in terms of both accuracy and computational efficiency, realizing a 3.3% improvement in mean Average Precision over YOLOv11n, the prevailing model, and reducing parameters by 23%.
Balancing Efficiency and Effectiveness: An LLM-Infused Approach for Optimized CTR Prediction
Dec 09, 2024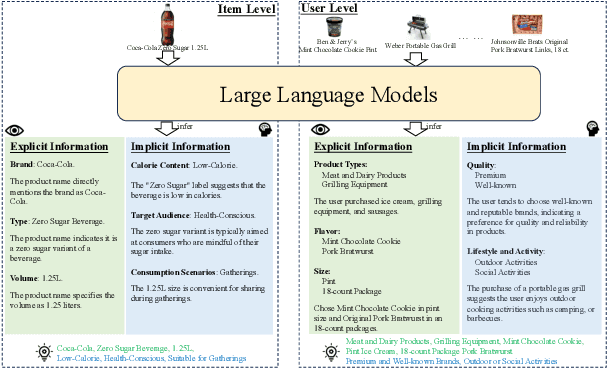

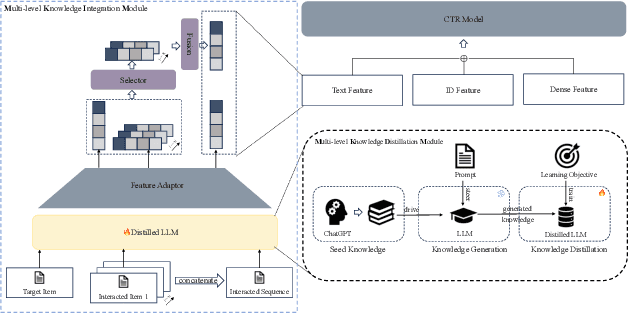

Click-Through Rate (CTR) prediction is essential in online advertising, where semantic information plays a pivotal role in shaping user decisions and enhancing CTR effectiveness. Capturing and modeling deep semantic information, such as a user's preference for "H\"aagen-Dazs' HEAVEN strawberry light ice cream" due to its health-conscious and premium attributes, is challenging. Traditional semantic modeling often overlooks these intricate details at the user and item levels. To bridge this gap, we introduce a novel approach that models deep semantic information end-to-end, leveraging the comprehensive world knowledge capabilities of Large Language Models (LLMs). Our proposed LLM-infused CTR prediction framework(Multi-level Deep Semantic Information Infused CTR model via Distillation, MSD) is designed to uncover deep semantic insights by utilizing LLMs to extract and distill critical information into a smaller, more efficient model, enabling seamless end-to-end training and inference. Importantly, our framework is carefully designed to balance efficiency and effectiveness, ensuring that the model not only achieves high performance but also operates with optimal resource utilization. Online A/B tests conducted on the Meituan sponsored-search system demonstrate that our method significantly outperforms baseline models in terms of Cost Per Mile (CPM) and CTR, validating its effectiveness, scalability, and balanced approach in real-world applications.
Approximate attention with MLP: a pruning strategy for attention-based model in multivariate time series forecasting
Oct 31, 2024



Attention-based architectures have become ubiquitous in time series forecasting tasks, including spatio-temporal (STF) and long-term time series forecasting (LTSF). Yet, our understanding of the reasons for their effectiveness remains limited. This work proposes a new way to understand self-attention networks: we have shown empirically that the entire attention mechanism in the encoder can be reduced to an MLP formed by feedforward, skip-connection, and layer normalization operations for temporal and/or spatial modeling in multivariate time series forecasting. Specifically, the Q, K, and V projection, the attention score calculation, the dot-product between the attention score and the V, and the final projection can be removed from the attention-based networks without significantly degrading the performance that the given network remains the top-tier compared to other SOTA methods. For spatio-temporal networks, the MLP-replace-attention network achieves a reduction in FLOPS of $62.579\%$ with a loss in performance less than $2.5\%$; for LTSF, a reduction in FLOPs of $42.233\%$ with a loss in performance less than $2\%$.
A Lightweight Target-Driven Network of Stereo Matching for Inland Waterways
Oct 10, 2024Stereo matching for inland waterways is one of the key technologies for the autonomous navigation of Unmanned Surface Vehicles (USVs), which involves dividing the stereo images into reference images and target images for pixel-level matching. However, due to the challenges of the inland waterway environment, such as blurred textures, large spatial scales, and computational resource constraints of the USVs platform, the participation of geometric features from the target image is required for efficient target-driven matching. Based on this target-driven concept, we propose a lightweight target-driven stereo matching neural network, named LTNet. Specifically, a lightweight and efficient 4D cost volume, named the Geometry Target Volume (GTV), is designed to fully utilize the geometric information of target features by employing the shifted target features as the filtered feature volume. Subsequently, to address the substantial texture interference and object occlusions present in the waterway environment, a Left-Right Consistency Refinement (LRR) module is proposed. The \text{LRR} utilizes the pixel-level differences in left and right disparities to introduce soft constraints, thereby enhancing the accuracy of predictions during the intermediate stages of the network. Moreover, knowledge distillation is utilized to enhance the generalization capability of lightweight models on the USVInland dataset. Furthermore, a new large-scale benchmark, named Spring, is utilized to validate the applicability of LTNet across various scenarios. In experiments on the aforementioned two datasets, LTNet achieves competitive results, with only 3.7M parameters. The code is available at https://github.com/Open-YiQingZhou/LTNet .