 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-LLM: Teaching Large Language Models to Forecast Time Series via Temporal Distillation
Feb 02, 2026Time series forecasting plays a critical role in decision-making across many real-world applications. Unlike data in vision and language domains, time series data is inherently tied to the evolution of underlying processes and can only accumulate as real-world time progresses, limiting the effectiveness of scale-driven pretraining alone. This time-bound constraint poses a challenge for enabling large language models (LLMs) to acquire forecasting capability, as existing approaches primarily rely on representation-level alignment or inference-time temporal modules rather than explicitly teaching forecasting behavior to the LLM. We propose T-LLM, a temporal distillation framework that equips general-purpose LLMs with time series forecasting capability by transferring predictive behavior from a lightweight temporal teacher during training. The teacher combines trend modeling and frequency-domain analysis to provide structured temporal supervision, and is removed entirely at inference, leaving the LLM as the sole forecasting model. Experiments on benchmark datasets and infectious disease forecasting tasks demonstrate that T-LLM consistently outperforms existing LLM-based forecasting methods under full-shot, few-shot, and zero-shot settings, while enabling a simple and efficient deployment pipeline.
MiCA: A Mobility-Informed Causal Adapter for Lightweight Epidemic Forecasting
Jan 16, 2026Accurate forecasting of infectious disease dynamics is critical for public health planning and intervention. Human mobility plays a central role in shaping the spatial spread of epidemics, but mobility data are noisy, indirect, and difficult to integrate reliably with disease records. Meanwhile, epidemic case time series are typically short and reported at coarse temporal resolution. These conditions limit the effectiveness of parameter-heavy mobility-aware forecasters that rely on clean and abundant data. In this work, we propose the Mobility-Informed Causal Adapter (MiCA), a lightweight and architecture-agnostic module for epidemic forecasting. MiCA infers mobility relations through causal discovery and integrates them into temporal forecasting models via gated residual mixing. This design allows lightweight forecasters to selectively exploit mobility-derived spatial structure while remaining robust under noisy and data-limited conditions, without introducing heavy relational components such as graph neural networks or full attention. Extensive experiments on four real-world epidemic datasets, including COVID-19 incidence, COVID-19 mortality, influenza, and dengue, show that MiCA consistently improves lightweight temporal backbones, achieving an average relative error reduction of 7.5\% across forecasting horizons. Moreover, MiCA attains performance competitive with SOTA spatio-temporal models while remaining lightweight.
SPAT: Sensitivity-based Multihead-attention Pruning on Time Series Forecasting Models
May 13, 2025Attention-based architectures have achieved superior performance in multivariate time series forecasting but are computationally expensive. Techniques such as patching and adaptive masking have been developed to reduce their sizes and latencies. In this work, we propose a structured pruning method, SPAT ($\textbf{S}$ensitivity $\textbf{P}$runer for $\textbf{At}$tention), which selectively removes redundant attention mechanisms and yields highly effective models. Different from previous approaches, SPAT aims to remove the entire attention module, which reduces the risk of overfitting and enables speed-up without demanding specialized hardware. We propose a dynamic sensitivity metric, $\textbf{S}$ensitivity $\textbf{E}$nhanced $\textbf{N}$ormalized $\textbf{D}$ispersion (SEND) that measures the importance of each attention module during the pre-training phase. Experiments on multivariate datasets demonstrate that SPAT-pruned models achieve reductions of 2.842% in MSE, 1.996% in MAE, and 35.274% in FLOPs. Furthermore, SPAT-pruned models outperform existing lightweight, Mamba-based and LLM-based SOTA methods in both standard and zero-shot inference, highlighting the importance of retaining only the most effective attention mechanisms. We have made our code publicly available https://anonymous.4open.science/r/SPAT-6042.
Estimating the treatment effect over time under general interference through deep learner integrated TMLE
Dec 06, 2024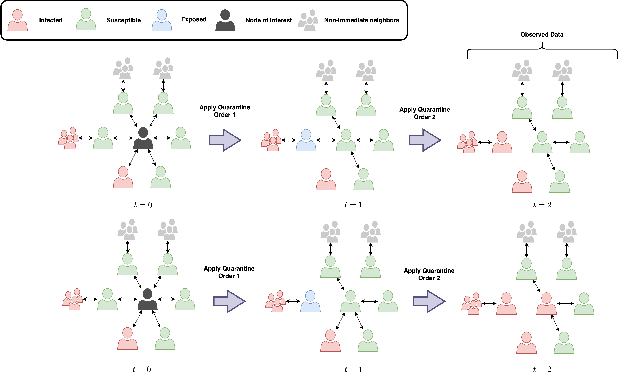
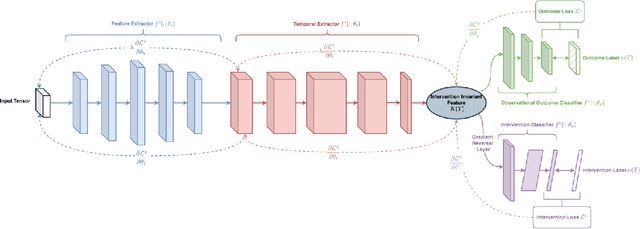
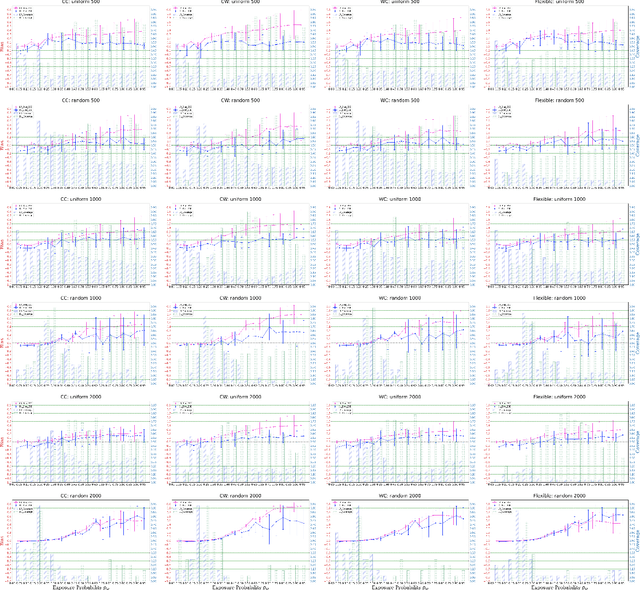
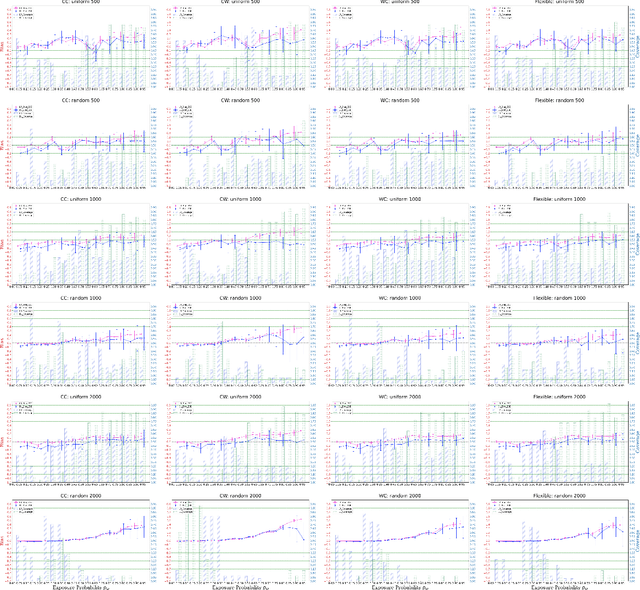
Understanding the effects of quarantine policies in populations with underlying social networks is crucial for public health, yet most causal inference methods fail here due to their assumption of independent individuals. We introduce DeepNetTMLE, a deep-learning-enhanced Targeted Maximum Likelihood Estimation (TMLE) method designed to estimate time-sensitive treatment effects in observational data. DeepNetTMLE mitigates bias from time-varying confounders under general interference by incorporating a temporal module and domain adversarial training to build intervention-invariant representations. This process removes associations between current treatments and historical variables, while the targeting step maintains the bias-variance trade-off, enhancing the reliability of counterfactual predictions. Using simulations of a ``Susceptible-Infected-Recovered'' model with varied quarantine coverages, we show that DeepNetTMLE achieves lower bias and more precise confidence intervals in counterfactual estimates, enabling optimal quarantine recommendations within budget constraints, surpassing state-of-the-art methods.
Approximate attention with MLP: a pruning strategy for attention-based model in multivariate time series forecasting
Oct 31, 2024



Attention-based architectures have become ubiquitous in time series forecasting tasks, including spatio-temporal (STF) and long-term time series forecasting (LTSF). Yet, our understanding of the reasons for their effectiveness remains limited. This work proposes a new way to understand self-attention networks: we have shown empirically that the entire attention mechanism in the encoder can be reduced to an MLP formed by feedforward, skip-connection, and layer normalization operations for temporal and/or spatial modeling in multivariate time series forecasting. Specifically, the Q, K, and V projection, the attention score calculation, the dot-product between the attention score and the V, and the final projection can be removed from the attention-based networks without significantly degrading the performance that the given network remains the top-tier compared to other SOTA methods. For spatio-temporal networks, the MLP-replace-attention network achieves a reduction in FLOPS of $62.579\%$ with a loss in performance less than $2.5\%$; for LTSF, a reduction in FLOPs of $42.233\%$ with a loss in performance less than $2\%$.
Multi-Scale Dilated Convolution Network for Long-Term Time Series Forecasting
May 09, 2024



Accurate forecasting of long-term time series has important applications for decision making and planning. However, it remains challenging to capture the long-term dependencies in time series data. To better extract long-term dependencies, We propose Multi Scale Dilated Convolution Network (MSDCN), a method that utilizes a shallow dilated convolution architecture to capture the period and trend characteristics of long time series. We design different convolution blocks with exponentially growing dilations and varying kernel sizes to sample time series data at different scales. Furthermore, we utilize traditional autoregressive model to capture the linear relationships within the data. To validate the effectiveness of the proposed approach, we conduct experiments on eight challenging long-term time series forecasting benchmark datasets. The experimental results show that our approach outperforms the prior state-of-the-art approaches and shows significant inference speed improvements compared to several strong baseline methods.
Not All Data Matters: An End-to-End Adaptive Dataset Pruning Framework for Enhancing Model Performance and Efficiency
Dec 09, 2023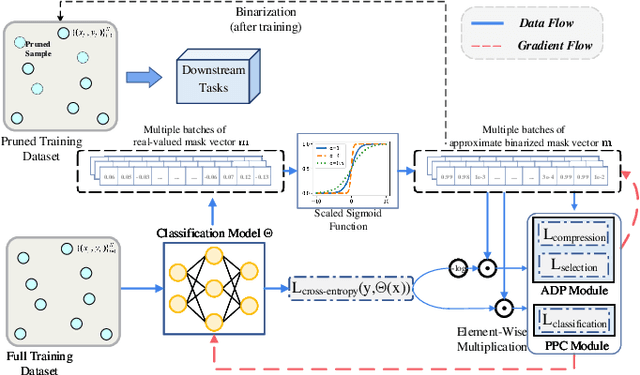



While deep neural networks have demonstrated remarkable performance across various tasks, they typically require massive training data. Due to the presence of redundancies and biases in real-world datasets, not all data in the training dataset contributes to the model performance. To address this issue, dataset pruning techniques have been introduced to enhance model performance and efficiency by eliminating redundant training samples and reducing computational and memory overhead. However, previous works most rely on manually crafted scalar scores, limiting their practical performance and scalability across diverse deep networks and datasets. In this paper, we propose AdaPruner, an end-to-end Adaptive DAtaset PRUNing framEwoRk. AdaPruner can perform effective dataset pruning without the need for explicitly defined metrics. Our framework jointly prunes training data and fine-tunes models with task-specific optimization objectives. AdaPruner leverages (1) An adaptive dataset pruning (ADP) module, which iteratively prunes redundant samples to an expected pruning ratio; and (2) A pruning performance controller (PPC) module, which optimizes the model performance for accurate pruning. Therefore, AdaPruner exhibits high scalability and compatibility across various datasets and deep networks, yielding improved dataset distribution and enhanced model performance. AdaPruner can still significantly enhance model performance even after pruning up to 10-30\% of the training data. Notably, these improvements are accompanied by substantial savings in memory and computation costs. Qualitative and quantitative experiments suggest that AdaPruner outperforms other state-of-the-art dataset pruning methods by a large margin.
Image Data Augmentation for Deep Learning: A Survey
Apr 19, 2022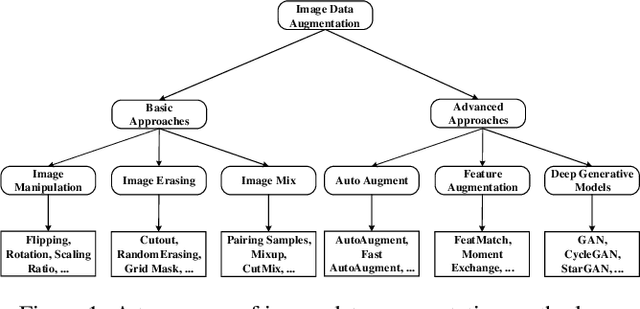

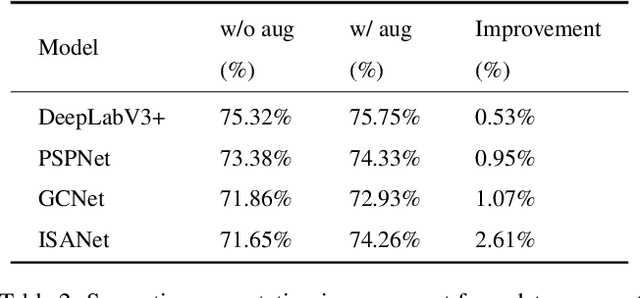
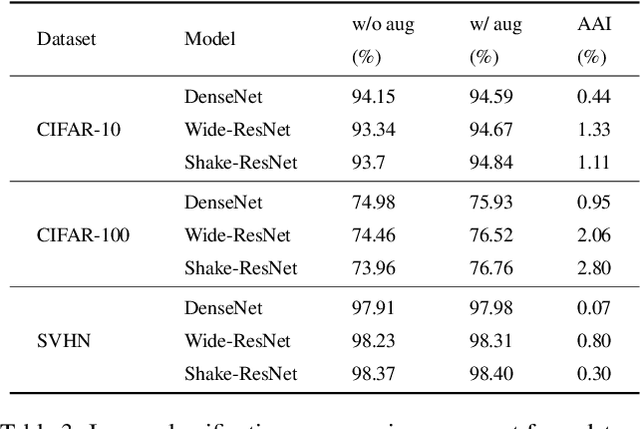
Deep learning has achieved remarkable results in many computer vision tasks. Deep neural networks typically rely on large amounts of training data to avoid overfitting. However, labeled data for real-world applications may be limited. By improving the quantity and diversity of training data, data augmentation has become an inevitable part of deep learning model training with image data. As an effective way to improve the sufficiency and diversity of training data, data augmentation has become a necessary part of successful application of deep learning models on image data. In this paper, we systematically review different image data augmentation methods. We propose a taxonomy of reviewed methods and present the strengths and limitations of these methods. We also conduct extensive experiments with various data augmentation methods on three typical computer vision tasks, including semantic segmentation, image classification and object detection. Finally, we discuss current challenges faced by data augmentation and future research directions to put forward some useful research guidance.