 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Data Augmentation for Deep Learning: A Survey
Apr 19, 2022

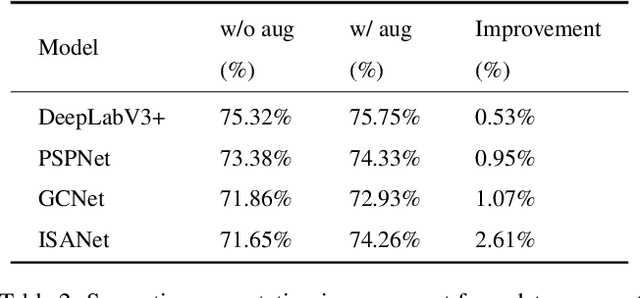
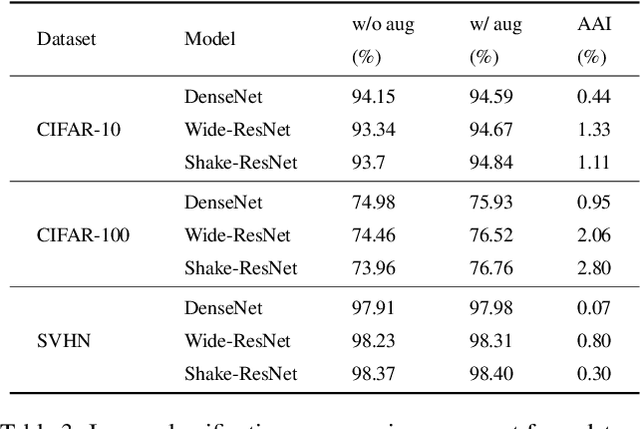
Deep learning has achieved remarkable results in many computer vision tasks. Deep neural networks typically rely on large amounts of training data to avoid overfitting. However, labeled data for real-world applications may be limited. By improving the quantity and diversity of training data, data augmentation has become an inevitable part of deep learning model training with image data. As an effective way to improve the sufficiency and diversity of training data, data augmentation has become a necessary part of successful application of deep learning models on image data. In this paper, we systematically review different image data augmentation methods. We propose a taxonomy of reviewed methods and present the strengths and limitations of these methods. We also conduct extensive experiments with various data augmentation methods on three typical computer vision tasks, including semantic segmentation, image classification and object detection. Finally, we discuss current challenges faced by data augmentation and future research directions to put forward some useful research guidance.
SASICM A Multi-Task Benchmark For Subtext Recognition
Jul 04, 2021

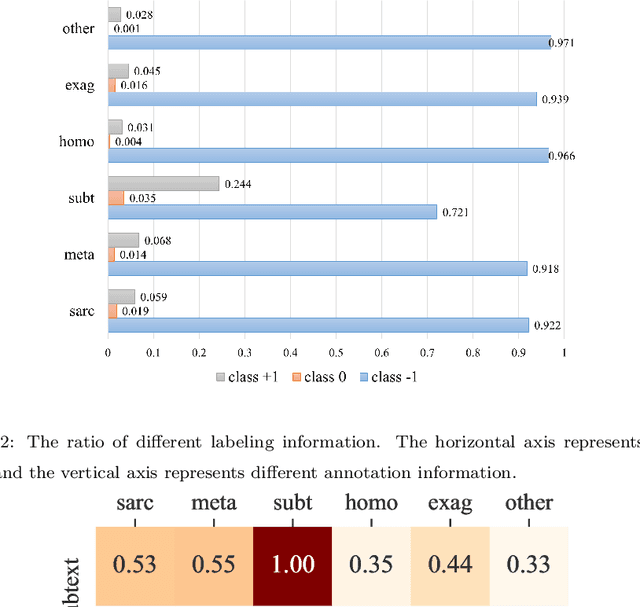
Subtext is a kind of deep semantics which can be acquired after one or more rounds of expression transformation. As a popular way of expressing one's intentions, it is well worth studying. In this paper, we try to make computers understand whether there is a subtext by means of machine learning. We build a Chinese dataset whose source data comes from the popular social media (e.g. Weibo, Netease Music, Zhihu, and Bilibili). In addition, we also build a baseline model called SASICM to deal with subtext recognition. The F1 score of SASICMg, whose pretrained model is GloVe, is as high as 64.37%, which is 3.97% higher than that of BERT based model, 12.7% higher than that of traditional methods on average, including support vector machine, logistic regression classifier, maximum entropy classifier, naive bayes classifier and decision tree and 2.39% higher than that of the state-of-the-art, including MARIN and BTM. The F1 score of SASICMBERT, whose pretrained model is BERT, is 65.12%, which is 0.75% higher than that of SASICMg. The accuracy rates of SASICMg and SASICMBERT are 71.16% and 70.76%, respectively, which can compete with those of other methods which are mentioned before.