 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyReal: A Benchmark for Real-World Polymer Science Workflows
Apr 03, 2026Multimodal Large Language Models (MLLMs) excel in general domains but struggle with complex, real-world science. We posit that polymer science, an interdisciplinary field spanning chemistry, physics, biology, and engineering, is an ideal high-stakes testbed due to its diverse multimodal data. Yet, existing benchmarks related to polymer science largely overlook real-world workflows, limiting their practical utility and failing to systematically evaluate MLLMs across the full, practice-grounded lifecycle of experimentation. We introduce PolyReal, a novel multimodal benchmark grounded in real-world scientific practices to evaluate MLLMs on the full lifecycle of polymer experimentation. It covers five critical capabilities: (1) foundational knowledge application; (2) lab safety analysis; (3) experiment mechanism reasoning; (4) raw data extraction; and (5) performance & application exploration. Our evaluation of leading MLLMs on PolyReal reveals a capability imbalance. While models perform well on knowledge-intensive reasoning (e.g., Experiment Mechanism Reasoning), they drop sharply on practice-based tasks (e.g., Lab Safety Analysis and Raw Data Extraction). This exposes a severe gap between abstract scientific knowledge and its practical, context-dependent application, showing that these real-world tasks remain challenging for MLLMs. Thus, PolyReal helps address this evaluation gap and provides a practical benchmark for assessing AI systems in real-world scientific workflows.
Towards Realistic Class-Incremental Learning with Free-Flow Increments
Apr 03, 2026Class-incremental learning (CIL) is typically evaluated under predefined schedules with equal-sized tasks, leaving more realistic and complex cases unexplored. However, a practical CIL system should learns immediately when any number of new classes arrive, without forcing fixed-size tasks. We formalize this setting as Free-Flow Class-Incremental Learning (FFCIL), where data arrives as a more realistic stream with a highly variable number of unseen classes each step. It will make many existing CIL methods brittle and lead to clear performance degradation. We propose a model-agnostic framework for robust CIL learning under free-flow arrivals. It comprises a class-wise mean (CWM) objective that replaces sample frequency weighted loss with uniformly aggregated class-conditional supervision, thereby stabilizing the learning signal across free-flow class increments, as well as method-wise adjustments that improve robustness for representative CIL paradigms. Specifically, we constrain distillation to replayed data, normalize the scale of contrastive and knowledge transfer losses, and introduce Dynamic Intervention Weight Alignment (DIWA) to prevent over-adjustment caused by unstable statistics from small class increments. Experiments confirm a clear performance degradation across various CIL baselines under FFCIL, while our strategies yield consistent gains.
One-shot Optimized Steering Vector for Hallucination Mitigation for VLMs
Jan 30, 2026Vision Language Models (VLMs) achieve strong performance on multimodal tasks but still suffer from hallucination and safety-related failures that persist even at scale. Steering offers a lightweight technique to improve model performance. However, steering, whether input-dependent or input-independent, achieves a meaningful trade-off between efficiency and effectiveness. In this work, we observe that steering vectors can generalize across inputs when tasks share aligned semantic intent. Based on this insight, we propose \textbf{OSGA} (\textbf{O}ne-shot \textbf{S}teering with \textbf{G}enerative \textbf{A}nchor), an input-independent framework that improves model performance with a single optimization instance. OSGA first selects an informative sample via a variance-based data selection strategy and learns a single steering vector with a contrastive objective with generative anchor regularization. The resulting vector can be universally applied at a certain layer during inference time without modifying model parameters. Experiments across multiple benchmarks show that a single OSGA-optimized steering vector consistently improves hallucination mitigation and safety enhancement with negligible overhead, highlighting one-shot steering as a practical and scalable solution for reliable VLMs.
Exposing Hallucinations To Suppress Them: VLMs Representation Editing With Generative Anchors
Sep 26, 2025Multimodal large language models (MLLMs) have achieved remarkable success across diverse vision-language tasks, yet they remain highly susceptible to hallucinations, producing content that is fluent but inconsistent with visual evidence. Such hallucinations, spanning objects, attributes, and relations, persist even in larger models, while existing mitigation approaches often require additional finetuning, handcrafted priors, or trade-offs that compromise informativeness and scalability. To address this limitation, we propose a training-free, self-supervised method for hallucination mitigation. Our approach introduces a novel hallucination amplification mechanism: a caption is projected into the visual space via a text-to-image model to reveal implicit hallucination signals, serving as a negative anchor, while the original image provides a positive anchor. Leveraging these dual anchors, we edit decoder hidden states by pulling representations toward faithful semantics and pushing them away from hallucination directions. This correction requires no human priors or additional training costs, ensuring both effectiveness and efficiency. Extensive experiments across multiple benchmarks show that our method significantly reduces hallucinations at the object, attribute, and relation levels while largely preserving recall and caption richness, e.g., achieving a hallucination reduction by over 5% using LLaVA-v1.5-7B on CHAIR. Furthermore, results on diverse architectures, including LLaVA-NEXT-7B, Cambrian-8B, and InstructBLIP-7B, validate strong cross-architecture generalization. More importantly, when applied to hallucination-free captions, our method introduces almost no side effects, underscoring its robustness and practical plug-and-play applicability. The implementation will be publicly available.
RL-Selector: Reinforcement Learning-Guided Data Selection via Redundancy Assessment
Jun 26, 2025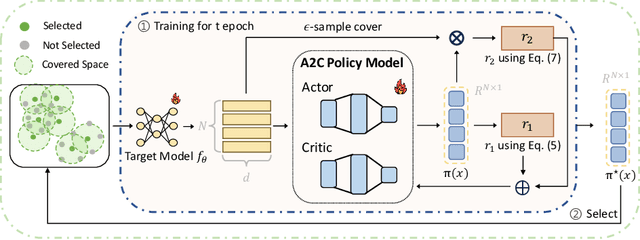
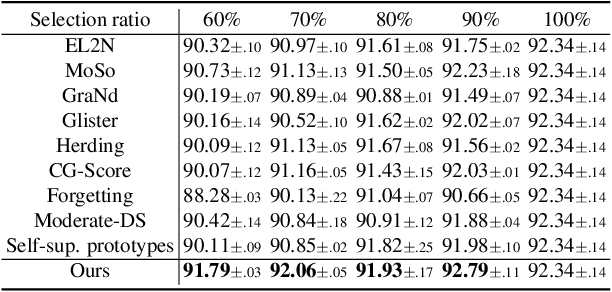
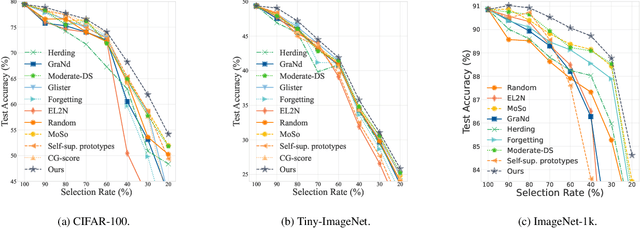
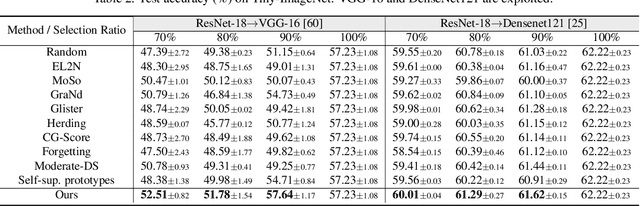
Modern deep architectures often rely on large-scale datasets, but training on these datasets incurs high computational and storage overhead. Real-world datasets often contain substantial redundancies, prompting the need for more data-efficient training paradigms. Data selection has shown promise to mitigate redundancy by identifying the most representative samples, thereby reducing training costs without compromising performance. Existing methods typically rely on static scoring metrics or pretrained models, overlooking the combined effect of selected samples and their evolving dynamics during training. We introduce the concept of epsilon-sample cover, which quantifies sample redundancy based on inter-sample relationships, capturing the intrinsic structure of the dataset. Based on this, we reformulate data selection as a reinforcement learning (RL) process and propose RL-Selector, where a lightweight RL agent optimizes the selection policy by leveraging epsilon-sample cover derived from evolving dataset distribution as a reward signal. Extensive experiments across benchmark datasets and diverse architectures demonstrate that our method consistently outperforms existing state-of-the-art baselines. Models trained with our selected datasets show enhanced generalization performance with improved training efficiency.
* ICCV 2025
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025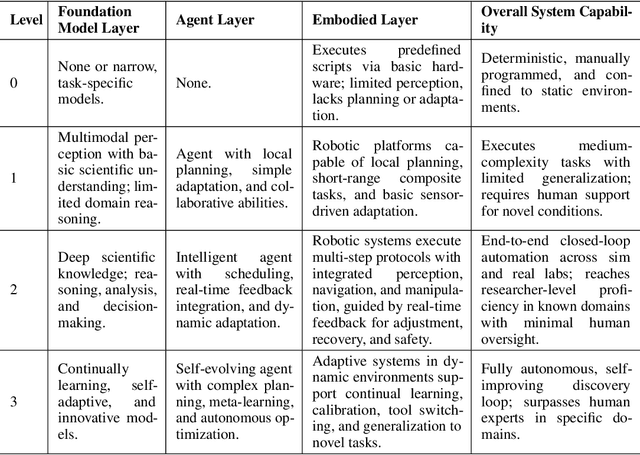
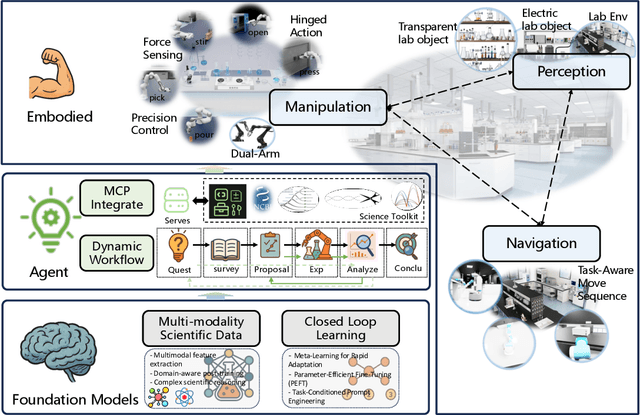
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
When Dynamic Data Selection Meets Data Augmentation
May 02, 2025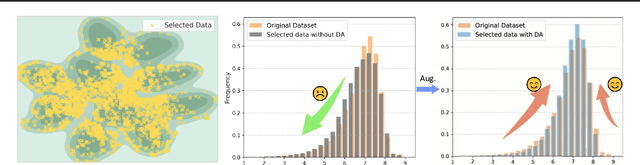
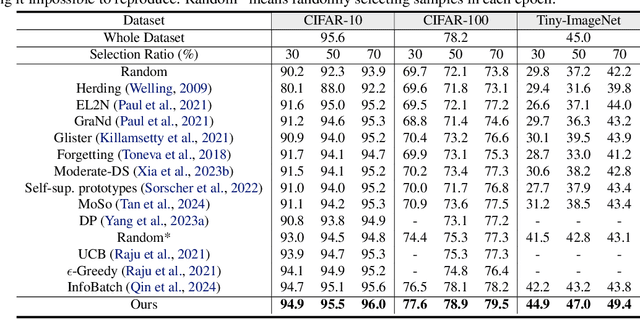
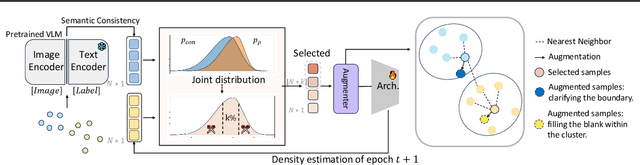
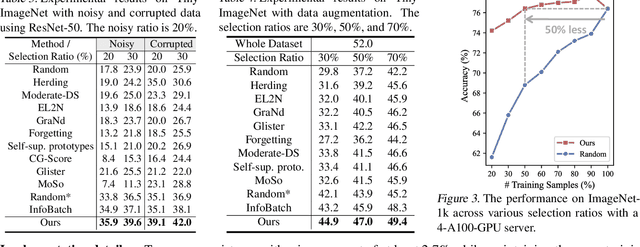
Dynamic data selection aims to accelerate training with lossless performance. However, reducing training data inherently limits data diversity, potentially hindering generalization. While data augmentation is widely used to enhance diversity, it is typically not optimized in conjunction with selection. As a result, directly combining these techniques fails to fully exploit their synergies. To tackle the challenge, we propose a novel online data training framework that, for the first time, unifies dynamic data selection and augmentation, achieving both training efficiency and enhanced performance. Our method estimates each sample's joint distribution of local density and multimodal semantic consistency, allowing for the targeted selection of augmentation-suitable samples while suppressing the inclusion of noisy or ambiguous data. This enables a more significant reduction in dataset size without sacrificing model generalization. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches on various benchmark datasets and architectures, e.g., reducing 50\% training costs on ImageNet-1k with lossless performance. Furthermore, our approach enhances noise resistance and improves model robustness, reinforcing its practical utility in real-world scenarios.
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning
Dec 02, 2024



Vision-language models (VLMs) have shown remarkable advancements in multimodal reasoning tasks. However, they still often generate inaccurate or irrelevant responses due to issues like hallucinated image understandings or unrefined reasoning paths. To address these challenges, we introduce Critic-V, a novel framework inspired by the Actor-Critic paradigm to boost the reasoning capability of VLMs. This framework decouples the reasoning process and critic process by integrating two independent components: the Reasoner, which generates reasoning paths based on visual and textual inputs, and the Critic, which provides constructive critique to refine these paths. In this approach, the Reasoner generates reasoning responses according to text prompts, which can evolve iteratively as a policy based on feedback from the Critic. This interaction process was theoretically driven by a reinforcement learning framework where the Critic offers natural language critiques instead of scalar rewards, enabling more nuanced feedback to boost the Reasoner's capability on complex reasoning tasks. The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked by Rule-based Reward~(RBR) to enhance its critic capabilities. Evaluation results show that the Critic-V framework significantly outperforms existing methods, including GPT-4V, on 5 out of 8 benchmarks, especially regarding reasoning accuracy and efficiency. Combining a dynamic text-based policy for the Reasoner and constructive feedback from the preference-optimized Critic enables a more reliable and context-sensitive multimodal reasoning process. Our approach provides a promising solution to enhance the reliability of VLMs, improving their performance in real-world reasoning-heavy multimodal applications such as autonomous driving and embodied intelligence.
Integrating Dual Prototypes for Task-Wise Adaption in Pre-Trained Model-Based Class-Incremental Learning
Nov 26, 2024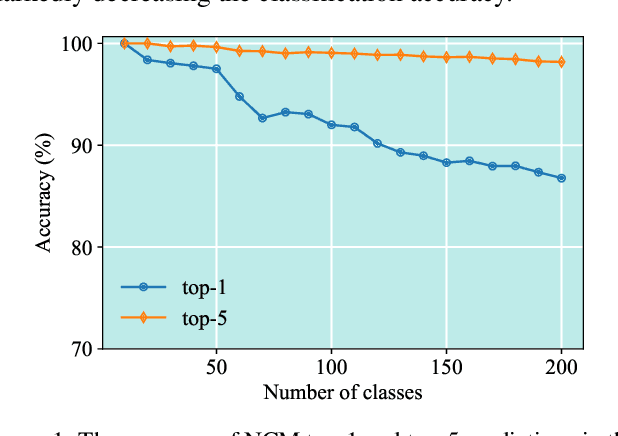
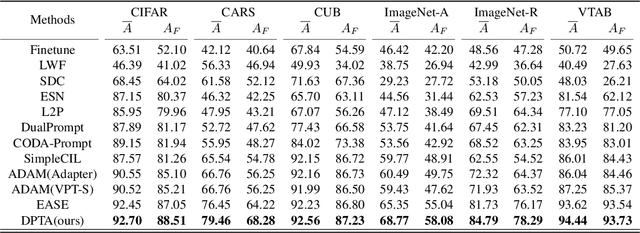
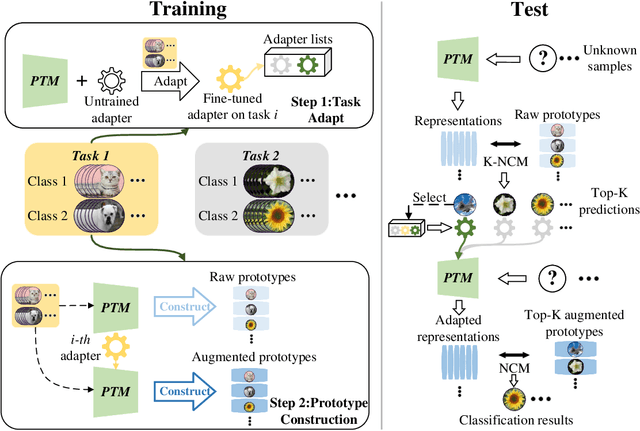
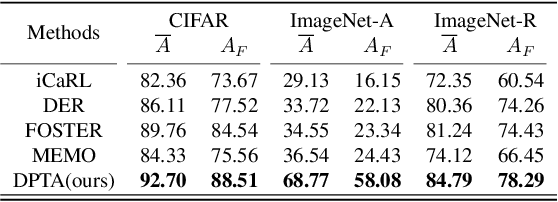
Class-incremental learning (CIL) aims to acquire new classes while conserving historical knowledge incrementally. Despite existing pre-trained model (PTM) based methods performing excellently in CIL, it is better to fine-tune them on downstream incremental tasks with massive patterns unknown to PTMs. However, using task streams for fine-tuning could lead to catastrophic forgetting that will erase the knowledge in PTMs. This paper proposes the Dual Prototype network for Task-wise Adaption (DPTA) of PTM-based CIL. For each incremental learning task, a task-wise adapter module is built to fine-tune the PTM, where the center-adapt loss forces the representation to be more centrally clustered and class separable. The dual prototype network improves the prediction process by enabling test-time adapter selection, where the raw prototypes deduce several possible task indexes of test samples to select suitable adapter modules for PTM, and the augmented prototypes that could separate highly correlated classes are utilized to determine the final result. Experiments on several benchmark datasets demonstrate the state-of-the-art performance of DPTA. The code will be open-sourced after the paper is published.
A CLIP-Powered Framework for Robust and Generalizable Data Selection
Oct 15, 2024



Large-scale datasets have been pivotal to the advancements of deep learning models in recent years, but training on such large datasets invariably incurs substantial storage and computational overhead. Meanwhile, real-world datasets often contain redundant and noisy data, imposing a negative impact on training efficiency and model performance. Data selection has shown promise in identifying the most representative samples from the entire dataset, which aims to minimize the performance gap with reduced training costs. Existing works typically rely on single-modality information to assign importance scores for individual samples, which may lead to inaccurate assessments, especially when dealing with noisy or corrupted samples. To address this limitation, we propose a novel CLIP-powered data selection framework that leverages multimodal information for more robust and generalizable sample selection. Specifically, our framework consists of three key modules-dataset adaptation, sample scoring, and selection optimization-that together harness extensive pre-trained multimodal knowledge to comprehensively assess sample influence and optimize the selection results through multi-objective optimization. Extensive experiments demonstrate that our approach consistently outperforms existing state-of-the-art baselines on various benchmark datasets. Notably, our method effectively removes noisy or damaged samples from the dataset, enabling it to achieve even higher performance with less data. This indicates that it is not only a way to accelerate training but can also improve overall data quality.