 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
LoRA Diffusion: Zero-Shot LoRA Synthesis for Diffusion Model Personalization
Dec 03, 2024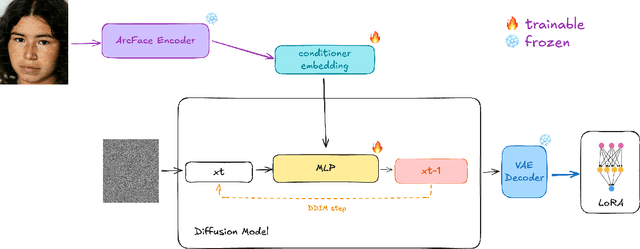
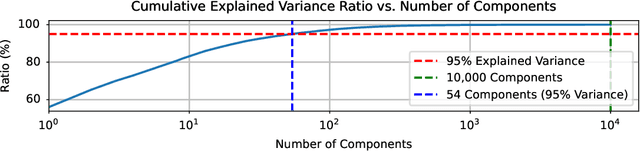
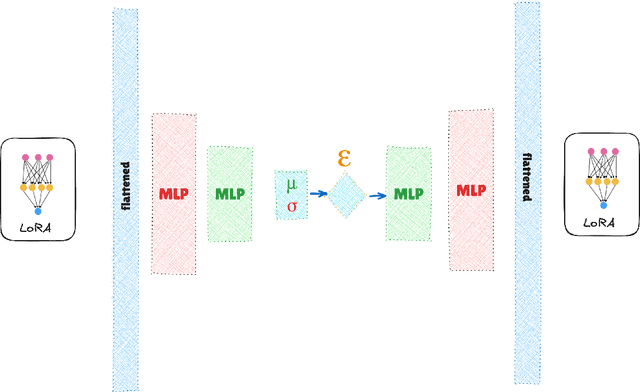
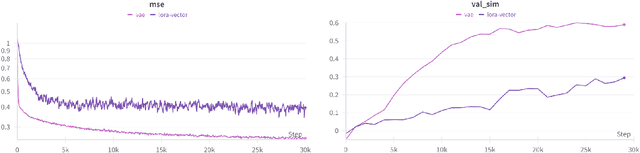
Low-Rank Adaptation (LoRA) and other parameter-efficient fine-tuning (PEFT) methods provide low-memory, storage-efficient solutions for personalizing text-to-image models. However, these methods offer little to no improvement in wall-clock training time or the number of steps needed for convergence compared to full model fine-tuning. While PEFT methods assume that shifts in generated distributions (from base to fine-tuned models) can be effectively modeled through weight changes in a low-rank subspace, they fail to leverage knowledge of common use cases, which typically focus on capturing specific styles or identities. Observing that desired outputs often comprise only a small subset of the possible domain covered by LoRA training, we propose reducing the search space by incorporating a prior over regions of interest. We demonstrate that training a hypernetwork model to generate LoRA weights can achieve competitive quality for specific domains while enabling near-instantaneous conditioning on user input, in contrast to traditional training methods that require thousands of steps.
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning
Dec 02, 2024



Vision-language models (VLMs) have shown remarkable advancements in multimodal reasoning tasks. However, they still often generate inaccurate or irrelevant responses due to issues like hallucinated image understandings or unrefined reasoning paths. To address these challenges, we introduce Critic-V, a novel framework inspired by the Actor-Critic paradigm to boost the reasoning capability of VLMs. This framework decouples the reasoning process and critic process by integrating two independent components: the Reasoner, which generates reasoning paths based on visual and textual inputs, and the Critic, which provides constructive critique to refine these paths. In this approach, the Reasoner generates reasoning responses according to text prompts, which can evolve iteratively as a policy based on feedback from the Critic. This interaction process was theoretically driven by a reinforcement learning framework where the Critic offers natural language critiques instead of scalar rewards, enabling more nuanced feedback to boost the Reasoner's capability on complex reasoning tasks. The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked by Rule-based Reward~(RBR) to enhance its critic capabilities. Evaluation results show that the Critic-V framework significantly outperforms existing methods, including GPT-4V, on 5 out of 8 benchmarks, especially regarding reasoning accuracy and efficiency. Combining a dynamic text-based policy for the Reasoner and constructive feedback from the preference-optimized Critic enables a more reliable and context-sensitive multimodal reasoning process. Our approach provides a promising solution to enhance the reliability of VLMs, improving their performance in real-world reasoning-heavy multimodal applications such as autonomous driving and embodied intelligence.
LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning
Oct 03, 2024



This paper presents an advanced mathematical problem-solving framework, LLaMA-Berry, for enhancing the mathematical reasoning ability of Large Language Models (LLMs). The framework combines Monte Carlo Tree Search (MCTS) with iterative Self-Refine to optimize the reasoning path and utilizes a pairwise reward model to evaluate different paths globally. By leveraging the self-critic and rewriting capabilities of LLMs, Self-Refine applied to MCTS (SR-MCTS) overcomes the inefficiencies and limitations of conventional step-wise and greedy search algorithms by fostering a more efficient exploration of solution spaces. Pairwise Preference Reward Model~(PPRM), inspired by Reinforcement Learning from Human Feedback (RLHF), is then used to model pairwise preferences between solutions, utilizing an Enhanced Borda Count (EBC) method to synthesize these preferences into a global ranking score to find better answers. This approach addresses the challenges of scoring variability and non-independent distributions in mathematical reasoning tasks. The framework has been tested on general and advanced benchmarks, showing superior performance in terms of search efficiency and problem-solving capability compared to existing methods like ToT and rStar, particularly in complex Olympiad-level benchmarks, including GPQA, AIME24 and AMC23.