 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying Lens on Supervised Fine-Tuning Through Target Distribution Design
Jun 09, 2026Supervised fine-tuning (SFT) typically maximizes the likelihood of every token in a demonstrated trajectory. However, an observed token can be non-unique, noisy, or misaligned with the model prior. Strictly fitting toward this one-hot target may be suboptimal, especially when the pretrained model encodes a rich knowledge prior. In this work, we reinterpret SFT as target distribution design: instead of studying only the loss objective, we analyze the token-level target that the loss drives the model to match. We introduce the Q-target framework, which decomposes SFT supervision into two explicit choices: (1) how strongly to rely on the observed token, and (2) how to allocate the remaining probability mass over alternatives. This perspective unifies many existing SFT variants as implicit choices of the target distribution Q. Building on this view, we propose Target-SFT which constructs the training objective directly from the desired target distribution. This method consistently outperforms across the ten reasoning dataset-model settings evaluated, showing the effectiveness of this target-based approach. Overall, our formulation reveals a more fundamental design principle for SFT training and opens a broader search space for SFT objectives.
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
KEEP: A KV-Cache-Centric Memory Management System for Efficient Embodied Planning
Feb 27, 2026Memory-augmented Large Language Models (LLMs) have demonstrated remarkable capability for complex and long-horizon embodied planning. By keeping track of past experiences and environmental states, memory enables LLMs to maintain a global view, thereby avoiding repetitive exploration. However, existing approaches often store the memory as raw text, leading to excessively long prompts and high prefill latency. While it is possible to store and reuse the KV caches, the efficiency benefits are greatly undermined due to frequent KV cache updates. In this paper, we propose KEEP, a KV-cache-centric memory management system for efficient embodied planning. KEEP features 3 key innovations: (1) a Static-Dynamic Memory Construction algorithm that reduces KV cache recomputation by mixed-granularity memory group; (2) a Multi-hop Memory Re-computation algorithm that dynamically identifies important cross-attention among different memory groups and reconstructs memory interactions iteratively; (3) a Layer-balanced Memory Loading that eliminates unbalanced KV cache loading and cross-attention computation across different layers. Extensive experimental results have demonstrated that KEEP achieves 2.68x speedup with negligible accuracy loss compared with text-based memory methods on ALFRED dataset. Compared with the KV re-computation method CacheBlend (EuroSys'25), KEEP shows 4.13% success rate improvement and 1.90x time-to-first-token (TTFT) reduction. Our code is available on https://github.com/PKU-SEC-Lab/KEEP_Embodied_Memory.
DySL-VLA: Efficient Vision-Language-Action Model Inference via Dynamic-Static Layer-Skipping for Robot Manipulation
Feb 26, 2026Vision-Language-Action (VLA) models have shown remarkable success in robotic tasks like manipulation by fusing a language model's reasoning with a vision model's 3D understanding. However, their high computational cost remains a major obstacle for real-world applications that require real-time performance. We observe that the actions within a task have varying levels of importance: critical steps demand high precision, while less important ones can tolerate more variance. Leveraging this insight, we propose DySL-VLA, a novel framework that addresses computational cost by dynamically skipping VLA layers based on each action's importance. DySL-VLA categorizes its layers into two types: informative layers, which are consistently executed, and incremental layers, which can be selectively skipped. To intelligently skip layers without sacrificing accuracy, we invent a prior-post skipping guidance mechanism to determine when to initiate layer-skipping. We also propose a skip-aware two-stage knowledge distillation algorithm to efficiently train a standard VLA into a DySL-VLA. Our experiments indicate that DySL-VLA achieves 2.1% improvement in success length over Deer-VLA on the Calvin dataset, while simultaneously reducing trainable parameters by a factor of 85.7 and providing a 3.75x speedup relative to the RoboFlamingo baseline at iso-accuracy. Our code is available on https://github.com/PKU-SEC-Lab/DYSL_VLA.
ELSA: Efficient LLM-Centric Split Aggregation for Privacy-Aware Hierarchical Federated Learning over Resource-Constrained Edge Networks
Jan 20, 2026Training large language models (LLMs) at the network edge faces fundamental challenges arising from device resource constraints, severe data heterogeneity, and heightened privacy risks. To address these, we propose ELSA (Efficient LLM-centric Split Aggregation), a novel framework that systematically integrates split learning (SL) and hierarchical federated learning (HFL) for distributed LLM fine-tuning over resource-constrained edge networks. ELSA introduces three key innovations. First, it employs a task-agnostic, behavior-aware client clustering mechanism that constructs semantic fingerprints using public probe inputs and symmetric KL divergence, further enhanced by prediction-consistency-based trust scoring and latency-aware edge assignment to jointly address data heterogeneity, client unreliability, and communication constraints. Second, it splits the LLM into three parts across clients and edge servers, with the cloud used only for adapter aggregation, enabling an effective balance between on-device computation cost and global convergence stability. Third, it incorporates a lightweight communication scheme based on computational sketches combined with semantic subspace orthogonal perturbation (SS-OP) to reduce communication overhead while mitigating privacy leakage during model exchanges. Experiments across diverse NLP tasks demonstrate that ELSA consistently outperforms state-of-the-art methods in terms of adaptability, convergence behavior, and robustness, establishing a scalable and privacy-aware solution for edge-side LLM fine-tuning under resource constraints.
MiST: Understanding the Role of Mid-Stage Scientific Training in Developing Chemical Reasoning Models
Dec 24, 2025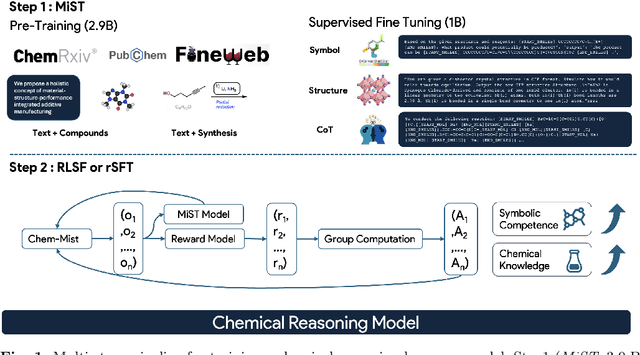
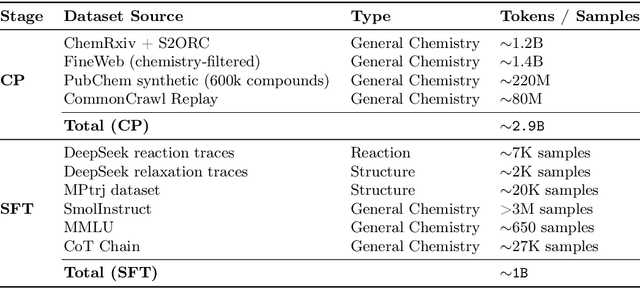
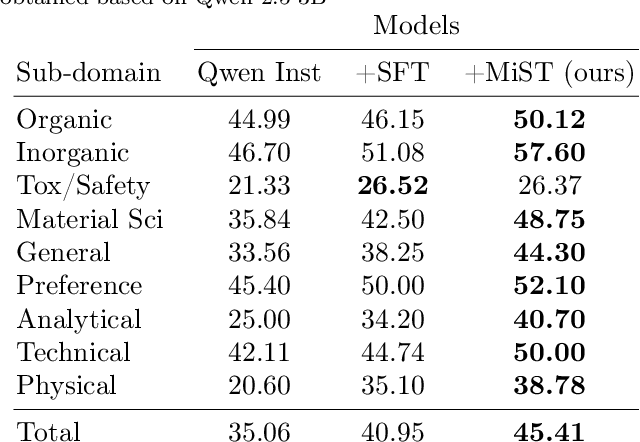
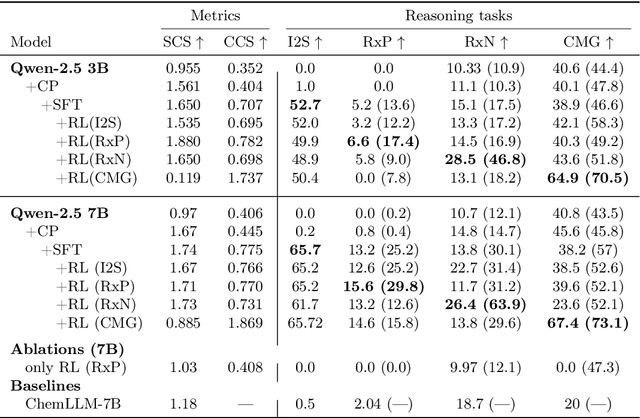
Large Language Models can develop reasoning capabilities through online fine-tuning with rule-based rewards. However, recent studies reveal a critical constraint: reinforcement learning succeeds only when the base model already assigns non-negligible probability to correct answers -- a property we term 'latent solvability'. This work investigates the emergence of chemical reasoning capabilities and what these prerequisites mean for chemistry. We identify two necessary conditions for RL-based chemical reasoning: 1) Symbolic competence, and 2) Latent chemical knowledge. We propose mid-stage scientific training (MiST): a set of mid-stage training techniques to satisfy these, including data-mixing with SMILES/CIF-aware pre-processing, continued pre-training on 2.9B tokens, and supervised fine-tuning on 1B tokens. These steps raise the latent-solvability score on 3B and 7B models by up to 1.8x, and enable RL to lift top-1 accuracy from 10.9 to 63.9% on organic reaction naming, and from 40.6 to 67.4% on inorganic material generation. Similar results are observed for other challenging chemical tasks, while producing interpretable reasoning traces. Our results define clear prerequisites for chemical reasoning training and highlight the broader role of mid-stage training in unlocking reasoning capabilities.
AtomWorld: A Benchmark for Evaluating Spatial Reasoning in Large Language Models on Crystalline Materials
Oct 06, 2025

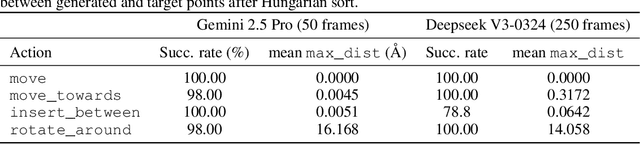
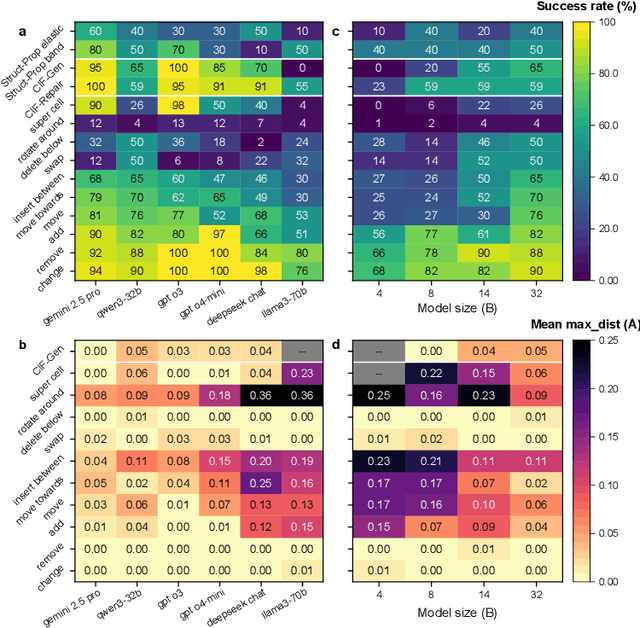
Large Language Models (LLMs) excel at textual reasoning and are beginning to develop spatial understanding, prompting the question of whether these abilities can be combined for complex, domain-specific tasks. This question is essential in fields like materials science, where deep understanding of 3D atomic structures is fundamental. While initial studies have successfully applied LLMs to tasks involving pure crystal generation or coordinate understandings, a standardized benchmark to systematically evaluate their core reasoning abilities across diverse atomic structures has been notably absent. To address this gap, we introduce the AtomWorld benchmark to evaluate LLMs on tasks based in Crystallographic Information Files (CIFs), a standard structure representation format. These tasks, including structural editing, CIF perception, and property-guided modeling, reveal a critical limitation: current models, despite establishing promising baselines, consistently fail in structural understanding and spatial reasoning. Our experiments show that these models make frequent errors on structure modification tasks, and even in the basic CIF format understandings, potentially leading to cumulative errors in subsequent analysis and materials insights. By defining these standardized tasks, AtomWorld lays the ground for advancing LLMs toward robust atomic-scale modeling, crucial for accelerating materials research and automating scientific workflows.
DrugMCTS: a drug repurposing framework combining multi-agent, RAG and Monte Carlo Tree Search
Jul 10, 2025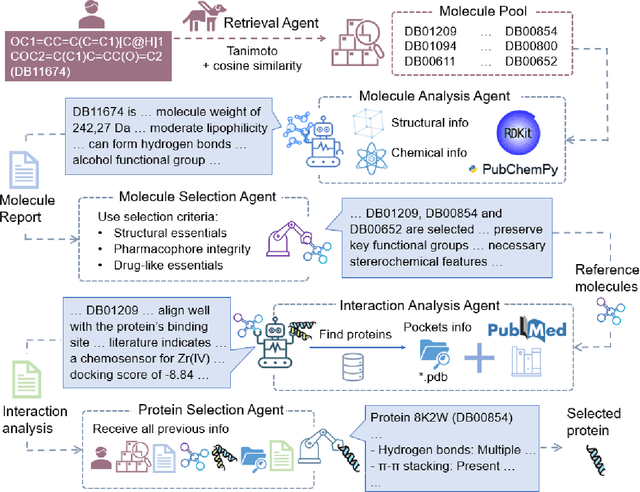
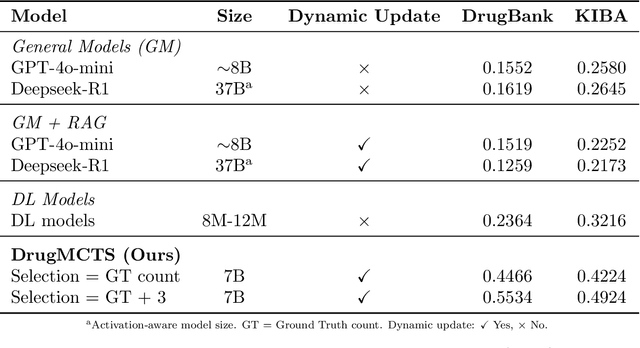

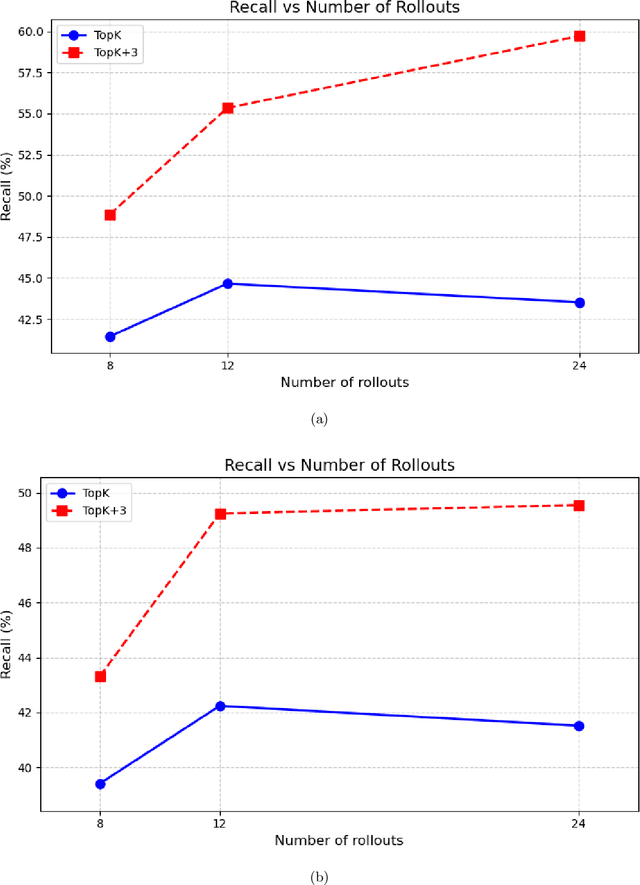
Recent advances in large language models have demonstrated considerable potential in scientific domains such as drug discovery. However, their effectiveness remains constrained when reasoning extends beyond the knowledge acquired during pretraining. Conventional approaches, such as fine-tuning or retrieval-augmented generation, face limitations in either imposing high computational overhead or failing to fully exploit structured scientific data. To overcome these challenges, we propose DrugMCTS, a novel framework that synergistically integrates RAG, multi-agent collaboration, and Monte Carlo Tree Search for drug repurposing. The framework employs five specialized agents tasked with retrieving and analyzing molecular and protein information, thereby enabling structured and iterative reasoning. Without requiring domain-specific fine-tuning, DrugMCTS empowers Qwen2.5-7B-Instruct to outperform Deepseek-R1 by over 20\%. Extensive experiments on the DrugBank and KIBA datasets demonstrate that DrugMCTS achieves substantially higher recall and robustness compared to both general-purpose LLMs and deep learning baselines. Our results highlight the importance of structured reasoning, agent-based collaboration, and feedback-driven search mechanisms in advancing LLM applications for drug discovery.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025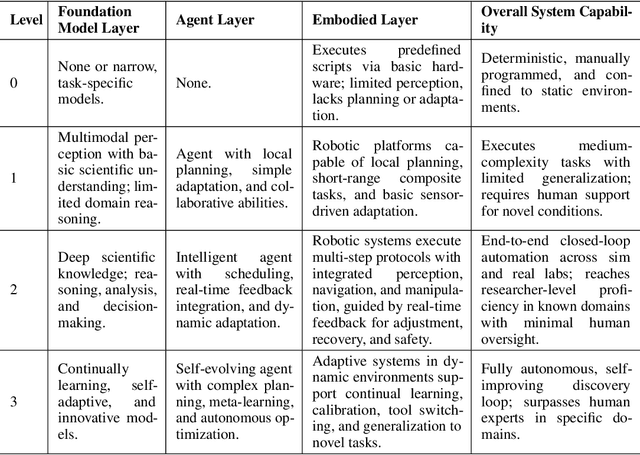
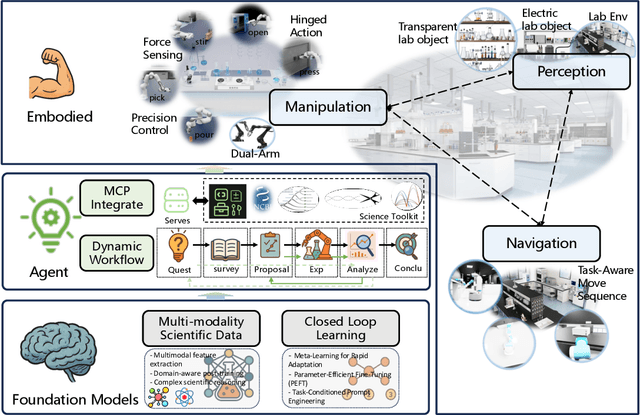
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
CheMatAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 12, 2025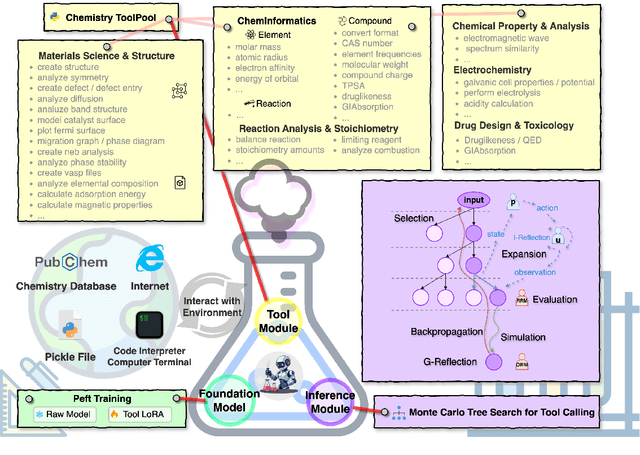
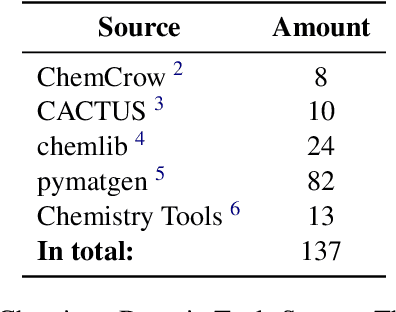
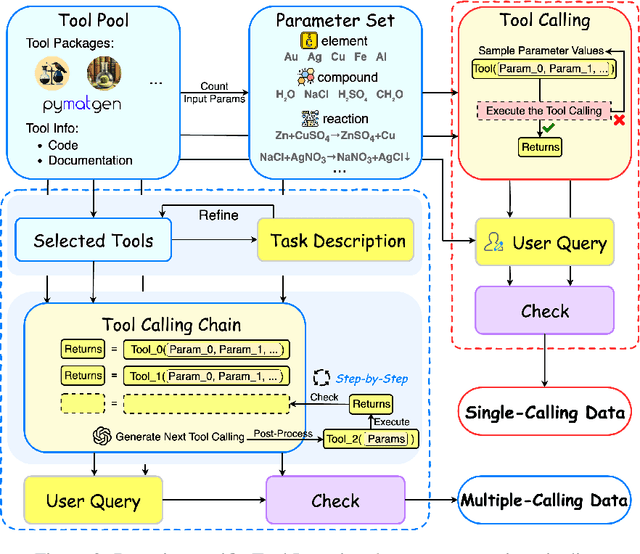
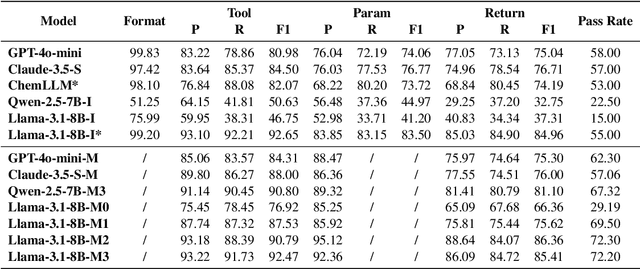
Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .