 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Shifts, Large Gains: Unlocking Traditional TSP Heuristic Guided-Sampling via Unsupervised Neural Instance Modification
Jan 31, 2026The Traveling Salesman Problem (TSP) is one of the most representative NP-hard problems in route planning and a long-standing benchmark in combinatorial optimization. Traditional heuristic tour constructors, such as Farthest or Nearest Insertion, are computationally efficient and highly practical, but their deterministic behavior limits exploration and often leads to local optima. In contrast, neural-based heuristic tour constructors alleviate this issue through guided-sampling and typically achieve superior solution quality, but at the cost of extensive training and reliance on ground-truth supervision, hindering their practical use. To bridge this gap, we propose TSP-MDF, a novel instance modification framework that equips traditional deterministic heuristic tour constructors with guided-sampling capability. Specifically, TSP-MDF introduces a neural-based instance modifier that strategically shifts node coordinates to sample multiple modified instances, on which the base traditional heuristic tour constructor constructs tours that are mapped back to the original instance, allowing traditional tour constructors to explore higher-quality tours and escape local optima. At the same time, benefiting from our instance modification formulation, the neural-based instance modifier can be trained efficiently without any ground-truth supervision, ensuring the framework maintains practicality. Extensive experiments on large-scale TSP benchmarks and real-world benchmarks demonstrate that TSP-MDF significantly improves the performance of traditional heuristics tour constructors, achieving solution quality comparable to neural-based heuristic tour constructors, but with an extremely short training time.
PrivGemo: Privacy-Preserving Dual-Tower Graph Retrieval for Empowering LLM Reasoning with Memory Augmentation
Jan 13, 2026Knowledge graphs (KGs) provide structured evidence that can ground large language model (LLM) reasoning for knowledge-intensive question answering. However, many practical KGs are private, and sending retrieved triples or exploration traces to closed-source LLM APIs introduces leakage risk. Existing privacy treatments focus on masking entity names, but they still face four limitations: structural leakage under semantic masking, uncontrollable remote interaction, fragile multi-hop and multi-entity reasoning, and limited experience reuse for stability and efficiency. To address these issues, we propose PrivGemo, a privacy-preserving retrieval-augmented framework for KG-grounded reasoning with memory-guided exposure control. PrivGemo uses a dual-tower design to keep raw KG knowledge local while enabling remote reasoning over an anonymized view that goes beyond name masking to limit both semantic and structural exposure. PrivGemo supports multi-hop, multi-entity reasoning by retrieving anonymized long-hop paths that connect all topic entities, while keeping grounding and verification on the local KG. A hierarchical controller and a privacy-aware experience memory further reduce unnecessary exploration and remote interactions. Comprehensive experiments on six benchmarks show that PrivGemo achieves overall state-of-the-art results, outperforming the strongest baseline by up to 17.1%. Furthermore, PrivGemo enables smaller models (e.g., Qwen3-4B) to achieve reasoning performance comparable to that of GPT-4-Turbo.
Beyond Homophily: Community Search on Heterophilic Graphs
Jan 05, 2026Community search aims to identify a refined set of nodes that are most relevant to a given query, supporting tasks ranging from fraud detection to recommendation. Unlike homophilic graphs, many real-world networks are heterophilic, where edges predominantly connect dissimilar nodes. Therefore, structural signals that once reflected smooth, low-frequency similarity now appear as sharp, high-frequency contrasts. However, both classical algorithms (e.g., k-core, k-truss) and recent ML-based models struggle to achieve effective community search on heterophilic graphs, where edge signs or semantics are generally unknown. Algorithm-based methods often return communities with mixed class labels, while GNNs, built on homophily, smooth away meaningful signals and blur community boundaries. Therefore, we propose Adaptive Community Search (AdaptCS), a unified framework featuring three key designs: (i) an AdaptCS Encoder that disentangles multi-hop and multi-frequency signals, enabling the model to capture both smooth (homophilic) and contrastive (heterophilic) relations; (ii) a memory-efficient low-rank optimization that removes the main computational bottleneck and ensures model scalability; and (iii) an Adaptive Community Score (ACS) that guides online search by balancing embedding similarity and topological relations. Extensive experiments on both heterophilic and homophilic benchmarks demonstrate that AdaptCS outperforms the best-performing baseline by an average of 11% in F1-score, retains robustness across heterophily levels, and achieves up to 2 orders of magnitude speedup.
HyperJoin: LLM-augmented Hypergraph Link Prediction for Joinable Table Discovery
Jan 03, 2026As a pivotal task in data lake management, joinable table discovery has attracted widespread interest. While existing language model-based methods achieve remarkable performance by combining offline column representation learning with online ranking, their design insufficiently accounts for the underlying structural interactions: (1) offline, they directly model tables into isolated or pairwise columns, thereby struggling to capture the rich inter-table and intra-table structural information; and (2) online, they rank candidate columns based solely on query-candidate similarity, ignoring the mutual interactions among the candidates, leading to incoherent result sets. To address these limitations, we propose HyperJoin, a large language model (LLM)-augmented Hypergraph framework for Joinable table discovery. Specifically, we first construct a hypergraph to model tables using both the intra-table hyperedges and the LLM-augmented inter-table hyperedges. Consequently, the task of joinable table discovery is formulated as link prediction on this constructed hypergraph. We then design HIN, a Hierarchical Interaction Network that learns expressive column representations through bidirectional message passing over columns and hyperedges. To strengthen coherence and internal consistency in the result columns, we cast online ranking as a coherence-aware top-k column selection problem. We then introduce a reranking module that leverages a maximum spanning tree algorithm to prune noisy connections and maximize coherence. Experiments demonstrate the superiority of HyperJoin, achieving average improvements of 21.4% (Precision@15) and 17.2% (Recall@15) over the best baseline.
MiST: Understanding the Role of Mid-Stage Scientific Training in Developing Chemical Reasoning Models
Dec 24, 2025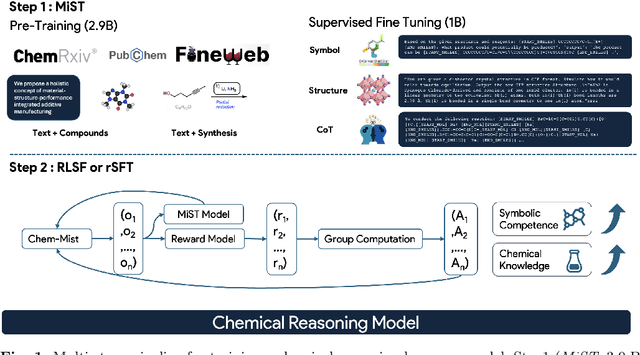
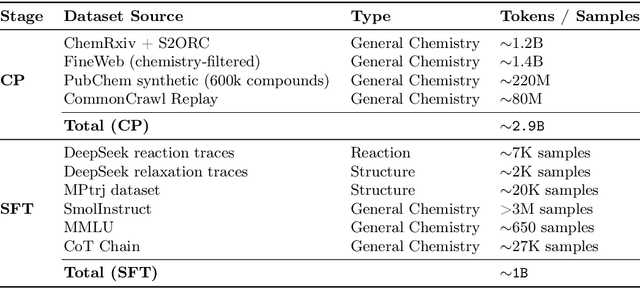
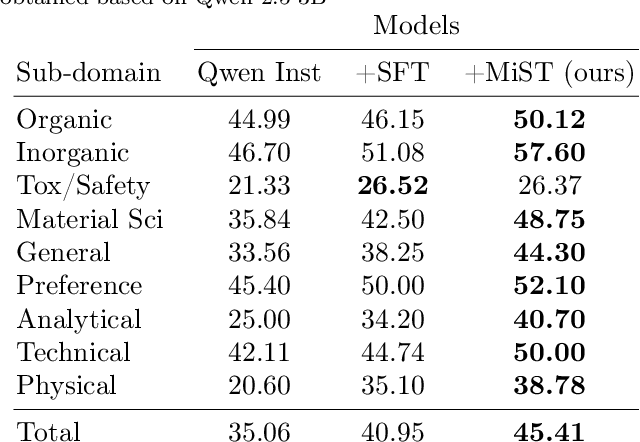
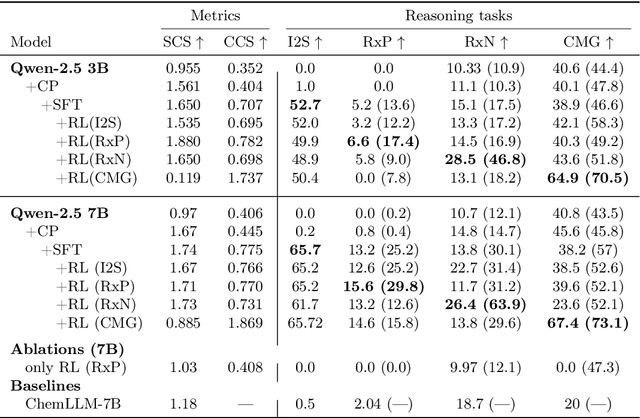
Large Language Models can develop reasoning capabilities through online fine-tuning with rule-based rewards. However, recent studies reveal a critical constraint: reinforcement learning succeeds only when the base model already assigns non-negligible probability to correct answers -- a property we term 'latent solvability'. This work investigates the emergence of chemical reasoning capabilities and what these prerequisites mean for chemistry. We identify two necessary conditions for RL-based chemical reasoning: 1) Symbolic competence, and 2) Latent chemical knowledge. We propose mid-stage scientific training (MiST): a set of mid-stage training techniques to satisfy these, including data-mixing with SMILES/CIF-aware pre-processing, continued pre-training on 2.9B tokens, and supervised fine-tuning on 1B tokens. These steps raise the latent-solvability score on 3B and 7B models by up to 1.8x, and enable RL to lift top-1 accuracy from 10.9 to 63.9% on organic reaction naming, and from 40.6 to 67.4% on inorganic material generation. Similar results are observed for other challenging chemical tasks, while producing interpretable reasoning traces. Our results define clear prerequisites for chemical reasoning training and highlight the broader role of mid-stage training in unlocking reasoning capabilities.
RP-CATE: Recurrent Perceptron-based Channel Attention Transformer Encoder for Industrial Hybrid Modeling
Dec 22, 2025Nowadays, industrial hybrid modeling which integrates both mechanistic modeling and machine learning-based modeling techniques has attracted increasing interest from scholars due to its high accuracy, low computational cost, and satisfactory interpretability. Nevertheless, the existing industrial hybrid modeling methods still face two main limitations. First, current research has mainly focused on applying a single machine learning method to one specific task, failing to develop a comprehensive machine learning architecture suitable for modeling tasks, which limits their ability to effectively represent complex industrial scenarios. Second, industrial datasets often contain underlying associations (e.g., monotonicity or periodicity) that are not adequately exploited by current research, which can degrade model's predictive performance. To address these limitations, this paper proposes the Recurrent Perceptron-based Channel Attention Transformer Encoder (RP-CATE), with three distinctive characteristics: 1: We developed a novel architecture by replacing the self-attention mechanism with channel attention and incorporating our proposed Recurrent Perceptron (RP) Module into Transformer, achieving enhanced effectiveness for industrial modeling tasks compared to the original Transformer. 2: We proposed a new data type called Pseudo-Image Data (PID) tailored for channel attention requirements and developed a cyclic sliding window method for generating PID. 3: We introduced the concept of Pseudo-Sequential Data (PSD) and a method for converting industrial datasets into PSD, which enables the RP Module to capture the underlying associations within industrial dataset more effectively. An experiment aimed at hybrid modeling in chemical engineering was conducted by using RP-CATE and the experimental results demonstrate that RP-CATE achieves the best performance compared to other baseline models.
FADTI: Fourier and Attention Driven Diffusion for Multivariate Time Series Imputation
Dec 17, 2025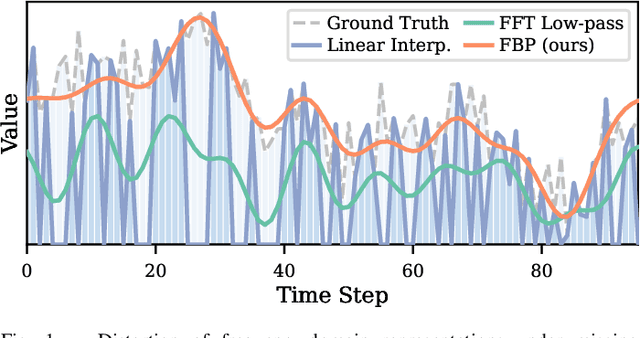
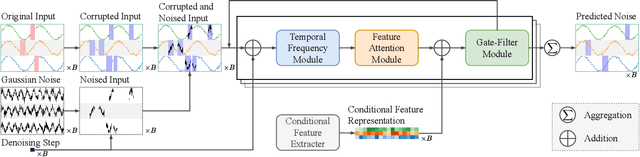

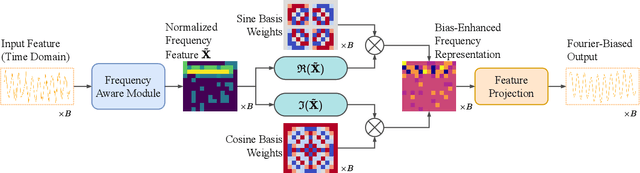
Multivariate time series imputation is fundamental in applications such as healthcare, traffic forecasting, and biological modeling, where sensor failures and irregular sampling lead to pervasive missing values. However, existing Transformer- and diffusion-based models lack explicit inductive biases and frequency awareness, limiting their generalization under structured missing patterns and distribution shifts. We propose FADTI, a diffusion-based framework that injects frequency-informed feature modulation via a learnable Fourier Bias Projection (FBP) module and combines it with temporal modeling through self-attention and gated convolution. FBP supports multiple spectral bases, enabling adaptive encoding of both stationary and non-stationary patterns. This design injects frequency-domain inductive bias into the generative imputation process. Experiments on multiple benchmarks, including a newly introduced biological time series dataset, show that FADTI consistently outperforms state-of-the-art methods, particularly under high missing rates. Code is available at https://anonymous.4open.science/r/TimeSeriesImputation-52BF
Ensembling LLM-Induced Decision Trees for Explainable and Robust Error Detection
Dec 08, 2025Error detection (ED), which aims to identify incorrect or inconsistent cell values in tabular data, is important for ensuring data quality. Recent state-of-the-art ED methods leverage the pre-trained knowledge and semantic capability embedded in large language models (LLMs) to directly label whether a cell is erroneous. However, this LLM-as-a-labeler pipeline (1) relies on the black box, implicit decision process, thus failing to provide explainability for the detection results, and (2) is highly sensitive to prompts, yielding inconsistent outputs due to inherent model stochasticity, therefore lacking robustness. To address these limitations, we propose an LLM-as-an-inducer framework that adopts LLM to induce the decision tree for ED (termed TreeED) and further ensembles multiple such trees for consensus detection (termed ForestED), thereby improving explainability and robustness. Specifically, based on prompts derived from data context, decision tree specifications and output requirements, TreeED queries the LLM to induce the decision tree skeleton, whose root-to-leaf decision paths specify the stepwise procedure for evaluating a given sample. Each tree contains three types of nodes: (1) rule nodes that perform simple validation checks (e.g., format or range), (2) Graph Neural Network (GNN) nodes that capture complex patterns (e.g., functional dependencies), and (3) leaf nodes that output the final decision types (error or clean). Furthermore, ForestED employs uncertainty-based sampling to obtain multiple row subsets, constructing a decision tree for each subset using TreeED. It then leverages an Expectation-Maximization-based algorithm that jointly estimates tree reliability and optimizes the consensus ED prediction. Extensive xperiments demonstrate that our methods are accurate, explainable and robust, achieving an average F1-score improvement of 16.1% over the best baseline.
PRoH: Dynamic Planning and Reasoning over Knowledge Hypergraphs for Retrieval-Augmented Generation
Oct 14, 2025Knowledge Hypergraphs (KHs) have recently emerged as a knowledge representation for retrieval-augmented generation (RAG), offering a paradigm to model multi-entity relations into a structured form. However, existing KH-based RAG methods suffer from three major limitations: static retrieval planning, non-adaptive retrieval execution, and superficial use of KH structure and semantics, which constrain their ability to perform effective multi-hop question answering. To overcome these limitations, we propose PRoH, a dynamic Planning and Reasoning over Knowledge Hypergraphs framework. PRoH incorporates three core innovations: (i) a context-aware planning module that sketches the local KH neighborhood to guide structurally grounded reasoning plan generation; (ii) a structured question decomposition process that organizes subquestions as a dynamically evolving Directed Acyclic Graph (DAG) to enable adaptive, multi-trajectory exploration; and (iii) an Entity-Weighted Overlap (EWO)-guided reasoning path retrieval algorithm that prioritizes semantically coherent hyperedge traversals. Experiments across multiple domains demonstrate that PRoH achieves state-of-the-art performance, surpassing the prior SOTA model HyperGraphRAG by an average of 19.73% in F1 and 8.41% in Generation Evaluation (G-E) score, while maintaining strong robustness in long-range multi-hop reasoning tasks.
DHG-Bench: A Comprehensive Benchmark on Deep Hypergraph Learning
Aug 17, 2025Although conventional deep graph models have achieved great success in relational learning, their focus on pairwise relationships limits their capacity to learn pervasive higher-order interactions in real-world complex systems, which can be naturally modeled as hypergraphs. To tackle this, hypergraph neural networks (HNNs), the dominant approach in deep hypergraph learning (DHGL), has garnered substantial attention in recent years. Despite the proposal of numerous HNN methods, there is no comprehensive benchmark for HNNs, which creates a great obstacle to understanding the progress of DHGL in several aspects: (i) insufficient coverage of datasets, algorithms, and tasks; (ii) a narrow evaluation of algorithm performance; and (iii) inconsistent dataset usage, preprocessing, and experimental setups that hinder comparability. To fill the gap, we introduce DHG-Bench, the first comprehensive benchmark for DHGL. Specifically, DHG-Bench integrates 20 diverse datasets spanning node-, edge-, and graph-level tasks, along with 16 state-of-the-art HNN algorithms, under consistent data processing and experimental protocols. Our benchmark systematically investigates the characteristics of HNNs in terms of four dimensions: effectiveness, efficiency, robustness, and fairness. Further, to facilitate reproducible research, we have developed an easy-to-use library for training and evaluating different HNN methods. Extensive experiments conducted with DHG-Bench reveal both the strengths and inherent limitations of existing algorithms, offering valuable insights and directions for future research. The code is publicly available at: https://github.com/Coco-Hut/DHG-Bench.