 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Prior Denoising for Smooth Real-Time Chunking
May 25, 2026Real-time chunking (RTC) lets chunked action policies operate under inference delay by conditioning a newly generated action chunk on actions already committed by the previous chunk. Training-time RTC simulates this delay during learning and avoids expensive guidance at deployment, but its binary prefix mask treats all non-prefix tokens as fully unconstrained. This under-models asynchronous execution: early overlap actions are fixed, while later overlap actions remain editable but should still stay close to the previous plan. We propose Soft RTC, a training-time RTC generalization based on action-prior denoising. Soft RTC constructs corrupted overlap tokens from partially denoised states instead of pure noise and injects the aligned previous chunk as the same prior during inference through a lightweight token-wise blending rule. On the 12 released large Kinetix levels, a short soft window nearly matches hard training-time RTC in overall solve rate (0.809 vs. 0.815), while a medium window reduces high-delay action delta and jerk by 9.1% and 9.6% relative to hard RTC. Both variants keep near-naive runtime, unlike inference-time RTC baselines. A small preliminary real-robot sorting study provides additional evidence that training-time RTC can improve completion and that Soft RTC gives the lowest commanded-action finite-difference metrics among the tested policies.
Case-Aware Medical Image Classification with Multimodal Knowledge Graphs and Reliability-Guided Refinement
May 21, 2026Deep learning has brought significant progress to medical image classification, yet most existing methods still rely on isolated visual evidence and cannot effectively leverage similar cases or external knowledge. In clinical practice, diagnosis is typically supported by historical similar cases and their associated symptoms. To simulate this diagnostic process, we propose a framework that performs case-aware reasoning using multimodal knowledge graphs for explainable medical image diagnosis. Given an input image, our method constructs a multimodal knowledge graph from adaptively retrieved similar cases, enabling more effective utilization of related samples. We further introduce a knowledge propagation and injection mechanism, where an image-centric Graph Attention Network propagates knowledge semantics to obtain case-based features, followed by a bidirectional cross-modal attention mechanism that injects these features into visual representations for cross-modal alignment. To mitigate noisy retrieval, we design a confidence-calibrated decision refinement scheme that estimates the reliability of each retrieved case by jointly considering prediction confidence and sample similarity, adaptively adjusting its contribution to the final prediction and providing interpretable case-level evidence. Extensive experiments on multiple medical imaging datasets show that our approach consistently outperforms strong baselines, and ablation studies validate the effectiveness of each component. The source code is publicly available at https://anonymous.4open.science/r/MKG-CARE-8B7B.
DSAINet: An Efficient Dual-Scale Attentive Interaction Network for General EEG Decoding
Apr 20, 2026In real-world applications of noninvasive electroencephalography (EEG), specialized decoders often show limited generalizability across diverse tasks under subject-independent settings. One central challenge is that task-relevant EEG signals often follow different temporal organization patterns across tasks, while many existing methods rely on task-tailored architectural designs that introduce task-specific temporal inductive biases. This mismatch makes it difficult to adapt temporal modeling across tasks without changing the model configuration. To address these challenges, we propose DSAINet, an efficient dual-scale attentive interaction network for general EEG decoding. Specifically, DSAINet constructs shared spatiotemporal token representations from raw EEG signals and models diverse temporal dynamics through parallel convolutional branches at fine and coarse scales. The resulting representations are then adaptively refined by intra-branch attention to emphasize salient scale-specific patterns and by inter-branch attention to integrate task-relevant features across scales, followed by adaptive token aggregation to yield a compact representation for prediction. Extensive experiments on five downstream EEG decoding tasks across ten public datasets show that DSAINet consistently outperforms 13 representative baselines under strict subject-independent evaluation. Notably, this performance is achieved using the same architecture hyperparameters across datasets. Moreover, DSAINet achieves a favorable accuracy-efficiency trade-off with only about 77K trainable parameters and provides interpretable neurophysiological insights. The code is publicly available at https://github.com/zy0929/DSAINet.
A multimodal slice discovery framework for systematic failure detection and explanation in medical image classification
Feb 27, 2026Despite advances in machine learning-based medical image classifiers, the safety and reliability of these systems remain major concerns in practical settings. Existing auditing approaches mainly rely on unimodal features or metadata-based subgroup analyses, which are limited in interpretability and often fail to capture hidden systematic failures. To address these limitations, we introduce the first automated auditing framework that extends slice discovery methods to multimodal representations specifically for medical applications. Comprehensive experiments were conducted under common failure scenarios using the MIMIC-CXR-JPG dataset, demonstrating the framework's strong capability in both failure discovery and explanation generation. Our results also show that multimodal information generally allows more comprehensive and effective auditing of classifiers, while unimodal variants beyond image-only inputs exhibit strong potential in scenarios where resources are constrained.
Training-Driven Representational Geometry Modularization Predicts Brain Alignment in Language Models
Feb 07, 2026How large language models (LLMs) align with the neural representation and computation of human language is a central question in cognitive science. Using representational geometry as a mechanistic lens, we addressed this by tracking entropy, curvature, and fMRI encoding scores throughout Pythia (70M-1B) training. We identified a geometric modularization where layers self-organize into stable low- and high-complexity clusters. The low-complexity module, characterized by reduced entropy and curvature, consistently better predicted human language network activity. This alignment followed heterogeneous spatial-temporal trajectories: rapid and stable in temporal regions (AntTemp, PostTemp), but delayed and dynamic in frontal areas (IFG, IFGorb). Crucially, reduced curvature remained a robust predictor of model-brain alignment even after controlling for training progress, an effect that strengthened with model scale. These results links training-driven geometric reorganization to temporal-frontal functional specialization, suggesting that representational smoothing facilitates neural-like linguistic processing.
BicKD: Bilateral Contrastive Knowledge Distillation
Feb 01, 2026Knowledge distillation (KD) is a machine learning framework that transfers knowledge from a teacher model to a student model. The vanilla KD proposed by Hinton et al. has been the dominant approach in logit-based distillation and demonstrates compelling performance. However, it only performs sample-wise probability alignment between teacher and student's predictions, lacking an mechanism for class-wise comparison. Besides, vanilla KD imposes no structural constraint on the probability space. In this work, we propose a simple yet effective methodology, bilateral contrastive knowledge distillation (BicKD). This approach introduces a novel bilateral contrastive loss, which intensifies the orthogonality among different class generalization spaces while preserving consistency within the same class. The bilateral formulation enables explicit comparison of both sample-wise and class-wise prediction patterns between teacher and student. By emphasizing probabilistic orthogonality, BicKD further regularizes the geometric structure of the predictive distribution. Extensive experiments show that our BicKD method enhances knowledge transfer, and consistently outperforms state-of-the-art knowledge distillation techniques across various model architectures and benchmarks.
Scale-Free Graph-Language Models
Feb 21, 2025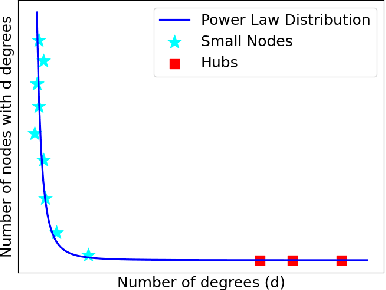
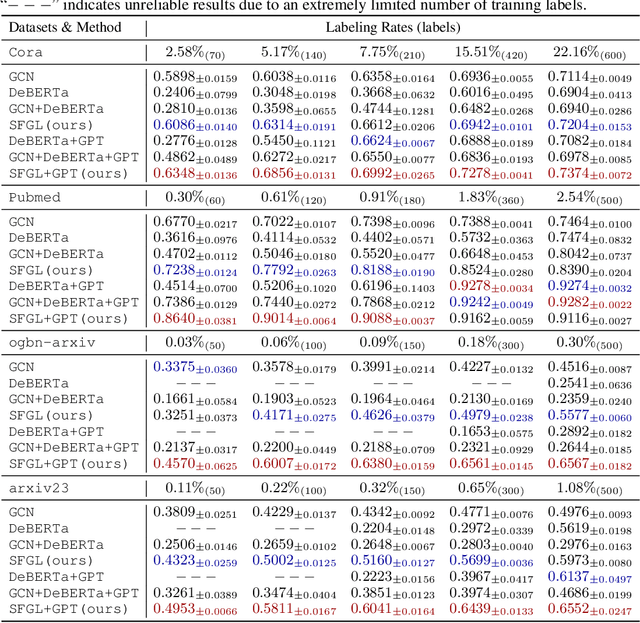
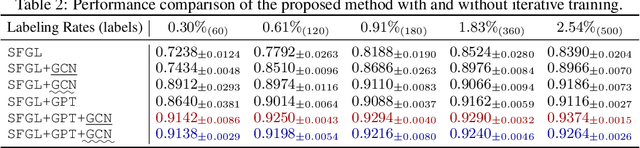
Graph-language models (GLMs) have demonstrated great potential in graph-based semi-supervised learning. A typical GLM consists of two key stages: graph generation and text embedding, which are usually implemented by inferring a latent graph and finetuning a language model (LM), respectively. However, the former often relies on artificial assumptions about the underlying edge distribution, while the latter requires extensive data annotations. To tackle these challenges, this paper introduces a novel GLM that integrates graph generation and text embedding within a unified framework. Specifically, for graph generation, we leverage an inherent characteristic of real edge distribution--the scale-free property--as a structural prior. We unexpectedly find that this natural property can be effectively approximated by a simple k-nearest neighbor (KNN) graph. For text embedding, we develop a graph-based pseudo-labeler that utilizes scale-free graphs to provide complementary supervision for improved LM finetuning. Extensive experiments on representative datasets validate our findings on the scale-free structural approximation of KNN graphs and demonstrate the effectiveness of integrating graph generation and text embedding with a real structural prior. Our code is available at https://github.com/Jianglin954/SFGL.
Edit as You See: Image-guided Video Editing via Masked Motion Modeling
Jan 08, 2025Recent advancements in diffusion models have significantly facilitated text-guided video editing. However, there is a relative scarcity of research on image-guided video editing, a method that empowers users to edit videos by merely indicating a target object in the initial frame and providing an RGB image as reference, without relying on the text prompts. In this paper, we propose a novel Image-guided Video Editing Diffusion model, termed IVEDiff for the image-guided video editing. IVEDiff is built on top of image editing models, and is equipped with learnable motion modules to maintain the temporal consistency of edited video. Inspired by self-supervised learning concepts, we introduce a masked motion modeling fine-tuning strategy that empowers the motion module's capabilities for capturing inter-frame motion dynamics, while preserving the capabilities for intra-frame semantic correlations modeling of the base image editing model. Moreover, an optical-flow-guided motion reference network is proposed to ensure the accurate propagation of information between edited video frames, alleviating the misleading effects of invalid information. We also construct a benchmark to facilitate further research. The comprehensive experiments demonstrate that our method is able to generate temporally smooth edited videos while robustly dealing with various editing objects with high quality.
ReNeg: Learning Negative Embedding with Reward Guidance
Dec 27, 2024In text-to-image (T2I) generation applications, negative embeddings have proven to be a simple yet effective approach for enhancing generation quality. Typically, these negative embeddings are derived from user-defined negative prompts, which, while being functional, are not necessarily optimal. In this paper, we introduce ReNeg, an end-to-end method designed to learn improved Negative embeddings guided by a Reward model. We employ a reward feedback learning framework and integrate classifier-free guidance (CFG) into the training process, which was previously utilized only during inference, thus enabling the effective learning of negative embeddings. We also propose two strategies for learning both global and per-sample negative embeddings. Extensive experiments show that the learned negative embedding significantly outperforms null-text and handcrafted counterparts, achieving substantial improvements in human preference alignment. Additionally, the negative embedding learned within the same text embedding space exhibits strong generalization capabilities. For example, using the same CLIP text encoder, the negative embedding learned on SD1.5 can be seamlessly transferred to text-to-image or even text-to-video models such as ControlNet, ZeroScope, and VideoCrafter2, resulting in consistent performance improvements across the board.
DARWIN 1.5: Large Language Models as Materials Science Adapted Learners
Dec 16, 2024Materials discovery and design aim to find components and structures with desirable properties over highly complex and diverse search spaces. Traditional solutions, such as high-throughput simulations and machine learning (ML), often rely on complex descriptors, which hinder generalizability and transferability across tasks. Moreover, these descriptors may deviate from experimental data due to inevitable defects and purity issues in the real world, which may reduce their effectiveness in practical applications. To address these challenges, we propose Darwin 1.5, an open-source large language model (LLM) tailored for materials science. By leveraging natural language as input, Darwin eliminates the need for task-specific descriptors and enables a flexible, unified approach to material property prediction and discovery. We employ a two-stage training strategy combining question-answering (QA) fine-tuning with multi-task learning (MTL) to inject domain-specific knowledge in various modalities and facilitate cross-task knowledge transfer. Through our strategic approach, we achieved a significant enhancement in the prediction accuracy of LLMs, with a maximum improvement of 60\% compared to LLaMA-7B base models. It further outperforms traditional machine learning models on various tasks in material science, showcasing the potential of LLMs to provide a more versatile and scalable foundation model for materials discovery and design.