 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Minimum Vertex Cover Solving via a GCN-assisted Heuristic Algorithm
Mar 09, 2025



The problem of finding a minimum vertex cover (MVC) in a graph is a well-known NP-hard problem with significant practical applications in optimization and scheduling. Its complexity, combined with the increasing scale of problems, underscores the need for efficient and effective algorithms. However, existing heuristic algorithms for MVC often rely on simplistic initialization strategies and overlook the impact of edge attributes and neighborhood information on vertex selection. In this paper, we introduce GCNIVC, a novel heuristic search algorithm designed to address the limitations of existing methods for solving MVC problems in large-scale graphs. Our approach features two main innovations. First, it utilizes a Graph Convolutional Network (GCN) to capture the global structure of graphs, which enables the generation of high-quality initial solutions that enhance the efficiency of the subsequent search process. Second, GCNIVC introduces a new heuristic that employs three containers and the concept of double-covered edges (dc-edges), improving search efficiency and providing greater flexibility for adding and removing operations based on edge attributes. Through extensive experiments on benchmark datasets, we demonstrate that GCNIVC outperforms state-of-the-art MVC algorithms in terms of both accuracy and efficiency. Our results highlight the effectiveness of GCNIVC's GCN-assisted initialization and its edge-informed search strategy. This study not only advances the understanding of MVC problem-solving but also contributes a new tool for addressing large-scale graph optimization challenges.
Taming Diffusion Prior for Image Super-Resolution with Domain Shift SDEs
Sep 26, 2024



Diffusion-based image super-resolution (SR) models have attracted substantial interest due to their powerful image restoration capabilities. However, prevailing diffusion models often struggle to strike an optimal balance between efficiency and performance. Typically, they either neglect to exploit the potential of existing extensive pretrained models, limiting their generative capacity, or they necessitate a dozens of forward passes starting from random noises, compromising inference efficiency. In this paper, we present DoSSR, a Domain Shift diffusion-based SR model that capitalizes on the generative powers of pretrained diffusion models while significantly enhancing efficiency by initiating the diffusion process with low-resolution (LR) images. At the core of our approach is a domain shift equation that integrates seamlessly with existing diffusion models. This integration not only improves the use of diffusion prior but also boosts inference efficiency. Moreover, we advance our method by transitioning the discrete shift process to a continuous formulation, termed as DoS-SDEs. This advancement leads to the fast and customized solvers that further enhance sampling efficiency. Empirical results demonstrate that our proposed method achieves state-of-the-art performance on synthetic and real-world datasets, while notably requiring only 5 sampling steps. Compared to previous diffusion prior based methods, our approach achieves a remarkable speedup of 5-7 times, demonstrating its superior efficiency. Code: https://github.com/QinpengCui/DoSSR.
Pose Magic: Efficient and Temporally Consistent Human Pose Estimation with a Hybrid Mamba-GCN Network
Aug 07, 2024
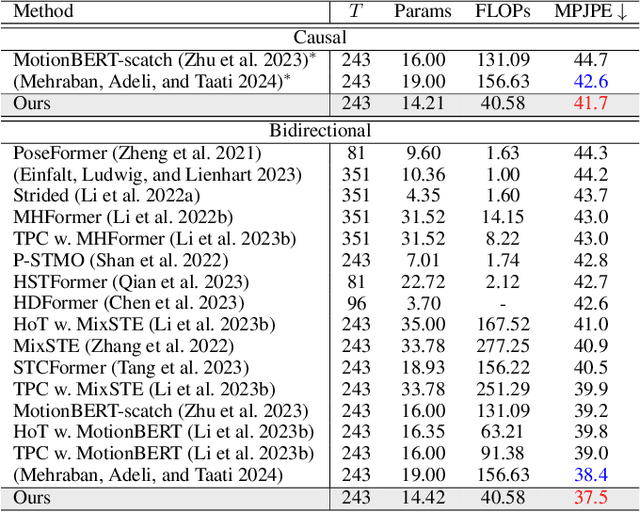


Current state-of-the-art (SOTA) methods in 3D Human Pose Estimation (HPE) are primarily based on Transformers. However, existing Transformer-based 3D HPE backbones often encounter a trade-off between accuracy and computational efficiency. To resolve the above dilemma, in this work, we leverage recent advances in state space models and utilize Mamba for high-quality and efficient long-range modeling. Nonetheless, Mamba still faces challenges in precisely exploiting local dependencies between joints. To address these issues, we propose a new attention-free hybrid spatiotemporal architecture named Hybrid Mamba-GCN (Pose Magic). This architecture introduces local enhancement with GCN by capturing relationships between neighboring joints, thus producing new representations to complement Mamba's outputs. By adaptively fusing representations from Mamba and GCN, Pose Magic demonstrates superior capability in learning the underlying 3D structure. To meet the requirements of real-time inference, we also provide a fully causal version. Extensive experiments show that Pose Magic achieves new SOTA results ($\downarrow 0.9 mm$) while saving $74.1\%$ FLOPs. In addition, Pose Magic exhibits optimal motion consistency and the ability to generalize to unseen sequence lengths.
RFormer: Transformer-based Generative Adversarial Network for Real Fundus Image Restoration on A New Clinical Benchmark
Jan 03, 2022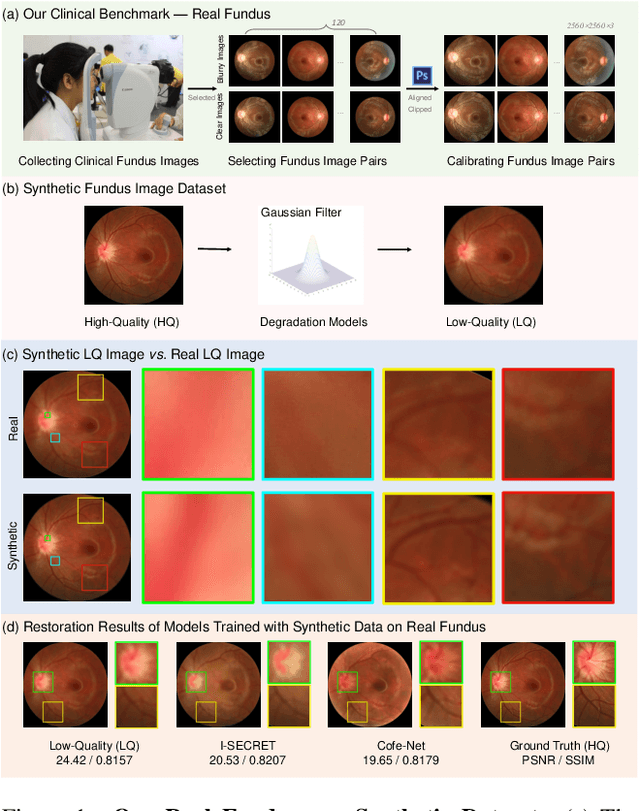

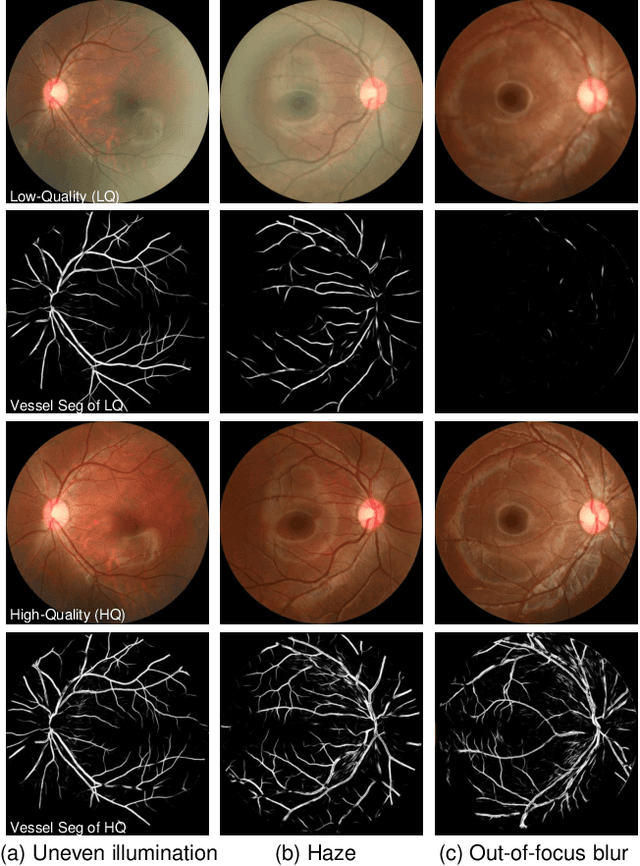

Ophthalmologists have used fundus images to screen and diagnose eye diseases. However, different equipments and ophthalmologists pose large variations to the quality of fundus images. Low-quality (LQ) degraded fundus images easily lead to uncertainty in clinical screening and generally increase the risk of misdiagnosis. Thus, real fundus image restoration is worth studying. Unfortunately, real clinical benchmark has not been explored for this task so far. In this paper, we investigate the real clinical fundus image restoration problem. Firstly, We establish a clinical dataset, Real Fundus (RF), including 120 low- and high-quality (HQ) image pairs. Then we propose a novel Transformer-based Generative Adversarial Network (RFormer) to restore the real degradation of clinical fundus images. The key component in our network is the Window-based Self-Attention Block (WSAB) which captures non-local self-similarity and long-range dependencies. To produce more visually pleasant results, a Transformer-based discriminator is introduced. Extensive experiments on our clinical benchmark show that the proposed RFormer significantly outperforms the state-of-the-art (SOTA) methods. In addition, experiments of downstream tasks such as vessel segmentation and optic disc/cup detection demonstrate that our proposed RFormer benefits clinical fundus image analysis and applications. The dataset, code, and models will be released.