 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling Human-AI Teaming: A Review and Outlook
Apr 09, 2025Artificial Intelligence (AI) is advancing at an unprecedented pace, with clear potential to enhance decision-making and productivity. Yet, the collaborative decision-making process between humans and AI remains underdeveloped, often falling short of its transformative possibilities. This paper explores the evolution of AI agents from passive tools to active collaborators in human-AI teams, emphasizing their ability to learn, adapt, and operate autonomously in complex environments. This paradigm shifts challenges traditional team dynamics, requiring new interaction protocols, delegation strategies, and responsibility distribution frameworks. Drawing on Team Situation Awareness (SA) theory, we identify two critical gaps in current human-AI teaming research: the difficulty of aligning AI agents with human values and objectives, and the underutilization of AI's capabilities as genuine team members. Addressing these gaps, we propose a structured research outlook centered on four key aspects of human-AI teaming: formulation, coordination, maintenance, and training. Our framework highlights the importance of shared mental models, trust-building, conflict resolution, and skill adaptation for effective teaming. Furthermore, we discuss the unique challenges posed by varying team compositions, goals, and complexities. This paper provides a foundational agenda for future research and practical design of sustainable, high-performing human-AI teams.
Taming Diffusion Prior for Image Super-Resolution with Domain Shift SDEs
Sep 26, 2024



Diffusion-based image super-resolution (SR) models have attracted substantial interest due to their powerful image restoration capabilities. However, prevailing diffusion models often struggle to strike an optimal balance between efficiency and performance. Typically, they either neglect to exploit the potential of existing extensive pretrained models, limiting their generative capacity, or they necessitate a dozens of forward passes starting from random noises, compromising inference efficiency. In this paper, we present DoSSR, a Domain Shift diffusion-based SR model that capitalizes on the generative powers of pretrained diffusion models while significantly enhancing efficiency by initiating the diffusion process with low-resolution (LR) images. At the core of our approach is a domain shift equation that integrates seamlessly with existing diffusion models. This integration not only improves the use of diffusion prior but also boosts inference efficiency. Moreover, we advance our method by transitioning the discrete shift process to a continuous formulation, termed as DoS-SDEs. This advancement leads to the fast and customized solvers that further enhance sampling efficiency. Empirical results demonstrate that our proposed method achieves state-of-the-art performance on synthetic and real-world datasets, while notably requiring only 5 sampling steps. Compared to previous diffusion prior based methods, our approach achieves a remarkable speedup of 5-7 times, demonstrating its superior efficiency. Code: https://github.com/QinpengCui/DoSSR.
Inclusive FinTech Lending via Contrastive Learning and Domain Adaptation
May 10, 2023


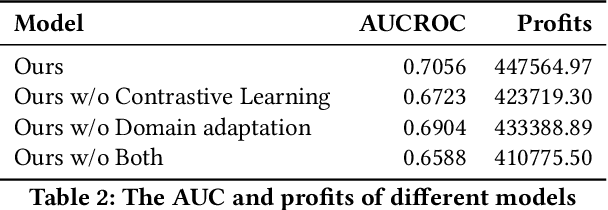
FinTech lending (e.g., micro-lending) has played a significant role in facilitating financial inclusion. It has reduced processing times and costs, enhanced the user experience, and made it possible for people to obtain loans who may not have qualified for credit from traditional lenders. However, there are concerns about the potentially biased algorithmic decision-making during loan screening. Machine learning algorithms used to evaluate credit quality can be influenced by representation bias in the training data, as we only have access to the default outcome labels of approved loan applications, for which the borrowers' socioeconomic characteristics are better than those of rejected ones. In this case, the model trained on the labeled data performs well on the historically approved population, but does not generalize well to borrowers of low socioeconomic background. In this paper, we investigate the problem of representation bias in loan screening for a real-world FinTech lending platform. We propose a new Transformer-based sequential loan screening model with self-supervised contrastive learning and domain adaptation to tackle this challenging issue. We use contrastive learning to train our feature extractor on unapproved (unlabeled) loan applications and use domain adaptation to generalize the performance of our label predictor. We demonstrate the effectiveness of our model through extensive experimentation in the real-world micro-lending setting. Our results show that our model significantly promotes the inclusiveness of funding decisions, while also improving loan screening accuracy and profit by 7.10% and 8.95%, respectively. We also show that incorporating the test data into contrastive learning and domain adaptation and labeling a small ratio of test data can further boost model performance.
RuDi: Explaining Behavior Sequence Models by Automatic Statistics Generation and Rule Distillation
Aug 16, 2022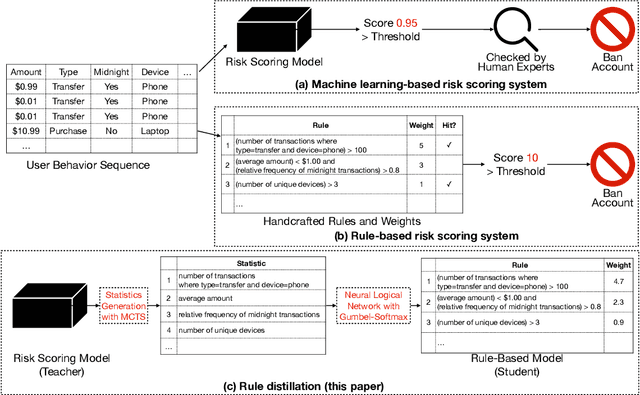
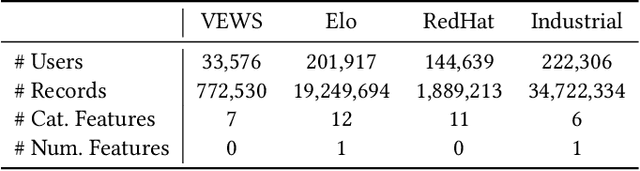
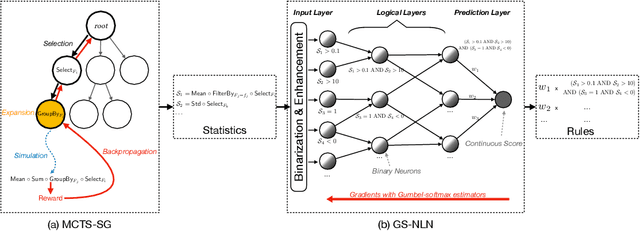
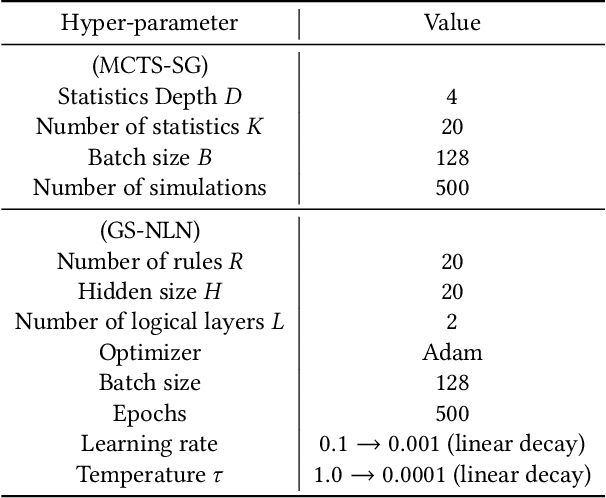
Risk scoring systems have been widely deployed in many applications, which assign risk scores to users according to their behavior sequences. Though many deep learning methods with sophisticated designs have achieved promising results, the black-box nature hinders their applications due to fairness, explainability, and compliance consideration. Rule-based systems are considered reliable in these sensitive scenarios. However, building a rule system is labor-intensive. Experts need to find informative statistics from user behavior sequences, design rules based on statistics and assign weights to each rule. In this paper, we bridge the gap between effective but black-box models and transparent rule models. We propose a two-stage method, RuDi, that distills the knowledge of black-box teacher models into rule-based student models. We design a Monte Carlo tree search-based statistics generation method that can provide a set of informative statistics in the first stage. Then statistics are composed into logical rules with our proposed neural logical networks by mimicking the outputs of teacher models. We evaluate RuDi on three real-world public datasets and an industrial dataset to demonstrate its effectiveness.
Uncovering the Source of Machine Bias
Jan 09, 2022


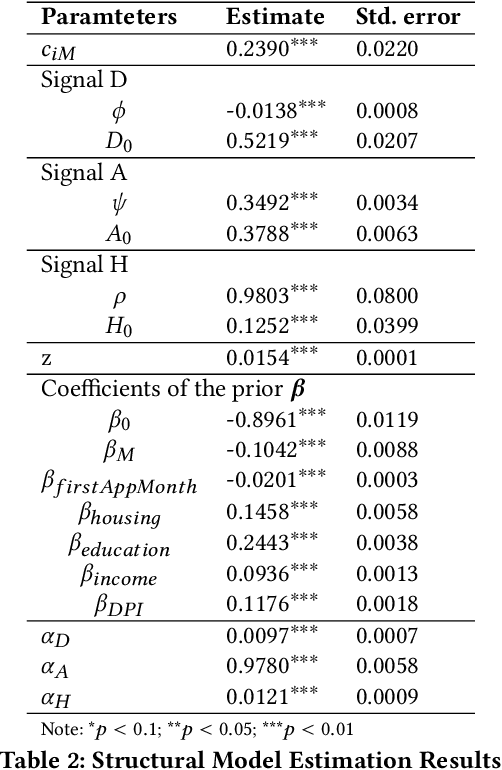
We develop a structural econometric model to capture the decision dynamics of human evaluators on an online micro-lending platform, and estimate the model parameters using a real-world dataset. We find two types of biases in gender, preference-based bias and belief-based bias, are present in human evaluators' decisions. Both types of biases are in favor of female applicants. Through counterfactual simulations, we quantify the effect of gender bias on loan granting outcomes and the welfare of the company and the borrowers. Our results imply that both the existence of the preference-based bias and that of the belief-based bias reduce the company's profits. When the preference-based bias is removed, the company earns more profits. When the belief-based bias is removed, the company's profits also increase. Both increases result from raising the approval probability for borrowers, especially male borrowers, who eventually pay back loans. For borrowers, the elimination of either bias decreases the gender gap of the true positive rates in the credit risk evaluation. We also train machine learning algorithms on both the real-world data and the data from the counterfactual simulations. We compare the decisions made by those algorithms to see how evaluators' biases are inherited by the algorithms and reflected in machine-based decisions. We find that machine learning algorithms can mitigate both the preference-based bias and the belief-based bias.
TransBoost: A Boosting-Tree Kernel Transfer Learning Algorithm for Improving Financial Inclusion
Dec 16, 2021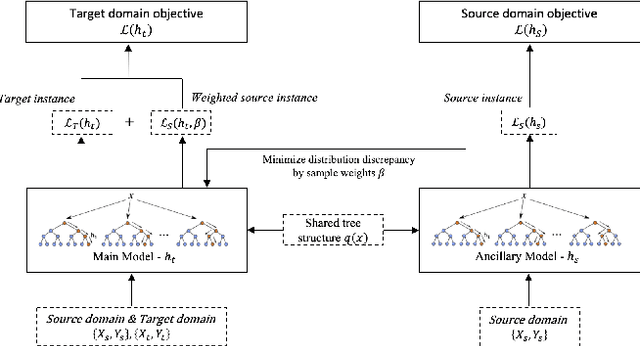
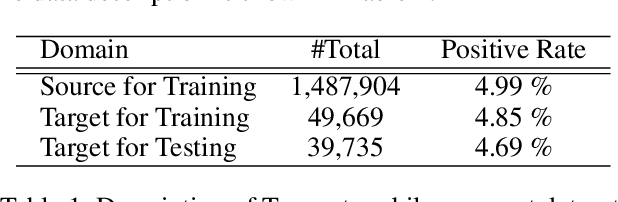
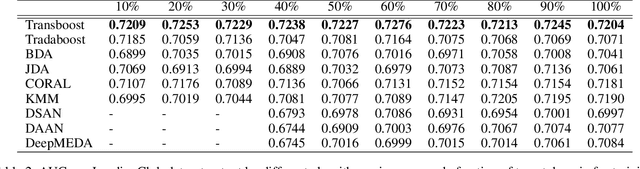
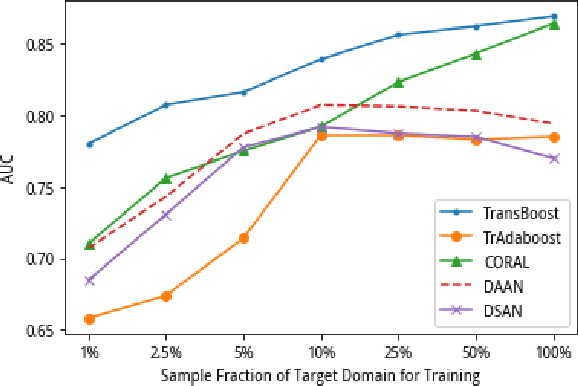
The prosperity of mobile and financial technologies has bred and expanded various kinds of financial products to a broader scope of people, which contributes to advocating financial inclusion. It has non-trivial social benefits of diminishing financial inequality. However, the technical challenges in individual financial risk evaluation caused by the distinct characteristic distribution and limited credit history of new users, as well as the inexperience of newly-entered companies in handling complex data and obtaining accurate labels, impede further promoting financial inclusion. To tackle these challenges, this paper develops a novel transfer learning algorithm (i.e., TransBoost) that combines the merits of tree-based models and kernel methods. The TransBoost is designed with a parallel tree structure and efficient weights updating mechanism with theoretical guarantee, which enables it to excel in tackling real-world data with high dimensional features and sparsity in $O(n)$ time complexity. We conduct extensive experiments on two public datasets and a unique large-scale dataset from Tencent Mobile Payment. The results show that the TransBoost outperforms other state-of-the-art benchmark transfer learning algorithms in terms of prediction accuracy with superior efficiency, shows stronger robustness to data sparsity, and provides meaningful model interpretation. Besides, given a financial risk level, the TransBoost enables financial service providers to serve the largest number of users including those who would otherwise be excluded by other algorithms. That is, the TransBoost improves financial inclusion.