 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeCond: Fast Shapelet-Guided Dataset Condensation for Time Series Classification
Feb 09, 2026Time series data supports many domains (e.g., finance and climate science), but its rapid growth strains storage and computation. Dataset condensation can alleviate this by synthesizing a compact training set that preserves key information. Yet most condensation methods are image-centric and often fail on time series because they miss time-series-specific temporal structure, especially local discriminative motifs such as shapelets. In this work, we propose ShapeCond, a novel and efficient condensation framework for time series classification that leverages shapelet-based dataset knowledge via a shapelet-guided optimization strategy. Our shapelet-assisted synthesis cost is independent of sequence length: longer series yield larger speedups in synthesis (e.g., 29$\times$ faster over prior state-of-the-art method CondTSC for time-series condensation, and up to 10,000$\times$ over naively using shapelets on the Sleep dataset with 3,000 timesteps). By explicitly preserving critical local patterns, ShapeCond improves downstream accuracy and consistently outperforms all prior state-of-the-art time series dataset condensation methods across extensive experiments. Code is available at https://github.com/lunaaa95/ShapeCond.
Mamba or Transformer for Time Series Forecasting? Mixture of Universals (MoU) Is All You Need
Aug 28, 2024



Time series forecasting requires balancing short-term and long-term dependencies for accurate predictions. Existing methods mainly focus on long-term dependency modeling, neglecting the complexities of short-term dynamics, which may hinder performance. Transformers are superior in modeling long-term dependencies but are criticized for their quadratic computational cost. Mamba provides a near-linear alternative but is reported less effective in time series longterm forecasting due to potential information loss. Current architectures fall short in offering both high efficiency and strong performance for long-term dependency modeling. To address these challenges, we introduce Mixture of Universals (MoU), a versatile model to capture both short-term and long-term dependencies for enhancing performance in time series forecasting. MoU is composed of two novel designs: Mixture of Feature Extractors (MoF), an adaptive method designed to improve time series patch representations for short-term dependency, and Mixture of Architectures (MoA), which hierarchically integrates Mamba, FeedForward, Convolution, and Self-Attention architectures in a specialized order to model long-term dependency from a hybrid perspective. The proposed approach achieves state-of-the-art performance while maintaining relatively low computational costs. Extensive experiments on seven real-world datasets demonstrate the superiority of MoU. Code is available at https://github.com/lunaaa95/mou/.
RDGSL: Dynamic Graph Representation Learning with Structure Learning
Sep 05, 2023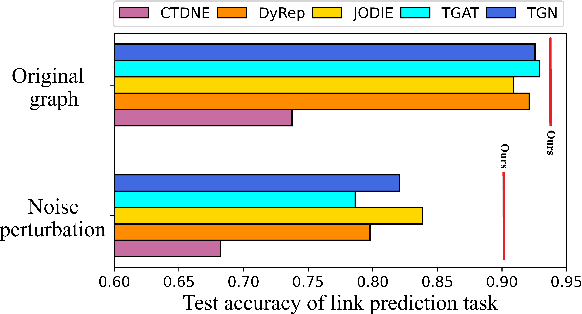

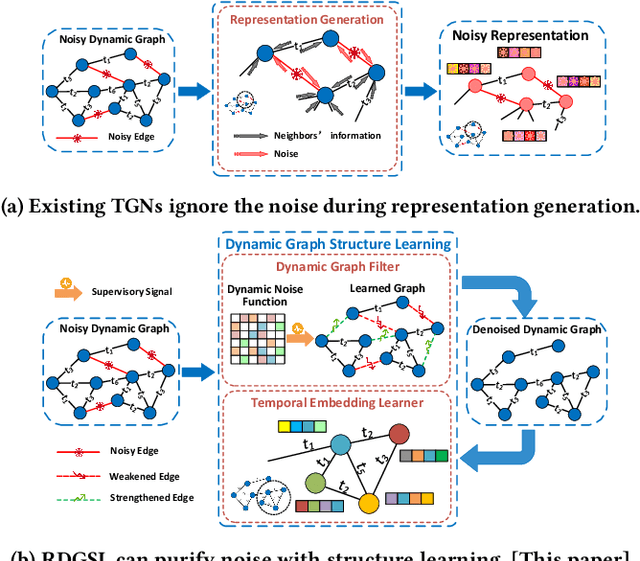
Temporal Graph Networks (TGNs) have shown remarkable performance in learning representation for continuous-time dynamic graphs. However, real-world dynamic graphs typically contain diverse and intricate noise. Noise can significantly degrade the quality of representation generation, impeding the effectiveness of TGNs in downstream tasks. Though structure learning is widely applied to mitigate noise in static graphs, its adaptation to dynamic graph settings poses two significant challenges. i) Noise dynamics. Existing structure learning methods are ill-equipped to address the temporal aspect of noise, hampering their effectiveness in such dynamic and ever-changing noise patterns. ii) More severe noise. Noise may be introduced along with multiple interactions between two nodes, leading to the re-pollution of these nodes and consequently causing more severe noise compared to static graphs. In this paper, we present RDGSL, a representation learning method in continuous-time dynamic graphs. Meanwhile, we propose dynamic graph structure learning, a novel supervisory signal that empowers RDGSL with the ability to effectively combat noise in dynamic graphs. To address the noise dynamics issue, we introduce the Dynamic Graph Filter, where we innovatively propose a dynamic noise function that dynamically captures both current and historical noise, enabling us to assess the temporal aspect of noise and generate a denoised graph. We further propose the Temporal Embedding Learner to tackle the challenge of more severe noise, which utilizes an attention mechanism to selectively turn a blind eye to noisy edges and hence focus on normal edges, enhancing the expressiveness for representation generation that remains resilient to noise. Our method demonstrates robustness towards downstream tasks, resulting in up to 5.1% absolute AUC improvement in evolving classification versus the second-best baseline.
TIGER: Temporal Interaction Graph Embedding with Restarts
Feb 16, 2023



Temporal interaction graphs (TIGs), consisting of sequences of timestamped interaction events, are prevalent in fields like e-commerce and social networks. To better learn dynamic node embeddings that vary over time, researchers have proposed a series of temporal graph neural networks for TIGs. However, due to the entangled temporal and structural dependencies, existing methods have to process the sequence of events chronologically and consecutively to ensure node representations are up-to-date. This prevents existing models from parallelization and reduces their flexibility in industrial applications. To tackle the above challenge, in this paper, we propose TIGER, a TIG embedding model that can restart at any timestamp. We introduce a restarter module that generates surrogate representations acting as the warm initialization of node representations. By restarting from multiple timestamps simultaneously, we divide the sequence into multiple chunks and naturally enable the parallelization of the model. Moreover, in contrast to previous models that utilize a single memory unit, we introduce a dual memory module to better exploit neighborhood information and alleviate the staleness problem. Extensive experiments on four public datasets and one industrial dataset are conducted, and the results verify both the effectiveness and the efficiency of our work.
ConsRec: Learning Consensus Behind Interactions for Group Recommendation
Feb 07, 2023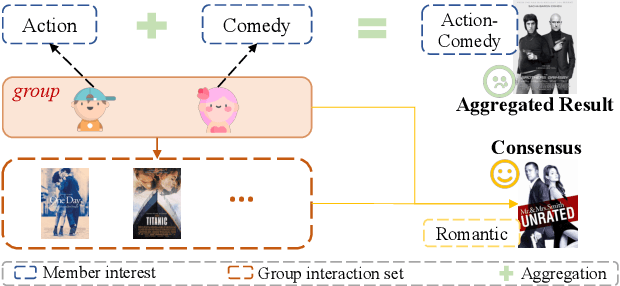
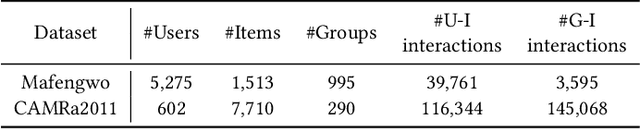
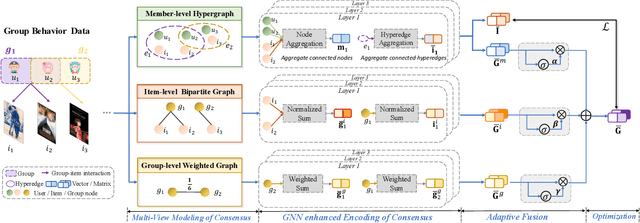

Since group activities have become very common in daily life, there is an urgent demand for generating recommendations for a group of users, referred to as group recommendation task. Existing group recommendation methods usually infer groups' preferences via aggregating diverse members' interests. Actually, groups' ultimate choice involves compromises between members, and finally, an agreement can be reached. However, existing individual information aggregation lacks a holistic group-level consideration, failing to capture the consensus information. Besides, their specific aggregation strategies either suffer from high computational costs or become too coarse-grained to make precise predictions. To solve the aforementioned limitations, in this paper, we focus on exploring consensus behind group behavior data. To comprehensively capture the group consensus, we innovatively design three distinct views which provide mutually complementary information to enable multi-view learning, including member-level aggregation, item-level tastes, and group-level inherent preferences. To integrate and balance the multi-view information, an adaptive fusion component is further proposed. As to member-level aggregation, different from existing linear or attentive strategies, we design a novel hypergraph neural network that allows for efficient hypergraph convolutional operations to generate expressive member-level aggregation. We evaluate our ConsRec on two real-world datasets and experimental results show that our model outperforms state-of-the-art methods. An extensive case study also verifies the effectiveness of consensus modeling.
RuDi: Explaining Behavior Sequence Models by Automatic Statistics Generation and Rule Distillation
Aug 16, 2022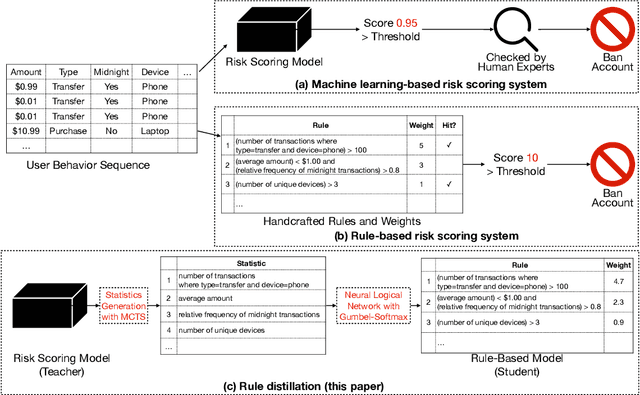
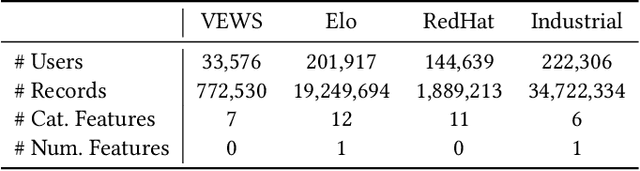
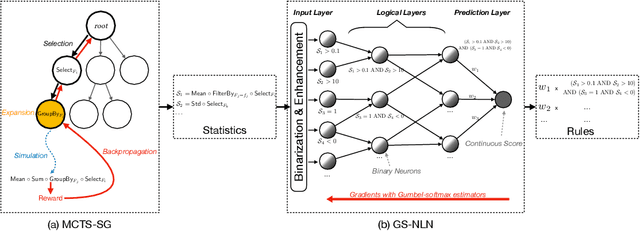
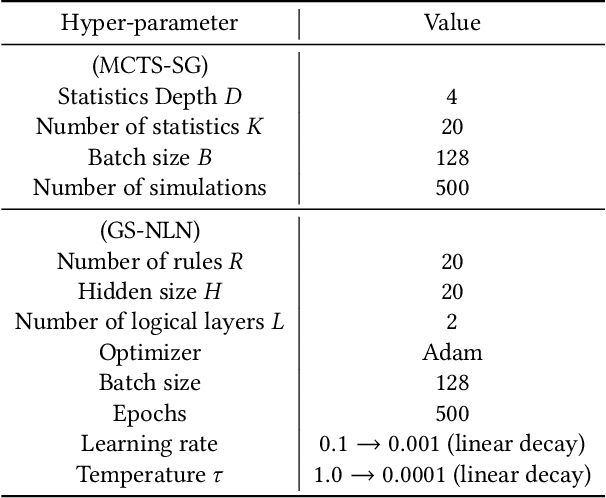
Risk scoring systems have been widely deployed in many applications, which assign risk scores to users according to their behavior sequences. Though many deep learning methods with sophisticated designs have achieved promising results, the black-box nature hinders their applications due to fairness, explainability, and compliance consideration. Rule-based systems are considered reliable in these sensitive scenarios. However, building a rule system is labor-intensive. Experts need to find informative statistics from user behavior sequences, design rules based on statistics and assign weights to each rule. In this paper, we bridge the gap between effective but black-box models and transparent rule models. We propose a two-stage method, RuDi, that distills the knowledge of black-box teacher models into rule-based student models. We design a Monte Carlo tree search-based statistics generation method that can provide a set of informative statistics in the first stage. Then statistics are composed into logical rules with our proposed neural logical networks by mimicking the outputs of teacher models. We evaluate RuDi on three real-world public datasets and an industrial dataset to demonstrate its effectiveness.
Triangle Graph Interest Network for Click-through Rate Prediction
Feb 06, 2022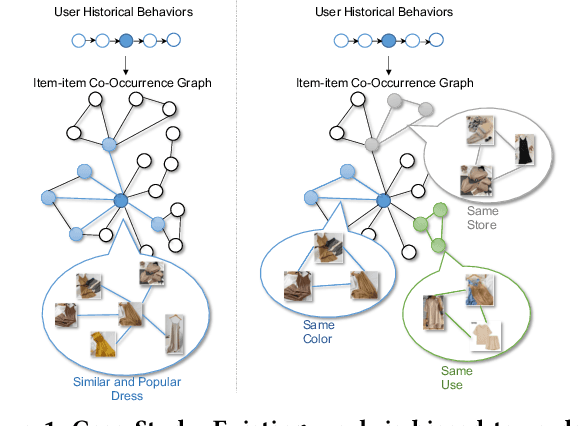

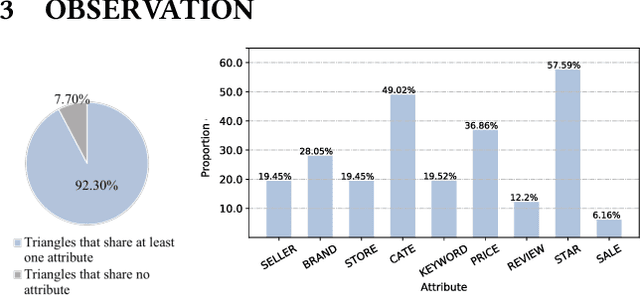
Click-through rate prediction is a critical task in online advertising. Currently, many existing methods attempt to extract user potential interests from historical click behavior sequences. However, it is difficult to handle sparse user behaviors or broaden interest exploration. Recently, some researchers incorporate the item-item co-occurrence graph as an auxiliary. Due to the elusiveness of user interests, those works still fail to determine the real motivation of user click behaviors. Besides, those works are more biased towards popular or similar commodities. They lack an effective mechanism to break the diversity restrictions. In this paper, we point out two special properties of triangles in the item-item graphs for recommendation systems: Intra-triangle homophily and Inter-triangle heterophiy. Based on this, we propose a novel and effective framework named Triangle Graph Interest Network (TGIN). For each clicked item in user behavior sequences, we introduce the triangles in its neighborhood of the item-item graphs as a supplement. TGIN regards these triangles as the basic units of user interests, which provide the clues to capture the real motivation for a user clicking an item. We characterize every click behavior by aggregating the information of several interest units to alleviate the elusive motivation problem. The attention mechanism determines users' preference for different interest units. By selecting diverse and relative triangles, TGIN brings in novel and serendipitous items to expand exploration opportunities of user interests. Then, we aggregate the multi-level interests of historical behavior sequences to improve CTR prediction. Extensive experiments on both public and industrial datasets clearly verify the effectiveness of our framework.
Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning
Oct 08, 2020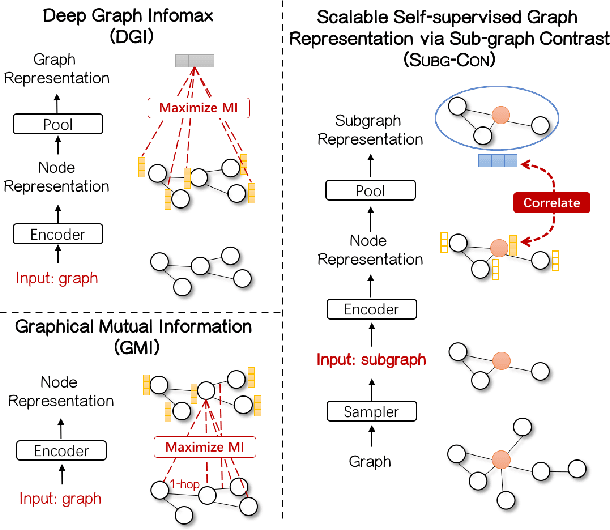
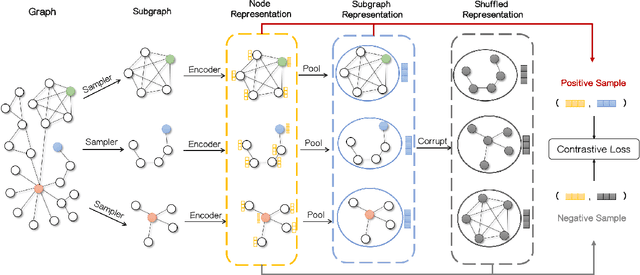
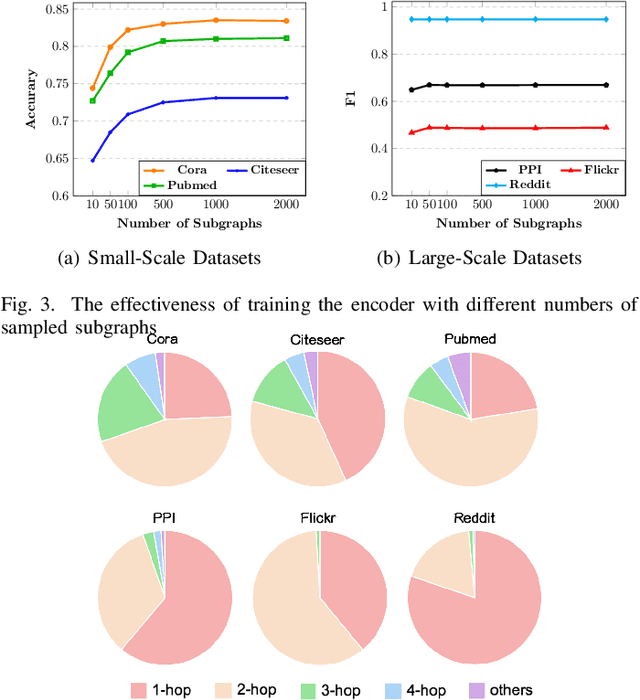
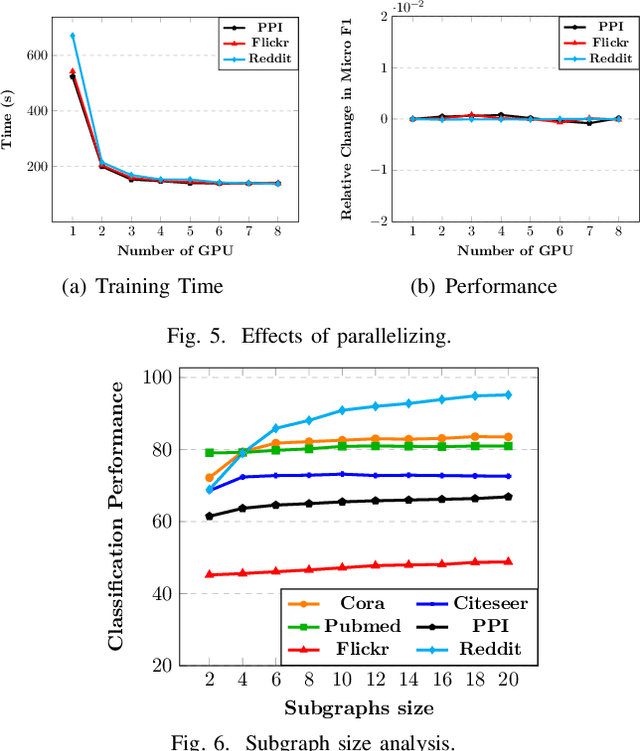
Graph representation learning has attracted lots of attention recently. Existing graph neural networks fed with the complete graph data are not scalable due to limited computation and memory costs. Thus, it remains a great challenge to capture rich information in large-scale graph data. Besides, these methods mainly focus on supervised learning and highly depend on node label information, which is expensive to obtain in the real world. As to unsupervised network embedding approaches, they overemphasize node proximity instead, whose learned representations can hardly be used in downstream application tasks directly. In recent years, emerging self-supervised learning provides a potential solution to address the aforementioned problems. However, existing self-supervised works also operate on the complete graph data and are biased to fit either global or very local (1-hop neighborhood) graph structures in defining the mutual information based loss terms. In this paper, a novel self-supervised representation learning method via Subgraph Contrast, namely \textsc{Subg-Con}, is proposed by utilizing the strong correlation between central nodes and their sampled subgraphs to capture regional structure information. Instead of learning on the complete input graph data, with a novel data augmentation strategy, \textsc{Subg-Con} learns node representations through a contrastive loss defined based on subgraphs sampled from the original graph instead. Compared with existing graph representation learning approaches, \textsc{Subg-Con} has prominent performance advantages in weaker supervision requirements, model learning scalability, and parallelization. Extensive experiments verify both the effectiveness and the efficiency of our work compared with both classic and state-of-the-art graph representation learning approaches on multiple real-world large-scale benchmark datasets from different domains.