 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Modeling for Human Motion Recovery Under Occlusions
Jan 23, 2026Human motion reconstruction from monocular videos is a fundamental challenge in computer vision, with broad applications in AR/VR, robotics, and digital content creation, but remains challenging under frequent occlusions in real-world settings. Existing regression-based methods are efficient but fragile to missing observations, while optimization- and diffusion-based approaches improve robustness at the cost of slow inference speed and heavy preprocessing steps. To address these limitations, we leverage recent advances in generative masked modeling and present MoRo: Masked Modeling for human motion Recovery under Occlusions. MoRo is an occlusion-robust, end-to-end generative framework that formulates motion reconstruction as a video-conditioned task, and efficiently recover human motion in a consistent global coordinate system from RGB videos. By masked modeling, MoRo naturally handles occlusions while enabling efficient, end-to-end inference. To overcome the scarcity of paired video-motion data, we design a cross-modality learning scheme that learns multi-modal priors from a set of heterogeneous datasets: (i) a trajectory-aware motion prior trained on MoCap datasets, (ii) an image-conditioned pose prior trained on image-pose datasets, capturing diverse per-frame poses, and (iii) a video-conditioned masked transformer that fuses motion and pose priors, finetuned on video-motion datasets to integrate visual cues with motion dynamics for robust inference. Extensive experiments on EgoBody and RICH demonstrate that MoRo substantially outperforms state-of-the-art methods in accuracy and motion realism under occlusions, while performing on-par in non-occluded scenarios. MoRo achieves real-time inference at 70 FPS on a single H200 GPU.
Rethinking Time Encoding via Learnable Transformation Functions
May 01, 2025Effectively modeling time information and incorporating it into applications or models involving chronologically occurring events is crucial. Real-world scenarios often involve diverse and complex time patterns, which pose significant challenges for time encoding methods. While previous methods focus on capturing time patterns, many rely on specific inductive biases, such as using trigonometric functions to model periodicity. This narrow focus on single-pattern modeling makes them less effective in handling the diversity and complexities of real-world time patterns. In this paper, we investigate to improve the existing commonly used time encoding methods and introduce Learnable Transformation-based Generalized Time Encoding (LeTE). We propose using deep function learning techniques to parameterize non-linear transformations in time encoding, making them learnable and capable of modeling generalized time patterns, including diverse and complex temporal dynamics. By enabling learnable transformations, LeTE encompasses previous methods as specific cases and allows seamless integration into a wide range of tasks. Through extensive experiments across diverse domains, we demonstrate the versatility and effectiveness of LeTE.
Unifying Text Semantics and Graph Structures for Temporal Text-attributed Graphs with Large Language Models
Mar 18, 2025Temporal graph neural networks (TGNNs) have shown remarkable performance in temporal graph modeling. However, real-world temporal graphs often possess rich textual information, giving rise to temporal text-attributed graphs (TTAGs). Such combination of dynamic text semantics and evolving graph structures introduces heightened complexity. Existing TGNNs embed texts statically and rely heavily on encoding mechanisms that biasedly prioritize structural information, overlooking the temporal evolution of text semantics and the essential interplay between semantics and structures for synergistic reinforcement. To tackle these issues, we present \textbf{{Cross}}, a novel framework that seamlessly extends existing TGNNs for TTAG modeling. The key idea is to employ the advanced large language models (LLMs) to extract the dynamic semantics in text space and then generate expressive representations unifying both semantics and structures. Specifically, we propose a Temporal Semantics Extractor in the {Cross} framework, which empowers the LLM to offer the temporal semantic understanding of node's evolving contexts of textual neighborhoods, facilitating semantic dynamics. Subsequently, we introduce the Semantic-structural Co-encoder, which collaborates with the above Extractor for synthesizing illuminating representations by jointly considering both semantic and structural information while encouraging their mutual reinforcement. Extensive experimental results on four public datasets and one practical industrial dataset demonstrate {Cross}'s significant effectiveness and robustness.
LLM-GAN: Construct Generative Adversarial Network Through Large Language Models For Explainable Fake News Detection
Sep 03, 2024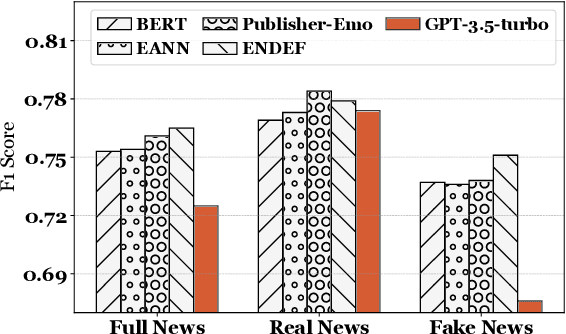
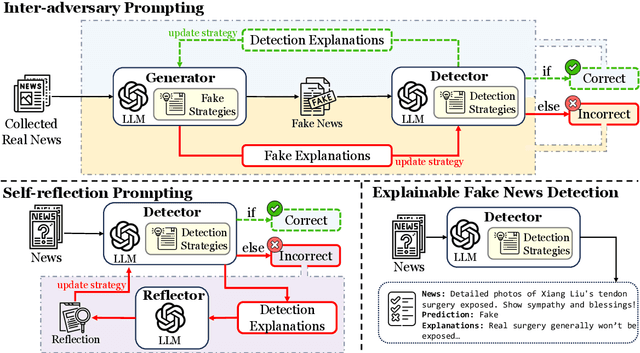
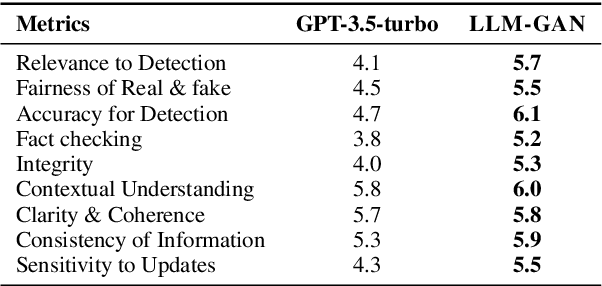
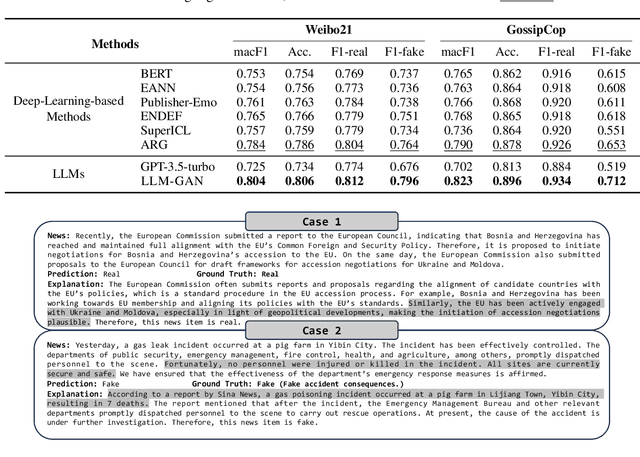
Explainable fake news detection predicts the authenticity of news items with annotated explanations. Today, Large Language Models (LLMs) are known for their powerful natural language understanding and explanation generation abilities. However, presenting LLMs for explainable fake news detection remains two main challenges. Firstly, fake news appears reasonable and could easily mislead LLMs, leaving them unable to understand the complex news-faking process. Secondly, utilizing LLMs for this task would generate both correct and incorrect explanations, which necessitates abundant labor in the loop. In this paper, we propose LLM-GAN, a novel framework that utilizes prompting mechanisms to enable an LLM to become Generator and Detector and for realistic fake news generation and detection. Our results demonstrate LLM-GAN's effectiveness in both prediction performance and explanation quality. We further showcase the integration of LLM-GAN to a cloud-native AI platform to provide better fake news detection service in the cloud.
DTFormer: A Transformer-Based Method for Discrete-Time Dynamic Graph Representation Learning
Jul 26, 2024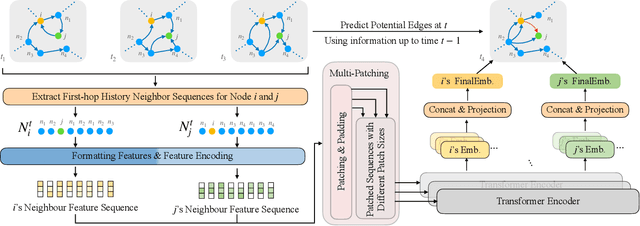
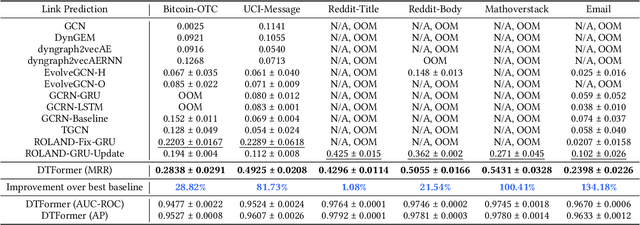
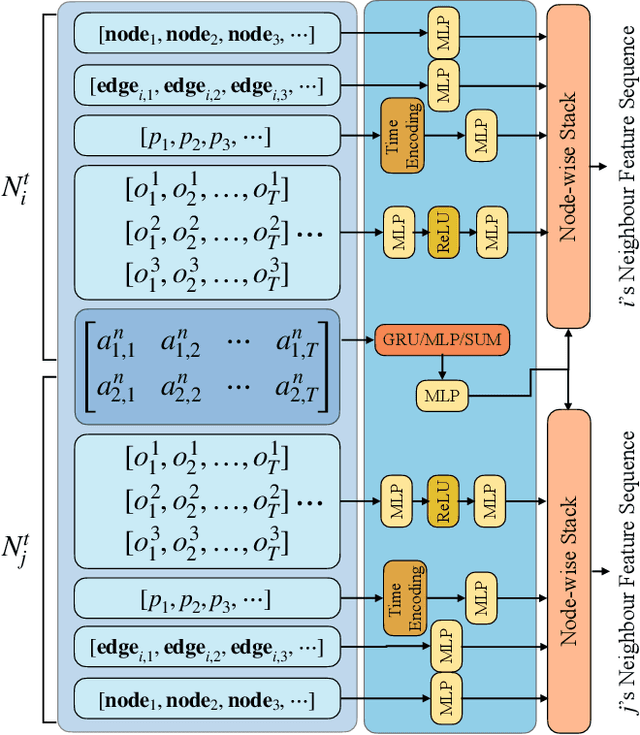
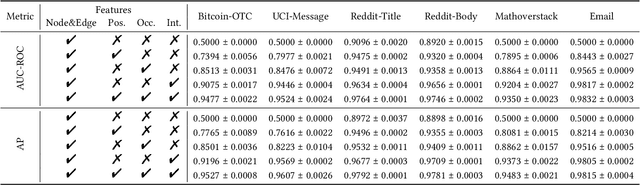
Discrete-Time Dynamic Graphs (DTDGs), which are prevalent in real-world implementations and notable for their ease of data acquisition, have garnered considerable attention from both academic researchers and industry practitioners. The representation learning of DTDGs has been extensively applied to model the dynamics of temporally changing entities and their evolving connections. Currently, DTDG representation learning predominantly relies on GNN+RNN architectures, which manifest the inherent limitations of both Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs). GNNs suffer from the over-smoothing issue as the models architecture goes deeper, while RNNs struggle to capture long-term dependencies effectively. GNN+RNN architectures also grapple with scaling to large graph sizes and long sequences. Additionally, these methods often compute node representations separately and focus solely on individual node characteristics, thereby overlooking the behavior intersections between the two nodes whose link is being predicted, such as instances where the two nodes appear together in the same context or share common neighbors. This paper introduces a novel representation learning method DTFormer for DTDGs, pivoting from the traditional GNN+RNN framework to a Transformer-based architecture. Our approach exploits the attention mechanism to concurrently process topological information within the graph at each timestamp and temporal dynamics of graphs along the timestamps, circumventing the aforementioned fundamental weakness of both GNNs and RNNs. Moreover, we enhance the model's expressive capability by incorporating the intersection relationships among nodes and integrating a multi-patching module. Extensive experiments conducted on six public dynamic graph benchmark datasets confirm our model's efficacy, achieving the SOTA performance.
Towards Adaptive Neighborhood for Advancing Temporal Interaction Graph Modeling
Jun 14, 2024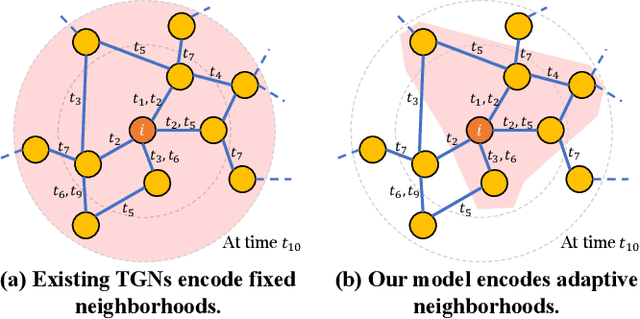
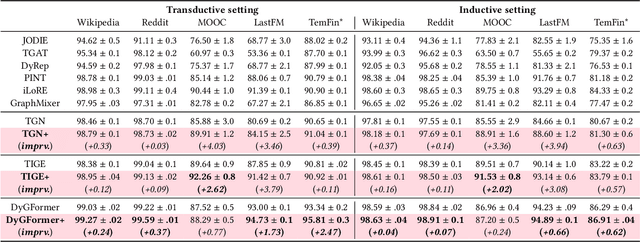
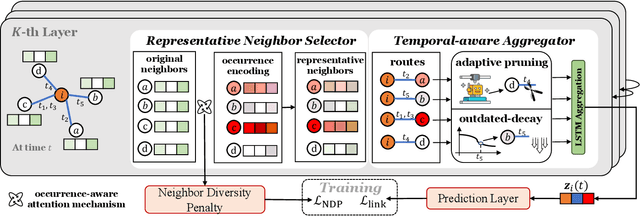

Temporal Graph Networks (TGNs) have demonstrated their remarkable performance in modeling temporal interaction graphs. These works can generate temporal node representations by encoding the surrounding neighborhoods for the target node. However, an inherent limitation of existing TGNs is their reliance on fixed, hand-crafted rules for neighborhood encoding, overlooking the necessity for an adaptive and learnable neighborhood that can accommodate both personalization and temporal evolution across different timestamps. In this paper, we aim to enhance existing TGNs by introducing an adaptive neighborhood encoding mechanism. We present SEAN, a flexible plug-and-play model that can be seamlessly integrated with existing TGNs, effectively boosting their performance. To achieve this, we decompose the adaptive neighborhood encoding process into two phases: (i) representative neighbor selection, and (ii) temporal-aware neighborhood information aggregation. Specifically, we propose the Representative Neighbor Selector component, which automatically pinpoints the most important neighbors for the target node. It offers a tailored understanding of each node's unique surrounding context, facilitating personalization. Subsequently, we propose a Temporal-aware Aggregator, which synthesizes neighborhood aggregation by selectively determining the utilization of aggregation routes and decaying the outdated information, allowing our model to adaptively leverage both the contextually significant and current information during aggregation. We conduct extensive experiments by integrating SEAN into three representative TGNs, evaluating their performance on four public datasets and one financial benchmark dataset introduced in this paper. The results demonstrate that SEAN consistently leads to performance improvements across all models, achieving SOTA performance and exceptional robustness.
Prompt Learning on Temporal Interaction Graphs
Feb 09, 2024Temporal Interaction Graphs (TIGs) are widely utilized to represent real-world systems. To facilitate representation learning on TIGs, researchers have proposed a series of TIG models. However, these models are still facing two tough gaps between the pre-training and downstream predictions in their ``pre-train, predict'' training paradigm. First, the temporal discrepancy between the pre-training and inference data severely undermines the models' applicability in distant future predictions on the dynamically evolving data. Second, the semantic divergence between pretext and downstream tasks hinders their practical applications, as they struggle to align with their learning and prediction capabilities across application scenarios. Recently, the ``pre-train, prompt'' paradigm has emerged as a lightweight mechanism for model generalization. Applying this paradigm is a potential solution to solve the aforementioned challenges. However, the adaptation of this paradigm to TIGs is not straightforward. The application of prompting in static graph contexts falls short in temporal settings due to a lack of consideration for time-sensitive dynamics and a deficiency in expressive power. To address this issue, we introduce Temporal Interaction Graph Prompting (TIGPrompt), a versatile framework that seamlessly integrates with TIG models, bridging both the temporal and semantic gaps. In detail, we propose a temporal prompt generator to offer temporally-aware prompts for different tasks. These prompts stand out for their minimalistic design, relying solely on the tuning of the prompt generator with very little supervision data. To cater to varying computational resource demands, we propose an extended ``pre-train, prompt-based fine-tune'' paradigm, offering greater flexibility. Through extensive experiments, the TIGPrompt demonstrates the SOTA performance and remarkable efficiency advantages.
RoHM: Robust Human Motion Reconstruction via Diffusion
Jan 16, 2024



We propose RoHM, an approach for robust 3D human motion reconstruction from monocular RGB(-D) videos in the presence of noise and occlusions. Most previous approaches either train neural networks to directly regress motion in 3D or learn data-driven motion priors and combine them with optimization at test time. The former do not recover globally coherent motion and fail under occlusions; the latter are time-consuming, prone to local minima, and require manual tuning. To overcome these shortcomings, we exploit the iterative, denoising nature of diffusion models. RoHM is a novel diffusion-based motion model that, conditioned on noisy and occluded input data, reconstructs complete, plausible motions in consistent global coordinates. Given the complexity of the problem -- requiring one to address different tasks (denoising and infilling) in different solution spaces (local and global motion) -- we decompose it into two sub-tasks and learn two models, one for global trajectory and one for local motion. To capture the correlations between the two, we then introduce a novel conditioning module, combining it with an iterative inference scheme. We apply RoHM to a variety of tasks -- from motion reconstruction and denoising to spatial and temporal infilling. Extensive experiments on three popular datasets show that our method outperforms state-of-the-art approaches qualitatively and quantitatively, while being faster at test time. The code will be available at https://sanweiliti.github.io/ROHM/ROHM.html.
EgoGen: An Egocentric Synthetic Data Generator
Jan 16, 2024Understanding the world in first-person view is fundamental in Augmented Reality (AR). This immersive perspective brings dramatic visual changes and unique challenges compared to third-person views. Synthetic data has empowered third-person-view vision models, but its application to embodied egocentric perception tasks remains largely unexplored. A critical challenge lies in simulating natural human movements and behaviors that effectively steer the embodied cameras to capture a faithful egocentric representation of the 3D world. To address this challenge, we introduce EgoGen, a new synthetic data generator that can produce accurate and rich ground-truth training data for egocentric perception tasks. At the heart of EgoGen is a novel human motion synthesis model that directly leverages egocentric visual inputs of a virtual human to sense the 3D environment. Combined with collision-avoiding motion primitives and a two-stage reinforcement learning approach, our motion synthesis model offers a closed-loop solution where the embodied perception and movement of the virtual human are seamlessly coupled. Compared to previous works, our model eliminates the need for a pre-defined global path, and is directly applicable to dynamic environments. Combined with our easy-to-use and scalable data generation pipeline, we demonstrate EgoGen's efficacy in three tasks: mapping and localization for head-mounted cameras, egocentric camera tracking, and human mesh recovery from egocentric views. EgoGen will be fully open-sourced, offering a practical solution for creating realistic egocentric training data and aiming to serve as a useful tool for egocentric computer vision research. Refer to our project page: https://ego-gen.github.io/.
CoVOR-SLAM: Cooperative SLAM using Visual Odometry and Ranges for Multi-Robot Systems
Nov 21, 2023
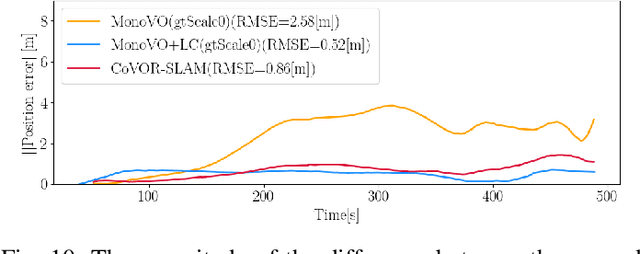

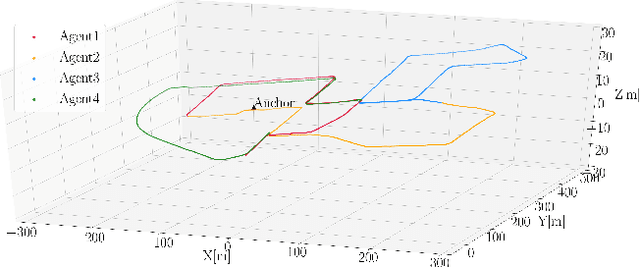
A swarm of robots has advantages over a single robot, since it can explore larger areas much faster and is more robust to single-point failures. Accurate relative positioning is necessary to successfully carry out a collaborative mission without collisions. When Visual Simultaneous Localization and Mapping (VSLAM) is used to estimate the poses of each robot, inter-agent loop closing is widely applied to reduce the relative positioning errors. This technique can mitigate errors using the feature points commonly observed by different robots. However, it requires significant computing and communication capabilities to detect inter-agent loops, and to process the data transmitted by multiple agents. In this paper, we propose Collaborative SLAM using Visual Odometry and Range measurements (CoVOR-SLAM) to overcome this challenge. In the framework of CoVOR-SLAM, robots only need to exchange pose estimates, covariances (uncertainty) of the estimates, and range measurements between robots. Since CoVOR-SLAM does not require to associate visual features and map points observed by different agents, the computational and communication loads are significantly reduced. The required range measurements can be obtained using pilot signals of the communication system, without requiring complex additional infrastructure. We tested CoVOR-SLAM using real images as well as real ultra-wideband-based ranges obtained with two rovers. In addition, CoVOR-SLAM is evaluated with a larger scale multi-agent setup exploiting public image datasets and ranges generated using a realistic simulation. The results show that CoVOR-SLAM can accurately estimate the robots' poses, requiring much less computational power and communication capabilities than the inter-agent loop closing technique.