 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoM2P: Egocentric Multimodal Multitask Pretraining
Jun 09, 2025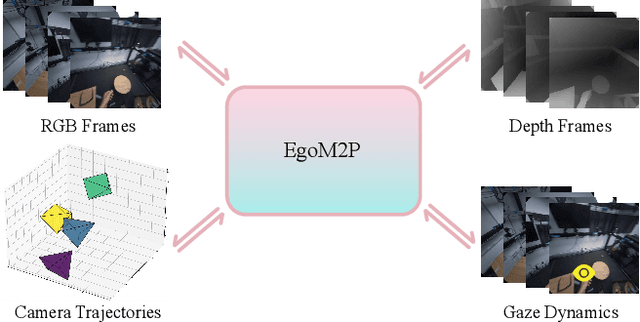

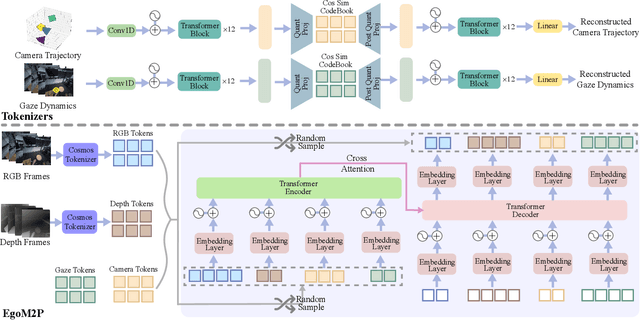
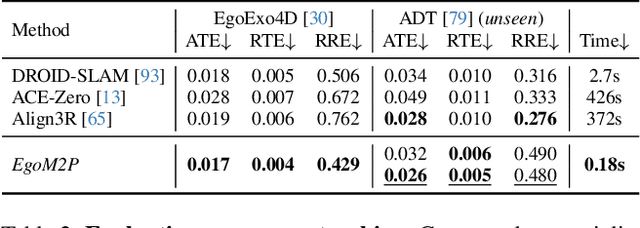
Understanding multimodal signals in egocentric vision, such as RGB video, depth, camera poses, and gaze, is essential for applications in augmented reality, robotics, and human-computer interaction. These capabilities enable systems to better interpret the camera wearer's actions, intentions, and surrounding environment. However, building large-scale egocentric multimodal and multitask models presents unique challenges. Egocentric data are inherently heterogeneous, with large variations in modality coverage across devices and settings. Generating pseudo-labels for missing modalities, such as gaze or head-mounted camera trajectories, is often infeasible, making standard supervised learning approaches difficult to scale. Furthermore, dynamic camera motion and the complex temporal and spatial structure of first-person video pose additional challenges for the direct application of existing multimodal foundation models. To address these challenges, we introduce a set of efficient temporal tokenizers and propose EgoM2P, a masked modeling framework that learns from temporally aware multimodal tokens to train a large, general-purpose model for egocentric 4D understanding. This unified design supports multitasking across diverse egocentric perception and synthesis tasks, including gaze prediction, egocentric camera tracking, and monocular depth estimation from egocentric video. EgoM2P also serves as a generative model for conditional egocentric video synthesis. Across these tasks, EgoM2P matches or outperforms specialist models while being an order of magnitude faster. We will fully open-source EgoM2P to support the community and advance egocentric vision research. Project page: https://egom2p.github.io/
DART: A Diffusion-Based Autoregressive Motion Model for Real-Time Text-Driven Motion Control
Oct 07, 2024

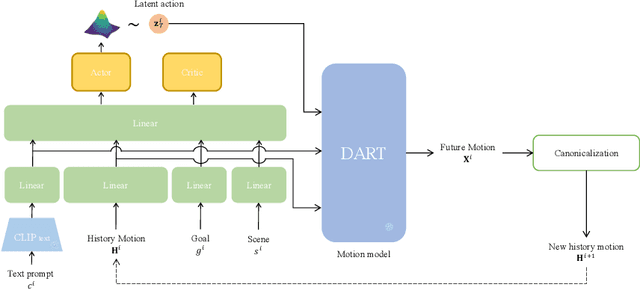
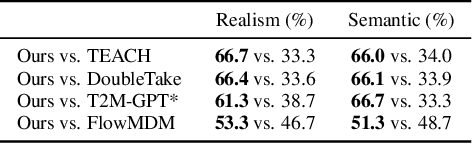
Text-conditioned human motion generation, which allows for user interaction through natural language, has become increasingly popular. Existing methods typically generate short, isolated motions based on a single input sentence. However, human motions are continuous and can extend over long periods, carrying rich semantics. Creating long, complex motions that precisely respond to streams of text descriptions, particularly in an online and real-time setting, remains a significant challenge. Furthermore, incorporating spatial constraints into text-conditioned motion generation presents additional challenges, as it requires aligning the motion semantics specified by text descriptions with geometric information, such as goal locations and 3D scene geometry. To address these limitations, we propose DART, a Diffusion-based Autoregressive motion primitive model for Real-time Text-driven motion control. Our model, DART, effectively learns a compact motion primitive space jointly conditioned on motion history and text inputs using latent diffusion models. By autoregressively generating motion primitives based on the preceding history and current text input, DART enables real-time, sequential motion generation driven by natural language descriptions. Additionally, the learned motion primitive space allows for precise spatial motion control, which we formulate either as a latent noise optimization problem or as a Markov decision process addressed through reinforcement learning. We present effective algorithms for both approaches, demonstrating our model's versatility and superior performance in various motion synthesis tasks. Experiments show our method outperforms existing baselines in motion realism, efficiency, and controllability. Video results are available on the project page: https://zkf1997.github.io/DART/.
EgoGen: An Egocentric Synthetic Data Generator
Jan 16, 2024Understanding the world in first-person view is fundamental in Augmented Reality (AR). This immersive perspective brings dramatic visual changes and unique challenges compared to third-person views. Synthetic data has empowered third-person-view vision models, but its application to embodied egocentric perception tasks remains largely unexplored. A critical challenge lies in simulating natural human movements and behaviors that effectively steer the embodied cameras to capture a faithful egocentric representation of the 3D world. To address this challenge, we introduce EgoGen, a new synthetic data generator that can produce accurate and rich ground-truth training data for egocentric perception tasks. At the heart of EgoGen is a novel human motion synthesis model that directly leverages egocentric visual inputs of a virtual human to sense the 3D environment. Combined with collision-avoiding motion primitives and a two-stage reinforcement learning approach, our motion synthesis model offers a closed-loop solution where the embodied perception and movement of the virtual human are seamlessly coupled. Compared to previous works, our model eliminates the need for a pre-defined global path, and is directly applicable to dynamic environments. Combined with our easy-to-use and scalable data generation pipeline, we demonstrate EgoGen's efficacy in three tasks: mapping and localization for head-mounted cameras, egocentric camera tracking, and human mesh recovery from egocentric views. EgoGen will be fully open-sourced, offering a practical solution for creating realistic egocentric training data and aiming to serve as a useful tool for egocentric computer vision research. Refer to our project page: https://ego-gen.github.io/.
Scalable Probabilistic Forecasting in Retail with Gradient Boosted Trees: A Practitioner's Approach
Nov 02, 2023


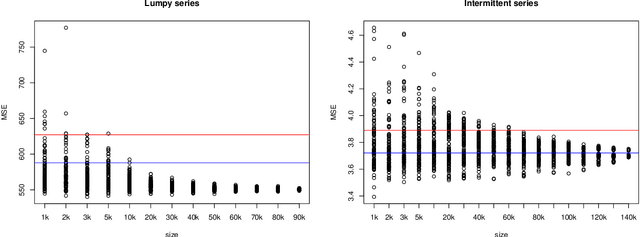
The recent M5 competition has advanced the state-of-the-art in retail forecasting. However, we notice important differences between the competition challenge and the challenges we face in a large e-commerce company. The datasets in our scenario are larger (hundreds of thousands of time series), and e-commerce can afford to have a larger assortment than brick-and-mortar retailers, leading to more intermittent data. To scale to larger dataset sizes with feasible computational effort, firstly, we investigate a two-layer hierarchy and propose a top-down approach to forecasting at an aggregated level with less amount of series and intermittency, and then disaggregating to obtain the decision-level forecasts. Probabilistic forecasts are generated under distributional assumptions. Secondly, direct training at the lower level with subsamples can also be an alternative way of scaling. Performance of modelling with subsets is evaluated with the main dataset. Apart from a proprietary dataset, the proposed scalable methods are evaluated using the Favorita dataset and the M5 dataset. We are able to show the differences in characteristics of the e-commerce and brick-and-mortar retail datasets. Notably, our top-down forecasting framework enters the top 50 of the original M5 competition, even with models trained at a higher level under a much simpler setting.
Synthesizing Diverse Human Motions in 3D Indoor Scenes
May 23, 2023



We present a novel method for populating 3D indoor scenes with virtual humans that can navigate the environment and interact with objects in a realistic manner. Existing approaches rely on high-quality training sequences that capture a diverse range of human motions in 3D scenes. However, such motion data is costly, difficult to obtain and can never cover the full range of plausible human-scene interactions in complex indoor environments. To address these challenges, we propose a reinforcement learning-based approach to learn policy networks that predict latent variables of a powerful generative motion model that is trained on a large-scale motion capture dataset (AMASS). For navigating in a 3D environment, we propose a scene-aware policy training scheme with a novel collision avoidance reward function. Combined with the powerful generative motion model, we can synthesize highly diverse human motions navigating 3D indoor scenes, meanwhile effectively avoiding obstacles. For detailed human-object interactions, we carefully curate interaction-aware reward functions by leveraging a marker-based body representation and the signed distance field (SDF) representation of the 3D scene. With a number of important training design schemes, our method can synthesize realistic and diverse human-object interactions (e.g.,~sitting on a chair and then getting up) even for out-of-distribution test scenarios with different object shapes, orientations, starting body positions, and poses. Experimental results demonstrate that our approach outperforms state-of-the-art human-scene interaction synthesis frameworks in terms of both motion naturalness and diversity. Video results are available on the project page: https://zkf1997.github.io/DIMOS.
Compositional Human-Scene Interaction Synthesis with Semantic Control
Jul 26, 2022



Synthesizing natural interactions between virtual humans and their 3D environments is critical for numerous applications, such as computer games and AR/VR experiences. Our goal is to synthesize humans interacting with a given 3D scene controlled by high-level semantic specifications as pairs of action categories and object instances, e.g., "sit on the chair". The key challenge of incorporating interaction semantics into the generation framework is to learn a joint representation that effectively captures heterogeneous information, including human body articulation, 3D object geometry, and the intent of the interaction. To address this challenge, we design a novel transformer-based generative model, in which the articulated 3D human body surface points and 3D objects are jointly encoded in a unified latent space, and the semantics of the interaction between the human and objects are embedded via positional encoding. Furthermore, inspired by the compositional nature of interactions that humans can simultaneously interact with multiple objects, we define interaction semantics as the composition of varying numbers of atomic action-object pairs. Our proposed generative model can naturally incorporate varying numbers of atomic interactions, which enables synthesizing compositional human-scene interactions without requiring composite interaction data. We extend the PROX dataset with interaction semantic labels and scene instance segmentation to evaluate our method and demonstrate that our method can generate realistic human-scene interactions with semantic control. Our perceptual study shows that our synthesized virtual humans can naturally interact with 3D scenes, considerably outperforming existing methods. We name our method COINS, for COmpositional INteraction Synthesis with Semantic Control. Code and data are available at https://github.com/zkf1997/COINS.
Revenue-based Attribution Modeling for Online Advertising
Oct 18, 2017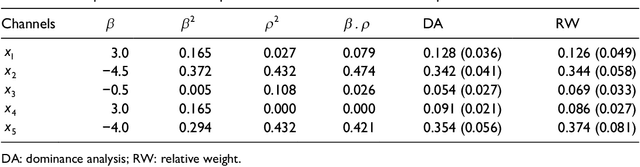
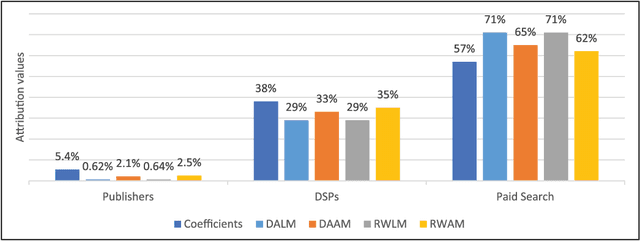


This paper examines and proposes several attribution modeling methods that quantify how revenue should be attributed to online advertising inputs. We adopt and further develop relative importance method, which is based on regression models that have been extensively studied and utilized to investigate the relationship between advertising efforts and market reaction (revenue). Relative importance method aims at decomposing and allocating marginal contributions to the coefficient of determination (R^2) of regression models as attribution values. In particular, we adopt two alternative submethods to perform this decomposition: dominance analysis and relative weight analysis. Moreover, we demonstrate an extension of the decomposition methods from standard linear model to additive model. We claim that our new approaches are more flexible and accurate in modeling the underlying relationship and calculating the attribution values. We use simulation examples to demonstrate the superior performance of our new approaches over traditional methods. We further illustrate the value of our proposed approaches using a real advertising campaign dataset.