 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeking SOTA: Time-Series Forecasting Must Adopt Taxonomy-Specific Evaluation to Dispel Illusory Gains
Mar 16, 2026We argue that the current practice of evaluating AI/ML time-series forecasting models, predominantly on benchmarks characterized by strong, persistent periodicities and seasonalities, obscures real progress by overlooking the performance of efficient classical methods. We demonstrate that these "standard" datasets often exhibit dominant autocorrelation patterns and seasonal cycles that can be effectively captured by simpler linear or statistical models, rendering complex deep learning architectures frequently no more performant than their classical counterparts for these specific data characteristics, and raising questions as to whether any marginal improvements justify the significant increase in computational overhead and model complexity. We call on the community to (I) retire or substantially augment current benchmarks with datasets exhibiting a wider spectrum of non-stationarities, such as structural breaks, time-varying volatility, and concept drift, and less predictable dynamics drawn from diverse real-world domains, and (II) require every deep learning submission to include robust classical and simple baselines, appropriately chosen for the specific characteristics of the downstream tasks' time series. By doing so, we will help ensure that reported gains reflect genuine scientific methodological advances rather than artifacts of benchmark selection favoring models adept at learning repetitive patterns.
MoTime: A Dataset Suite for Multimodal Time Series Forecasting
May 21, 2025While multimodal data sources are increasingly available from real-world forecasting, most existing research remains on unimodal time series. In this work, we present MoTime, a suite of multimodal time series forecasting datasets that pair temporal signals with external modalities such as text, metadata, and images. Covering diverse domains, MoTime supports structured evaluation of modality utility under two scenarios: 1) the common forecasting task, where varying-length history is available, and 2) cold-start forecasting, where no historical data is available. Experiments show that external modalities can improve forecasting performance in both scenarios, with particularly strong benefits for short series in some datasets, though the impact varies depending on data characteristics. By making datasets and findings publicly available, we aim to support more comprehensive and realistic benchmarks in future multimodal time series forecasting research.
Unveiling the Potential of Text in High-Dimensional Time Series Forecasting
Jan 13, 2025


Time series forecasting has traditionally focused on univariate and multivariate numerical data, often overlooking the benefits of incorporating multimodal information, particularly textual data. In this paper, we propose a novel framework that integrates time series models with Large Language Models to improve high-dimensional time series forecasting. Inspired by multimodal models, our method combines time series and textual data in the dual-tower structure. This fusion of information creates a comprehensive representation, which is then processed through a linear layer to generate the final forecast. Extensive experiments demonstrate that incorporating text enhances high-dimensional time series forecasting performance. This work paves the way for further research in multimodal time series forecasting.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Scalable Transformer for High Dimensional Multivariate Time Series Forecasting
Aug 08, 2024



Deep models for Multivariate Time Series (MTS) forecasting have recently demonstrated significant success. Channel-dependent models capture complex dependencies that channel-independent models cannot capture. However, the number of channels in real-world applications outpaces the capabilities of existing channel-dependent models, and contrary to common expectations, some models underperform the channel-independent models in handling high-dimensional data, which raises questions about the performance of channel-dependent models. To address this, our study first investigates the reasons behind the suboptimal performance of these channel-dependent models on high-dimensional MTS data. Our analysis reveals that two primary issues lie in the introduced noise from unrelated series that increases the difficulty of capturing the crucial inter-channel dependencies, and challenges in training strategies due to high-dimensional data. To address these issues, we propose STHD, the Scalable Transformer for High-Dimensional Multivariate Time Series Forecasting. STHD has three components: a) Relation Matrix Sparsity that limits the noise introduced and alleviates the memory issue; b) ReIndex applied as a training strategy to enable a more flexible batch size setting and increase the diversity of training data; and c) Transformer that handles 2-D inputs and captures channel dependencies. These components jointly enable STHD to manage the high-dimensional MTS while maintaining computational feasibility. Furthermore, experimental results show STHD's considerable improvement on three high-dimensional datasets: Crime-Chicago, Wiki-People, and Traffic. The source code and dataset are publicly available https://github.com/xinzzzhou/ScalableTransformer4HighDimensionMTSF.git.
Predict. Optimize. Revise. On Forecast and Policy Stability in Energy Management Systems
Jun 29, 2024



This research addresses the challenge of integrating forecasting and optimization in energy management systems, focusing on the impacts of switching costs, forecast accuracy, and stability. It proposes a novel framework for analyzing online optimization problems with switching costs and enabled by deterministic and probabilistic forecasts. Through empirical evaluation and theoretical analysis, the research reveals the balance between forecast accuracy, stability, and switching costs in shaping policy performance. Conducted in the context of battery scheduling within energy management applications, it introduces a metric for evaluating probabilistic forecast stability and examines the effects of forecast accuracy and stability on optimization outcomes using the real-world case of the Citylearn 2022 competition. Findings indicate that switching costs significantly influence the trade-off between forecast accuracy and stability, highlighting the importance of integrated systems that enable collaboration between forecasting and operational units for improved decision-making. The study shows that committing to a policy for longer periods can be advantageous over frequent updates. Results also show a correlation between forecast stability and policy performance, suggesting that stable forecasts can mitigate switching costs. The proposed framework provides valuable insights for energy sector decision-makers and forecast practitioners when designing the operation of an energy management system.
Fast Gibbs sampling for the local and global trend Bayesian exponential smoothing model
Jun 29, 2024


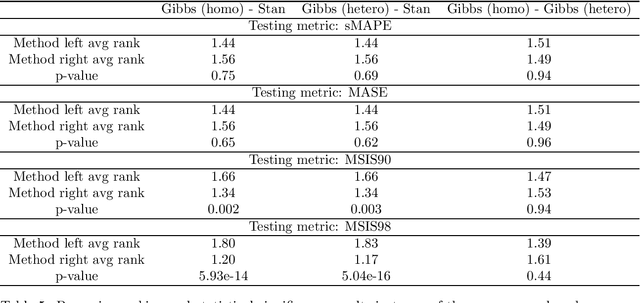
In Smyl et al. [Local and global trend Bayesian exponential smoothing models. International Journal of Forecasting, 2024.], a generalised exponential smoothing model was proposed that is able to capture strong trends and volatility in time series. This method achieved state-of-the-art performance in many forecasting tasks, but its fitting procedure, which is based on the NUTS sampler, is very computationally expensive. In this work, we propose several modifications to the original model, as well as a bespoke Gibbs sampler for posterior exploration; these changes improve sampling time by an order of magnitude, thus rendering the model much more practically relevant. The new model, and sampler, are evaluated on the M3 dataset and are shown to be competitive, or superior, in terms of accuracy to the original method, while being substantially faster to run.
DeepHGNN: Study of Graph Neural Network based Forecasting Methods for Hierarchically Related Multivariate Time Series
May 29, 2024Graph Neural Networks (GNN) have gained significant traction in the forecasting domain, especially for their capacity to simultaneously account for intra-series temporal correlations and inter-series relationships. This paper introduces a novel Hierarchical GNN (DeepHGNN) framework, explicitly designed for forecasting in complex hierarchical structures. The uniqueness of DeepHGNN lies in its innovative graph-based hierarchical interpolation and an end-to-end reconciliation mechanism. This approach ensures forecast accuracy and coherence across various hierarchical levels while sharing signals across them, addressing a key challenge in hierarchical forecasting. A critical insight in hierarchical time series is the variance in forecastability across levels, with upper levels typically presenting more predictable components. DeepHGNN capitalizes on this insight by pooling and leveraging knowledge from all hierarchy levels, thereby enhancing the overall forecast accuracy. Our comprehensive evaluation set against several state-of-the-art models confirm the superior performance of DeepHGNN. This research not only demonstrates DeepHGNN's effectiveness in achieving significantly improved forecast accuracy but also contributes to the understanding of graph-based methods in hierarchical time series forecasting.
Context Neural Networks: A Scalable Multivariate Model for Time Series Forecasting
May 12, 2024



Real-world time series often exhibit complex interdependencies that cannot be captured in isolation. Global models that model past data from multiple related time series globally while producing series-specific forecasts locally are now common. However, their forecasts for each individual series remain isolated, failing to account for the current state of its neighbouring series. Multivariate models like multivariate attention and graph neural networks can explicitly incorporate inter-series information, thus addressing the shortcomings of global models. However, these techniques exhibit quadratic complexity per timestep, limiting scalability. This paper introduces the Context Neural Network, an efficient linear complexity approach for augmenting time series models with relevant contextual insights from neighbouring time series without significant computational overhead. The proposed method enriches predictive models by providing the target series with real-time information from its neighbours, addressing the limitations of global models, yet remaining computationally tractable for large datasets.
Adaptive Dependency Learning Graph Neural Networks
Dec 06, 2023
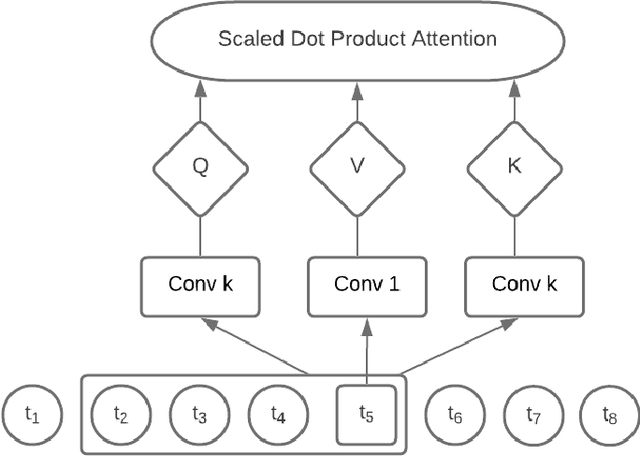
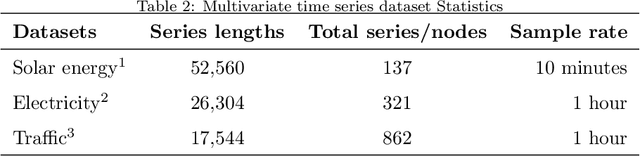
Graph Neural Networks (GNN) have recently gained popularity in the forecasting domain due to their ability to model complex spatial and temporal patterns in tasks such as traffic forecasting and region-based demand forecasting. Most of these methods require a predefined graph as input, whereas in real-life multivariate time series problems, a well-predefined dependency graph rarely exists. This requirement makes it harder for GNNs to be utilised widely for multivariate forecasting problems in other domains such as retail or energy. In this paper, we propose a hybrid approach combining neural networks and statistical structure learning models to self-learn the dependencies and construct a dynamically changing dependency graph from multivariate data aiming to enable the use of GNNs for multivariate forecasting even when a well-defined graph does not exist. The statistical structure modeling in conjunction with neural networks provides a well-principled and efficient approach by bringing in causal semantics to determine dependencies among the series. Finally, we demonstrate significantly improved performance using our proposed approach on real-world benchmark datasets without a pre-defined dependency graph.