 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredict. Optimize. Revise. On Forecast and Policy Stability in Energy Management Systems
Jun 29, 2024



This research addresses the challenge of integrating forecasting and optimization in energy management systems, focusing on the impacts of switching costs, forecast accuracy, and stability. It proposes a novel framework for analyzing online optimization problems with switching costs and enabled by deterministic and probabilistic forecasts. Through empirical evaluation and theoretical analysis, the research reveals the balance between forecast accuracy, stability, and switching costs in shaping policy performance. Conducted in the context of battery scheduling within energy management applications, it introduces a metric for evaluating probabilistic forecast stability and examines the effects of forecast accuracy and stability on optimization outcomes using the real-world case of the Citylearn 2022 competition. Findings indicate that switching costs significantly influence the trade-off between forecast accuracy and stability, highlighting the importance of integrated systems that enable collaboration between forecasting and operational units for improved decision-making. The study shows that committing to a policy for longer periods can be advantageous over frequent updates. Results also show a correlation between forecast stability and policy performance, suggesting that stable forecasts can mitigate switching costs. The proposed framework provides valuable insights for energy sector decision-makers and forecast practitioners when designing the operation of an energy management system.
An Empirical Study on the Joint Impact of Feature Selection and Data Resampling on Imbalance Classification
Sep 01, 2021

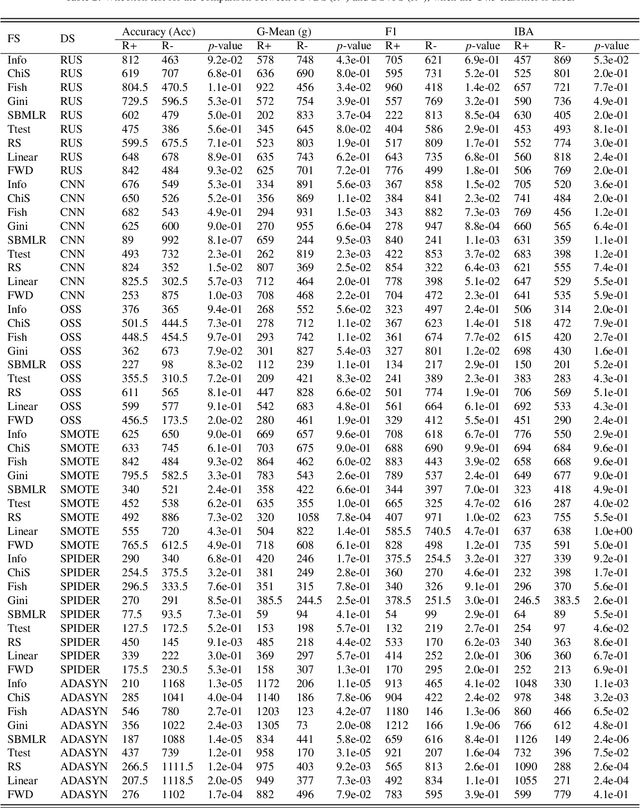

Real-world datasets often present different degrees of imbalanced (i.e., long-tailed or skewed) distributions. While the majority (a.k.a., head or frequent) classes have sufficient samples, the minority (a.k.a., tail or rare) classes can be under-represented by a rather limited number of samples. On one hand, data resampling is a common approach to tackling class imbalance. On the other hand, dimension reduction, which reduces the feature space, is a conventional machine learning technique for building stronger classification models on a dataset. However, the possible synergy between feature selection and data resampling for high-performance imbalance classification has rarely been investigated before. To address this issue, this paper carries out a comprehensive empirical study on the joint influence of feature selection and resampling on two-class imbalance classification. Specifically, we study the performance of two opposite pipelines for imbalance classification, i.e., applying feature selection before or after data resampling. We conduct a large amount of experiments (a total of 9225 experiments) on 52 publicly available datasets, using 9 feature selection methods, 6 resampling approaches for class imbalance learning, and 3 well-known classification algorithms. Experimental results show that there is no constant winner between the two pipelines, thus both of them should be considered to derive the best performing model for imbalance classification. We also find that the performance of an imbalance classification model depends on the classifier adopted, the ratio between the number of majority and minority samples (IR), as well as on the ratio between the number of samples and features (SFR). Overall, this study should provide new reference value for researchers and practitioners in imbalance learning.