 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUARD: Glocal Uncertainty-Aware Robust Decoding for Effective and Efficient Open-Ended Text Generation
Aug 28, 2025

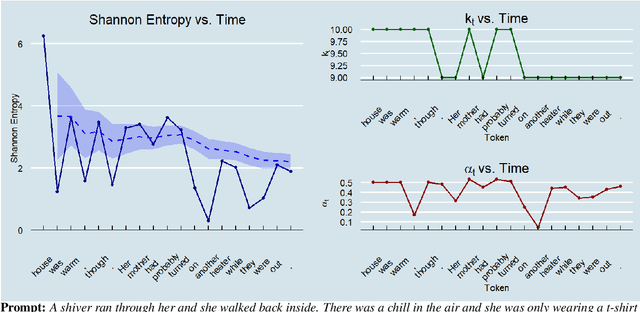

Open-ended text generation faces a critical challenge: balancing coherence with diversity in LLM outputs. While contrastive search-based decoding strategies have emerged to address this trade-off, their practical utility is often limited by hyperparameter dependence and high computational costs. We introduce GUARD, a self-adaptive decoding method that effectively balances these competing objectives through a novel "Glocal" uncertainty-driven framework. GUARD combines global entropy estimates with local entropy deviations to integrate both long-term and short-term uncertainty signals. We demonstrate that our proposed global entropy formulation effectively mitigates abrupt variations in uncertainty, such as sudden overconfidence or high entropy spikes, and provides theoretical guarantees of unbiasedness and consistency. To reduce computational overhead, we incorporate a simple yet effective token-count-based penalty into GUARD. Experimental results demonstrate that GUARD achieves a good balance between text diversity and coherence, while exhibiting substantial improvements in generation speed. In a more nuanced comparison study across different dimensions of text quality, both human and LLM evaluators validated its remarkable performance. Our code is available at https://github.com/YecanLee/GUARD.
OBD-Finder: Explainable Coarse-to-Fine Text-Centric Oracle Bone Duplicates Discovery
May 04, 2025



Oracle Bone Inscription (OBI) is the earliest systematic writing system in China, while the identification of Oracle Bone (OB) duplicates is a fundamental issue in OBI research. In this work, we design a progressive OB duplicate discovery framework that combines unsupervised low-level keypoints matching with high-level text-centric content-based matching to refine and rank the candidate OB duplicates with semantic awareness and interpretability. We compare our approach with state-of-the-art content-based image retrieval and image matching methods, showing that our approach yields comparable recall performance and the highest simplified mean reciprocal rank scores for both Top-5 and Top-15 retrieval results, and with significantly accelerated computation efficiency. We have discovered over 60 pairs of new OB duplicates in real-world deployment, which were missed by OBI researchers for decades. The models, video illustration and demonstration of this work are available at: https://github.com/cszhangLMU/OBD-Finder/.
A Systematic Review on Long-Tailed Learning
Aug 01, 2024



Long-tailed data is a special type of multi-class imbalanced data with a very large amount of minority/tail classes that have a very significant combined influence. Long-tailed learning aims to build high-performance models on datasets with long-tailed distributions, which can identify all the classes with high accuracy, in particular the minority/tail classes. It is a cutting-edge research direction that has attracted a remarkable amount of research effort in the past few years. In this paper, we present a comprehensive survey of latest advances in long-tailed visual learning. We first propose a new taxonomy for long-tailed learning, which consists of eight different dimensions, including data balancing, neural architecture, feature enrichment, logits adjustment, loss function, bells and whistles, network optimization, and post hoc processing techniques. Based on our proposed taxonomy, we present a systematic review of long-tailed learning methods, discussing their commonalities and alignable differences. We also analyze the differences between imbalance learning and long-tailed learning approaches. Finally, we discuss prospects and future directions in this field.
An Empirical Study on the Joint Impact of Feature Selection and Data Resampling on Imbalance Classification
Sep 01, 2021

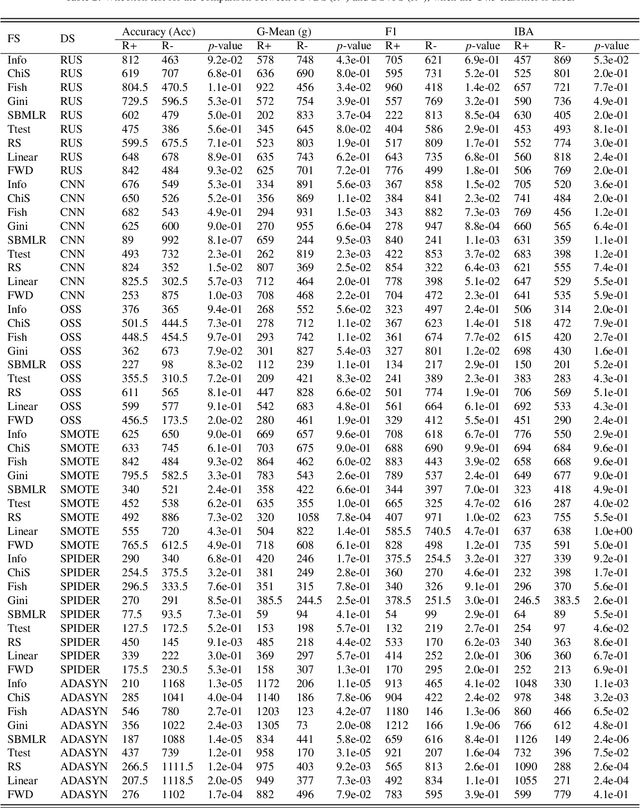

Real-world datasets often present different degrees of imbalanced (i.e., long-tailed or skewed) distributions. While the majority (a.k.a., head or frequent) classes have sufficient samples, the minority (a.k.a., tail or rare) classes can be under-represented by a rather limited number of samples. On one hand, data resampling is a common approach to tackling class imbalance. On the other hand, dimension reduction, which reduces the feature space, is a conventional machine learning technique for building stronger classification models on a dataset. However, the possible synergy between feature selection and data resampling for high-performance imbalance classification has rarely been investigated before. To address this issue, this paper carries out a comprehensive empirical study on the joint influence of feature selection and resampling on two-class imbalance classification. Specifically, we study the performance of two opposite pipelines for imbalance classification, i.e., applying feature selection before or after data resampling. We conduct a large amount of experiments (a total of 9225 experiments) on 52 publicly available datasets, using 9 feature selection methods, 6 resampling approaches for class imbalance learning, and 3 well-known classification algorithms. Experimental results show that there is no constant winner between the two pipelines, thus both of them should be considered to derive the best performing model for imbalance classification. We also find that the performance of an imbalance classification model depends on the classifier adopted, the ratio between the number of majority and minority samples (IR), as well as on the ratio between the number of samples and features (SFR). Overall, this study should provide new reference value for researchers and practitioners in imbalance learning.