 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation? Exploring the Shift in Grammatical Gender from Latin to Occitan
May 09, 2026The diachronic evolution from Latin to the Romance languages involved a restructuring of the grammatical gender system from a tripartite configuration (masculine, feminine, neuter) to a bipartite one (masculine, feminine). In this work, we introduce an interpretable deep learning framework to investigate this phenomenon at both lexical and contextual levels. First, we show that conventional tokenization strategies are insufficiently robust for this low-resource historical setting, and that our proposed tokenizer improves performance over these baselines. At the lexical level, we evaluate the contribution of morphological features to gender prediction. At the contextual level, we quantify the contributions of different part-of-speech categories to grammatical gender prediction. Together, these analyses characterize the distribution of gender information between the lemma and its sentential context. We make our codebase, datasets, and results publicly available.
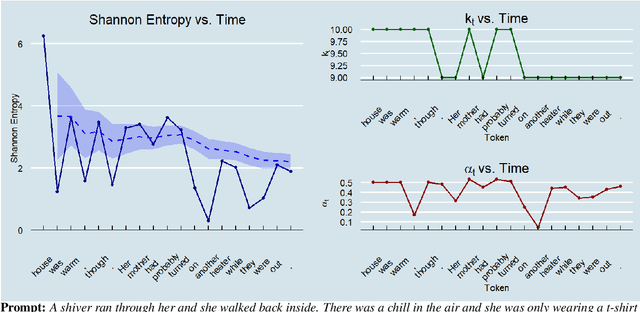
Min-$k$ Sampling: Decoupling Truncation from Temperature Scaling via Relative Logit Dynamics
Apr 13, 2026The quality of text generated by large language models depends critically on the decoding sampling strategy. While mainstream methods such as Top-$k$, Top-$p$, and Min-$p$ achieve a balance between diversity and accuracy through probability-space truncation, they share an inherent limitation: extreme sensitivity to the temperature parameter. Recent logit-space approaches like Top-$nσ$ achieve temperature invariance but rely on global statistics that are susceptible to long-tail noise, failing to capture fine-grained confidence structures among top candidates. We propose \textbf{Min-$k$ Sampling}, a novel dynamic truncation strategy that analyzes the local shape of the sorted logit distribution to identify "semantic cliffs": sharp transitions from high-confidence core tokens to uncertain long-tail tokens. By computing a position-weighted relative decay rate, Min-$k$ dynamically determines truncation boundaries at each generation step. We formally prove that Min-$k$ achieves strict temperature invariance and empirically demonstrate its low sensitivity to hyperparameter choices. Experiments on multiple reasoning benchmarks, creative writing tasks, and human evaluation show that Min-$k$ consistently improves text quality, maintaining robust performance even under extreme temperature settings where probability-based methods collapse. We make our code, models, and analysis tools publicly available.
The Truncation Blind Spot: How Decoding Strategies Systematically Exclude Human-Like Token Choices
Mar 19, 2026Standard decoding strategies for text generation, including top-k, nucleus sampling, and contrastive search, select tokens based on likelihood, restricting selection to high-probability regions. Human language production operates differently: tokens are chosen for communicative appropriateness rather than statistical frequency. This mismatch creates a truncation blind spot: contextually appropriate but statistically rare tokens remain accessible to humans yet unreachable by likelihood-based decoding. We hypothesize this contributes to the detectability of machine-generated text. Analyzing over 1.8 million texts across eight language models, five decoding strategies, and 53 hyperparameter configurations, we find that 8-18% of human-selected tokens fall outside typical truncation boundaries. Simple classifiers trained on predictability and lexical diversity achieve remarkable detection rates. Crucially, neither model scale nor architecture correlates strongly with detectability; truncation parameters account for most variance. Configurations achieving low detectability often produce incoherent text, indicating that evading detection and producing natural text are distinct objectives. These findings suggest detectability is enhanced by likelihood-based token selection, not merely a matter of model capability.
GUARD: Glocal Uncertainty-Aware Robust Decoding for Effective and Efficient Open-Ended Text Generation
Aug 28, 2025


Open-ended text generation faces a critical challenge: balancing coherence with diversity in LLM outputs. While contrastive search-based decoding strategies have emerged to address this trade-off, their practical utility is often limited by hyperparameter dependence and high computational costs. We introduce GUARD, a self-adaptive decoding method that effectively balances these competing objectives through a novel "Glocal" uncertainty-driven framework. GUARD combines global entropy estimates with local entropy deviations to integrate both long-term and short-term uncertainty signals. We demonstrate that our proposed global entropy formulation effectively mitigates abrupt variations in uncertainty, such as sudden overconfidence or high entropy spikes, and provides theoretical guarantees of unbiasedness and consistency. To reduce computational overhead, we incorporate a simple yet effective token-count-based penalty into GUARD. Experimental results demonstrate that GUARD achieves a good balance between text diversity and coherence, while exhibiting substantial improvements in generation speed. In a more nuanced comparison study across different dimensions of text quality, both human and LLM evaluators validated its remarkable performance. Our code is available at https://github.com/YecanLee/GUARD.
Revisiting Active Learning under (Human) Label Variation
Jul 03, 2025Access to high-quality labeled data remains a limiting factor in applied supervised learning. While label variation (LV), i.e., differing labels for the same instance, is common, especially in natural language processing, annotation frameworks often still rest on the assumption of a single ground truth. This overlooks human label variation (HLV), the occurrence of plausible differences in annotations, as an informative signal. Similarly, active learning (AL), a popular approach to optimizing the use of limited annotation budgets in training ML models, often relies on at least one of several simplifying assumptions, which rarely hold in practice when acknowledging HLV. In this paper, we examine foundational assumptions about truth and label nature, highlighting the need to decompose observed LV into signal (e.g., HLV) and noise (e.g., annotation error). We survey how the AL and (H)LV communities have addressed -- or neglected -- these distinctions and propose a conceptual framework for incorporating HLV throughout the AL loop, including instance selection, annotator choice, and label representation. We further discuss the integration of large language models (LLM) as annotators. Our work aims to lay a conceptual foundation for HLV-aware active learning, better reflecting the complexities of real-world annotation.
OBD-Finder: Explainable Coarse-to-Fine Text-Centric Oracle Bone Duplicates Discovery
May 04, 2025



Oracle Bone Inscription (OBI) is the earliest systematic writing system in China, while the identification of Oracle Bone (OB) duplicates is a fundamental issue in OBI research. In this work, we design a progressive OB duplicate discovery framework that combines unsupervised low-level keypoints matching with high-level text-centric content-based matching to refine and rank the candidate OB duplicates with semantic awareness and interpretability. We compare our approach with state-of-the-art content-based image retrieval and image matching methods, showing that our approach yields comparable recall performance and the highest simplified mean reciprocal rank scores for both Top-5 and Top-15 retrieval results, and with significantly accelerated computation efficiency. We have discovered over 60 pairs of new OB duplicates in real-world deployment, which were missed by OBI researchers for decades. The models, video illustration and demonstration of this work are available at: https://github.com/cszhangLMU/OBD-Finder/.
Modern Models, Medieval Texts: A POS Tagging Study of Old Occitan
Mar 10, 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language processing, yet their effectiveness in handling historical languages remains largely unexplored. This study examines the performance of open-source LLMs in part-of-speech (POS) tagging for Old Occitan, a historical language characterized by non-standardized orthography and significant diachronic variation. Through comparative analysis of two distinct corpora-hagiographical and medical texts-we evaluate how current models handle the inherent challenges of processing a low-resource historical language. Our findings demonstrate critical limitations in LLM performance when confronted with extreme orthographic and syntactic variability. We provide detailed error analysis and specific recommendations for improving model performance in historical language processing. This research advances our understanding of LLM capabilities in challenging linguistic contexts while offering practical insights for both computational linguistics and historical language studies.
Towards Better Open-Ended Text Generation: A Multicriteria Evaluation Framework
Oct 24, 2024



Open-ended text generation has become a prominent task in natural language processing due to the rise of powerful (large) language models. However, evaluating the quality of these models and the employed decoding strategies remains challenging because of trade-offs among widely used metrics such as coherence, diversity, and perplexity. Decoding methods often excel in some metrics while underperforming in others, complicating the establishment of a clear ranking. In this paper, we present novel ranking strategies within this multicriteria framework. Specifically, we employ benchmarking approaches based on partial orderings and present a new summary metric designed to balance existing automatic indicators, providing a more holistic evaluation of text generation quality. Furthermore, we discuss the alignment of these approaches with human judgments. Our experiments demonstrate that the proposed methods offer a robust way to compare decoding strategies, exhibit similarities with human preferences, and serve as valuable tools in guiding model selection for open-ended text generation tasks. Finally, we suggest future directions for improving evaluation methodologies in text generation. Our codebase, datasets, and models are publicly available.
Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation
Oct 08, 2024Decoding strategies for large language models (LLMs) are a critical but often underexplored aspect of text generation tasks. Since LLMs produce probability distributions over the entire vocabulary, various decoding methods have been developed to transform these probabilities into coherent and fluent text, each with its own set of hyperparameters. In this study, we present a large-scale, comprehensive analysis of how hyperparameter selection affects text quality in open-ended text generation across multiple LLMs, datasets, and evaluation metrics. Through an extensive sensitivity analysis, we provide practical guidelines for hyperparameter tuning and demonstrate the substantial influence of these choices on text quality. Using three established datasets, spanning factual domains (e.g., news) and creative domains (e.g., fiction), we show that hyperparameter tuning significantly impacts generation quality, though its effects vary across models and tasks. We offer in-depth insights into these effects, supported by both human evaluations and a synthesis of widely-used automatic evaluation metrics.
Can OpenSource beat ChatGPT? -- A Comparative Study of Large Language Models for Text-to-Code Generation
Sep 06, 2024In recent years, large language models (LLMs) have emerged as powerful tools with potential applications in various fields, including software engineering. Within the scope of this research, we evaluate five different state-of-the-art LLMs - Bard, BingChat, ChatGPT, Llama2, and Code Llama - concerning their capabilities for text-to-code generation. In an empirical study, we feed prompts with textual descriptions of coding problems sourced from the programming website LeetCode to the models with the task of creating solutions in Python. Subsequently, the quality of the generated outputs is assessed using the testing functionalities of LeetCode. The results indicate large differences in performance between the investigated models. ChatGPT can handle these typical programming challenges by far the most effectively, surpassing even code-specialized models like Code Llama. To gain further insights, we measure the runtime as well as the memory usage of the generated outputs and compared them to the other code submissions on Leetcode. A detailed error analysis, encompassing a comparison of the differences concerning correct indentation and form of the generated code as well as an assignment of the incorrectly solved tasks to certain error categories allows us to obtain a more nuanced picture of the results and potential for improvement. The results also show a clear pattern of increasingly incorrect produced code when the models are facing a lot of context in the form of longer prompts.