 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Hallucinations: Information-Theoretic Guarantees for RAG Systems via Merlin-Arthur Protocols
Dec 12, 2025Retrieval-augmented generation (RAG) models rely on retrieved evidence to guide large language model (LLM) generators, yet current systems treat retrieval as a weak heuristic rather than verifiable evidence. As a result, LLMs answer without support, hallucinate under incomplete or misleading context, and rely on spurious evidence. We introduce a training framework that treats the entire RAG pipeline -- both the retriever and the generator -- as an interactive proof system via an adaptation of the Merlin-Arthur (M/A) protocol. Arthur (the generator LLM) trains on questions of unkown provenance: Merlin provides helpful evidence, while Morgana injects adversarial, misleading context. Both use a linear-time XAI method to identify and modify the evidence most influential to Arthur. Consequently, Arthur learns to (i) answer when the context support the answer, (ii) reject when evidence is insufficient, and (iii) rely on the specific context spans that truly ground the answer. We further introduce a rigorous evaluation framework to disentangle explanation fidelity from baseline predictive errors. This allows us to introduce and measure the Explained Information Fraction (EIF), which normalizes M/A certified mutual-information guarantees relative to model capacity and imperfect benchmarks. Across three RAG datasets and two model families of varying sizes, M/A-trained LLMs show improved groundedness, completeness, soundness, and reject behavior, as well as reduced hallucinations -- without needing manually annotated unanswerable questions. The retriever likewise improves recall and MRR through automatically generated M/A hard positives and negatives. Our results demonstrate that autonomous interactive-proof-style supervision provides a principled and practical path toward reliable RAG systems that treat retrieved documents not as suggestions, but as verifiable evidence.
LIME: Making LLM Data More Efficient with Linguistic Metadata Embeddings
Dec 08, 2025Pre-training decoder-only language models relies on vast amounts of high-quality data, yet the availability of such data is increasingly reaching its limits. While metadata is commonly used to create and curate these datasets, its potential as a direct training signal remains under-explored. We challenge this status quo and propose LIME (Linguistic Metadata Embeddings), a method that enriches token embeddings with metadata capturing syntax, semantics, and contextual properties. LIME substantially improves pre-training efficiency. Specifically, it adapts up to 56% faster to the training data distribution, while introducing only 0.01% additional parameters at negligible compute overhead. Beyond efficiency, LIME improves tokenization, leading to remarkably stronger language modeling capabilities and generative task performance. These benefits persist across model scales (500M to 2B). In addition, we develop a variant with shifted metadata, LIME+1, that can guide token generation. Given prior metadata for the next token, LIME+1 improves reasoning performance by up to 38% and arithmetic accuracy by up to 35%.
Measuring and Guiding Monosemanticity
Jun 24, 2025There is growing interest in leveraging mechanistic interpretability and controllability to better understand and influence the internal dynamics of large language models (LLMs). However, current methods face fundamental challenges in reliably localizing and manipulating feature representations. Sparse Autoencoders (SAEs) have recently emerged as a promising direction for feature extraction at scale, yet they, too, are limited by incomplete feature isolation and unreliable monosemanticity. To systematically quantify these limitations, we introduce Feature Monosemanticity Score (FMS), a novel metric to quantify feature monosemanticity in latent representation. Building on these insights, we propose Guided Sparse Autoencoders (G-SAE), a method that conditions latent representations on labeled concepts during training. We demonstrate that reliable localization and disentanglement of target concepts within the latent space improve interpretability, detection of behavior, and control. Specifically, our evaluations on toxicity detection, writing style identification, and privacy attribute recognition show that G-SAE not only enhances monosemanticity but also enables more effective and fine-grained steering with less quality degradation. Our findings provide actionable guidelines for measuring and advancing mechanistic interpretability and control of LLMs.
Aleph-Alpha-GermanWeb: Improving German-language LLM pre-training with model-based data curation and synthetic data generation
Apr 24, 2025Scaling data quantity is essential for large language models (LLMs), yet recent findings show that data quality can significantly boost performance and training efficiency. We introduce a German-language dataset curation pipeline that combines heuristic and model-based filtering techniques with synthetic data generation. We use our pipeline to create Aleph-Alpha-GermanWeb, a large-scale German pre-training dataset which draws from: (1) Common Crawl web data, (2) FineWeb2, and (3) synthetically-generated data conditioned on actual, organic web data. We evaluate our dataset by pre-training both a 1B Llama-style model and an 8B tokenizer-free hierarchical autoregressive transformer (HAT). A comparison on German-language benchmarks, including MMMLU, shows significant performance gains of Aleph-Alpha-GermanWeb over FineWeb2 alone. This advantage holds at the 8B scale even when FineWeb2 is enriched by human-curated high-quality data sources such as Wikipedia. Our findings support the growing body of evidence that model-based data curation and synthetic data generation can significantly enhance LLM pre-training datasets.
Hierarchical Autoregressive Transformers: Combining Byte-~and Word-Level Processing for Robust, Adaptable Language Models
Jan 17, 2025



Tokenization is a fundamental step in natural language processing, breaking text into units that computational models can process. While learned subword tokenizers have become the de-facto standard, they present challenges such as large vocabularies, limited adaptability to new domains or languages, and sensitivity to spelling errors and variations. To overcome these limitations, we investigate a hierarchical architecture for autoregressive language modelling that combines character-level and word-level processing. It employs a lightweight character-level encoder to convert character sequences into word embeddings, which are then processed by a word-level backbone model and decoded back into characters via a compact character-level decoder. This method retains the sequence compression benefits of word-level tokenization without relying on a rigid, predefined vocabulary. We demonstrate, at scales up to 7 billion parameters, that hierarchical transformers match the downstream task performance of subword-tokenizer-based models while exhibiting significantly greater robustness to input perturbations. Additionally, during continued pretraining on an out-of-domain language, our model trains almost twice as fast, achieves superior performance on the target language, and retains more of its previously learned knowledge. Hierarchical transformers pave the way for NLP systems that are more robust, flexible, and generalizable across languages and domains.
SCAR: Sparse Conditioned Autoencoders for Concept Detection and Steering in LLMs
Nov 11, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities in generating human-like text, but their output may not be aligned with the user or even produce harmful content. This paper presents a novel approach to detect and steer concepts such as toxicity before generation. We introduce the Sparse Conditioned Autoencoder (SCAR), a single trained module that extends the otherwise untouched LLM. SCAR ensures full steerability, towards and away from concepts (e.g., toxic content), without compromising the quality of the model's text generation on standard evaluation benchmarks. We demonstrate the effective application of our approach through a variety of concepts, including toxicity, safety, and writing style alignment. As such, this work establishes a robust framework for controlling LLM generations, ensuring their ethical and safe deployment in real-world applications.
u-$μ$P: The Unit-Scaled Maximal Update Parametrization
Jul 24, 2024The Maximal Update Parametrization ($\mu$P) aims to make the optimal hyperparameters (HPs) of a model independent of its size, allowing them to be swept using a cheap proxy model rather than the full-size target model. We present a new scheme, u-$\mu$P, which improves upon $\mu$P by combining it with Unit Scaling, a method for designing models that makes them easy to train in low-precision. The two techniques have a natural affinity: $\mu$P ensures that the scale of activations is independent of model size, and Unit Scaling ensures that activations, weights and gradients begin training with a scale of one. This synthesis opens the door to a simpler scheme, whose default values are near-optimal. This in turn facilitates a more efficient sweeping strategy, with u-$\mu$P models reaching a lower loss than comparable $\mu$P models and working out-of-the-box in FP8.
T-FREE: Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings
Jun 27, 2024



Tokenizers are crucial for encoding information in Large Language Models, but their development has recently stagnated, and they contain inherent weaknesses. Major limitations include computational overhead, ineffective vocabulary use, and unnecessarily large embedding and head layers. Additionally, their performance is biased towards a reference corpus, leading to reduced effectiveness for underrepresented languages. To remedy these issues, we propose T-FREE, which directly embeds words through sparse activation patterns over character triplets, and does not require a reference corpus. T-FREE inherently exploits morphological similarities and allows for strong compression of embedding layers. In our exhaustive experimental evaluation, we achieve competitive downstream performance with a parameter reduction of more than 85% on these layers. Further, T-FREE shows significant improvements in cross-lingual transfer learning.
Mechanistic Design and Scaling of Hybrid Architectures
Mar 26, 2024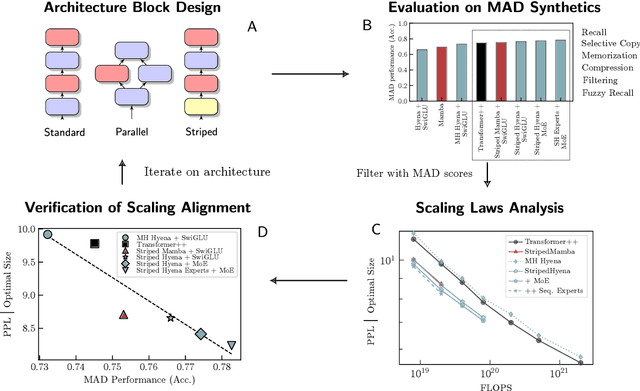

The development of deep learning architectures is a resource-demanding process, due to a vast design space, long prototyping times, and high compute costs associated with at-scale model training and evaluation. We set out to simplify this process by grounding it in an end-to-end mechanistic architecture design (MAD) pipeline, encompassing small-scale capability unit tests predictive of scaling laws. Through a suite of synthetic token manipulation tasks such as compression and recall, designed to probe capabilities, we identify and test new hybrid architectures constructed from a variety of computational primitives. We experimentally validate the resulting architectures via an extensive compute-optimal and a new state-optimal scaling law analysis, training over 500 language models between 70M to 7B parameters. Surprisingly, we find MAD synthetics to correlate with compute-optimal perplexity, enabling accurate evaluation of new architectures via isolated proxy tasks. The new architectures found via MAD, based on simple ideas such as hybridization and sparsity, outperform state-of-the-art Transformer, convolutional, and recurrent architectures (Transformer++, Hyena, Mamba) in scaling, both at compute-optimal budgets and in overtrained regimes. Overall, these results provide evidence that performance on curated synthetic tasks can be predictive of scaling laws, and that an optimal architecture should leverage specialized layers via a hybrid topology.
Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization
Nov 13, 2023Large Language Models (LLMs) have reshaped natural language processing with their impressive capabilities. Their ever-increasing size, however, raised concerns about their effective deployment and the need for LLM compressions. This study introduces the Divergent Token metrics (DTMs), a novel approach for assessing compressed LLMs, addressing the limitations of traditional perplexity or accuracy measures that fail to accurately reflect text generation quality. DTMs focus on token divergence, that allow deeper insights into the subtleties of model compression, i.p. when evaluating component's impacts individually. Utilizing the First Divergent Token metric (FDTM) in model sparsification reveals that a quarter of all attention components can be pruned beyond 90% on the Llama-2 model family, still keeping SOTA performance. For quantization FDTM suggests that over 80% of parameters can naively be transformed to int8 without special outlier management. These evaluations indicate the necessity of choosing appropriate compressions for parameters individually-and that FDTM can identify those-while standard metrics result in deteriorated outcomes.