 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Safe Dose: How Training Data Drives Unsafe Image Generation
May 27, 2026Text-to-image models trained on large-scale data often inevitably ingest unsafe content. While some people observe input-output amplifications, it remains unclear whether and how training data composition directly drives model output safety or by other factors. We shed light on this question by isolating this variable: we train the same text-to-image model on datasets that differ \emph{only} in their fraction of unsafe images (0\% to 9.6\%), across several dataset scales (100K to 8M). Then we generate images with the resulting models, and evaluate them with four independent safety classifiers. Output unsafety rises monotonically from 16.6\% at 0\% contamination to 25.5\% at 5\%. A factorial design reveals that the \emph{proportion}, not the absolute count, of unsafe training images is the operative variable. The 16.6\% irreducible baseline at zero contamination implicates the other components, e.g. frozen text encoder, as a residual safety risk -- confirmed by a text encoder ablation showing that SafeCLIP reduces this floor to 9.6\%, while the dose-response effect persists across all three encoders tested. Critically, no quality degradation in terms of FID, CLIPscore and ImageReward accompanies safety filtering. These results establish that data curation and text encoder safety are complementary and independently effective interventions. At the same time, the remaining level of unsafety poses questions for future research about emerging capabilities and compositionality.
Multilingual Steering by Design: Multilingual Sparse Autoencoders and Principled Layer Selection
May 21, 2026Sparse autoencoders (SAEs) enable feature-level mechanistic interpretability and activation steering in large language models (LLMs), but SAE-based language control remains unreliable in multilingual settings: most SAEs are trained on English-only data, and steering layers are chosen heuristically. We address these limitations by advancing a principled, mechanistic account of multilingual language steering with SAEs. First, we show that training SAEs on multilingual data consistently strengthens cross-lingual representations and yields more reliable, quality-preserving language control across layers and model families. Second, we introduce an \emph{a priori} steering layer-selection rule based on the intersection of multilingual alignment and language separability, which predicts effective intervention depths without exhaustive layerwise search. We evaluate our approach on LLaMA-3.1-8B and Gemma-2-9B across machine translation and cross-lingual summarization (CrossSumm), using SpBLEU, ROUGE-L, COMET, and LaSE. Our results show that multilingual SAEs combined with intersection-selected layers stabilize the trade-off between language identification accuracy and generation quality, providing a principled, predictive, representation-level account of multilingual SAE steering.
LLMs Gaming Verifiers: RLVR can Lead to Reward Hacking
Apr 16, 2026As reinforcement Learning with Verifiable Rewards (RLVR) has become the dominant paradigm for scaling reasoning capabilities in LLMs, a new failure mode emerges: LLMs gaming verifiers. We study this phenomenon on inductive reasoning tasks, where models must induce and output logical rules. We find that RLVR-trained models systematically abandon rule induction. Instead of learning generalizable patterns (e.g., ``trains carrying red cars go east''), they enumerate instance-level labels, producing outputs that pass verifiers without capturing the relational patterns required by the task. We show that this behavior is not a failure of understanding but a form of reward hacking: imperfect verifiers that check only extensional correctness admit false positives. To detect such shortcuts, we introduce Isomorphic Perturbation Testing (IPT), which evaluates a single model output under both extensional and isomorphic verification, where the latter enforces invariance under logically isomorphic tasks. While genuine rule induction remains invariant, shortcut strategies fail. We find that shortcut behavior is specific to RLVR-trained reasoning models (e.g., GPT-5, Olmo3) and absent in non-RLVR models (e.g., GPT-4o, GPT-4.5, Ministral). Moreover, shortcut prevalence increases with task complexity and inference-time compute. In controlled training experiments, extensional verification directly induces shortcut strategies, while isomorphic verification eliminates them. These results show that RLVR can incentivize reward hacking not only through overt manipulation but also by exploiting what the verifier fails to enforce.
Breaking Up with Normatively Monolithic Agency with GRACE: A Reason-Based Neuro-Symbolic Architecture for Safe and Ethical AI Alignment
Jan 15, 2026As AI agents become increasingly autonomous, widely deployed in consequential contexts, and efficacious in bringing about real-world impacts, ensuring that their decisions are not only instrumentally effective but also normatively aligned has become critical. We introduce a neuro-symbolic reason-based containment architecture, Governor for Reason-Aligned ContainmEnt (GRACE), that decouples normative reasoning from instrumental decision-making and can contain AI agents of virtually any design. GRACE restructures decision-making into three modules: a Moral Module (MM) that determines permissible macro actions via deontic logic-based reasoning; a Decision-Making Module (DMM) that encapsulates the target agent while selecting instrumentally optimal primitive actions in accordance with derived macro actions; and a Guard that monitors and enforces moral compliance. The MM uses a reason-based formalism providing a semantic foundation for deontic logic, enabling interpretability, contestability, and justifiability. Its symbolic representation enriches the DMM's informational context and supports formal verification and statistical guarantees of alignment enforced by the Guard. We demonstrate GRACE on an example of a LLM therapy assistant, showing how it enables stakeholders to understand, contest, and refine agent behavior.
CLaS-Bench: A Cross-Lingual Alignment and Steering Benchmark
Jan 13, 2026Understanding and controlling the behavior of large language models (LLMs) is an increasingly important topic in multilingual NLP. Beyond prompting or fine-tuning, , i.e.,~manipulating internal representations during inference, has emerged as a more efficient and interpretable technique for adapting models to a target language. Yet, no dedicated benchmarks or evaluation protocols exist to quantify the effectiveness of steering techniques. We introduce CLaS-Bench, a lightweight parallel-question benchmark for evaluating language-forcing behavior in LLMs across 32 languages, enabling systematic evaluation of multilingual steering methods. We evaluate a broad array of steering techniques, including residual-stream DiffMean interventions, probe-derived directions, language-specific neurons, PCA/LDA vectors, Sparse Autoencoders, and prompting baselines. Steering performance is measured along two axes: language control and semantic relevance, combined into a single harmonic-mean steering score. We find that across languages simple residual-based DiffMean method consistently outperforms all other methods. Moreover, a layer-wise analysis reveals that language-specific structure emerges predominantly in later layers and steering directions cluster based on language family. CLaS-Bench is the first standardized benchmark for multilingual steering, enabling both rigorous scientific analysis of language representations and practical evaluation of steering as a low-cost adaptation alternative.
LIME: Making LLM Data More Efficient with Linguistic Metadata Embeddings
Dec 08, 2025Pre-training decoder-only language models relies on vast amounts of high-quality data, yet the availability of such data is increasingly reaching its limits. While metadata is commonly used to create and curate these datasets, its potential as a direct training signal remains under-explored. We challenge this status quo and propose LIME (Linguistic Metadata Embeddings), a method that enriches token embeddings with metadata capturing syntax, semantics, and contextual properties. LIME substantially improves pre-training efficiency. Specifically, it adapts up to 56% faster to the training data distribution, while introducing only 0.01% additional parameters at negligible compute overhead. Beyond efficiency, LIME improves tokenization, leading to remarkably stronger language modeling capabilities and generative task performance. These benefits persist across model scales (500M to 2B). In addition, we develop a variant with shifted metadata, LIME+1, that can guide token generation. Given prior metadata for the next token, LIME+1 improves reasoning performance by up to 38% and arithmetic accuracy by up to 35%.
CHRONOBERG: Capturing Language Evolution and Temporal Awareness in Foundation Models
Sep 26, 2025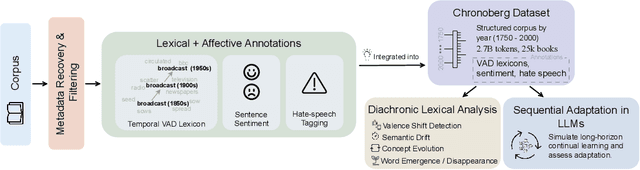



Large language models (LLMs) excel at operating at scale by leveraging social media and various data crawled from the web. Whereas existing corpora are diverse, their frequent lack of long-term temporal structure may however limit an LLM's ability to contextualize semantic and normative evolution of language and to capture diachronic variation. To support analysis and training for the latter, we introduce CHRONOBERG, a temporally structured corpus of English book texts spanning 250 years, curated from Project Gutenberg and enriched with a variety of temporal annotations. First, the edited nature of books enables us to quantify lexical semantic change through time-sensitive Valence-Arousal-Dominance (VAD) analysis and to construct historically calibrated affective lexicons to support temporally grounded interpretation. With the lexicons at hand, we demonstrate a need for modern LLM-based tools to better situate their detection of discriminatory language and contextualization of sentiment across various time-periods. In fact, we show how language models trained sequentially on CHRONOBERG struggle to encode diachronic shifts in meaning, emphasizing the need for temporally aware training and evaluation pipelines, and positioning CHRONOBERG as a scalable resource for the study of linguistic change and temporal generalization. Disclaimer: This paper includes language and display of samples that could be offensive to readers. Open Access: Chronoberg is available publicly on HuggingFace at ( https://huggingface.co/datasets/spaul25/Chronoberg). Code is available at (https://github.com/paulsubarna/Chronoberg).
Measuring and Guiding Monosemanticity
Jun 24, 2025There is growing interest in leveraging mechanistic interpretability and controllability to better understand and influence the internal dynamics of large language models (LLMs). However, current methods face fundamental challenges in reliably localizing and manipulating feature representations. Sparse Autoencoders (SAEs) have recently emerged as a promising direction for feature extraction at scale, yet they, too, are limited by incomplete feature isolation and unreliable monosemanticity. To systematically quantify these limitations, we introduce Feature Monosemanticity Score (FMS), a novel metric to quantify feature monosemanticity in latent representation. Building on these insights, we propose Guided Sparse Autoencoders (G-SAE), a method that conditions latent representations on labeled concepts during training. We demonstrate that reliable localization and disentanglement of target concepts within the latent space improve interpretability, detection of behavior, and control. Specifically, our evaluations on toxicity detection, writing style identification, and privacy attribute recognition show that G-SAE not only enhances monosemanticity but also enables more effective and fine-grained steering with less quality degradation. Our findings provide actionable guidelines for measuring and advancing mechanistic interpretability and control of LLMs.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025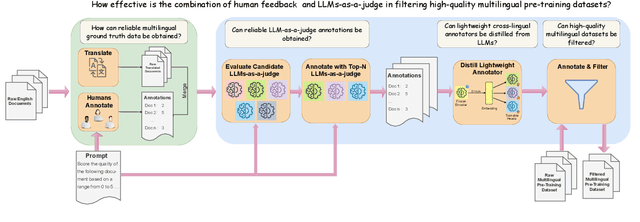
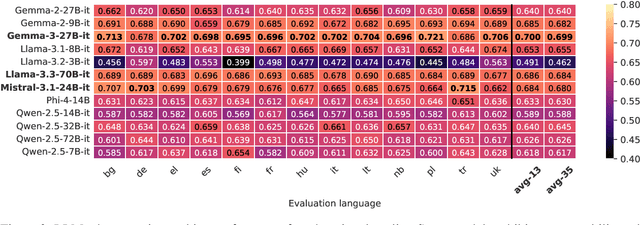

High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.