 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModalities, a PyTorch-native Framework For Large-scale LLM Training and Research
Feb 09, 2026Today's LLM (pre-) training and research workflows typically allocate a significant amount of compute to large-scale ablation studies. Despite the substantial compute costs of these ablations, existing open-source frameworks provide limited tooling for these experiments, often forcing researchers to write their own wrappers and scripts. We propose Modalities, an end-to-end PyTorch-native framework that integrates data-driven LLM research with large-scale model training from two angles. Firstly, by integrating state-of-the-art parallelization strategies, it enables both efficient pretraining and systematic ablations at trillion-token and billion-parameter scale. Secondly, Modalities adopts modular design with declarative, self-contained configuration, enabling reproducibility and extensibility levels that are difficult to achieve out-of-the-box with existing LLM training frameworks.
Output Embedding Centering for Stable LLM Pretraining
Jan 05, 2026Pretraining of large language models is not only expensive but also prone to certain training instabilities. A specific instability that often occurs for large learning rates at the end of training is output logit divergence. The most widely used mitigation strategy, z-loss, merely addresses the symptoms rather than the underlying cause of the problem. In this paper, we analyze the instability from the perspective of the output embeddings' geometry and identify its cause. Based on this, we propose output embedding centering (OEC) as a new mitigation strategy, and prove that it suppresses output logit divergence. OEC can be implemented in two different ways, as a deterministic operation called μ-centering, or a regularization method called μ-loss. Our experiments show that both variants outperform z-loss in terms of training stability and learning rate sensitivity. In particular, they ensure that training converges even for large learning rates when z-loss fails. Furthermore, we find that μ-loss is significantly less sensitive to regularization hyperparameter tuning than z-loss.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025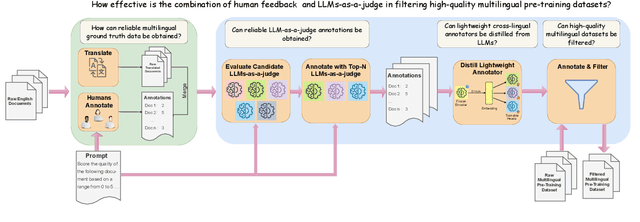
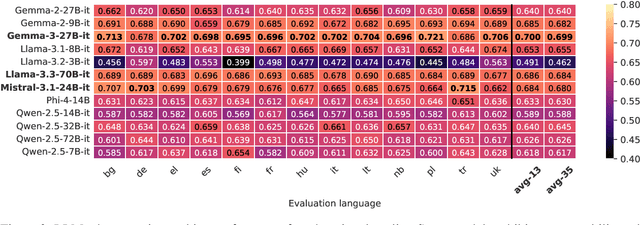

High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
The Mathematical Relationship Between Layer Normalization and Dynamic Activation Functions
Mar 31, 2025A recent paper proposes Dynamic Tanh (DyT) as a drop-in replacement for layer normalization (LN). Although the method is empirically well-motivated and appealing from a practical point of view, it lacks a theoretical foundation. In this work, we shed light on the mathematical relationship between layer normalization and dynamic activation functions. In particular, we derive DyT from LN and show that a well-defined approximation is needed to do so. By dropping said approximation, an alternative activation function is obtained, which we call Dynamic Inverse Square Root Unit (DyISRU). DyISRU is the exact counterpart of layer normalization, and we demonstrate numerically that it indeed resembles LN more accurately than DyT does.
Elementwise Layer Normalization
Mar 27, 2025A recent paper proposed Dynamic Tanh (DyT) as a drop-in replacement for Layer Normalization. Although the method is empirically well-motivated and appealing from a practical point of view, it lacks a theoretical foundation. In this work, we derive DyT mathematically and show that a well-defined approximation is needed to do so. By dropping said approximation, an alternative element-wise transformation is obtained, which we call Elementwise Layer Normalization (ELN). We demonstrate that ELN resembles Layer Normalization more accurately than DyT does.
Better Embeddings with Coupled Adam
Feb 12, 2025Despite their remarkable capabilities, LLMs learn word representations that exhibit the undesirable yet poorly understood feature of anisotropy. In this paper, we argue that the second moment in Adam is a cause of anisotropic embeddings, and suggest a modified optimizer called Coupled Adam to mitigate the problem. Our experiments demonstrate that Coupled Adam significantly improves the quality of embeddings, while also leading to better upstream and downstream performance on large enough datasets.
nerblackbox: A High-level Library for Named Entity Recognition in Python
Dec 07, 2023

We present nerblackbox, a python library to facilitate the use of state-of-the-art transformer-based models for named entity recognition. It provides simple-to-use yet powerful methods to access data and models from a wide range of sources, for fully automated model training and evaluation as well as versatile model inference. While many technical challenges are solved and hidden from the user by default, nerblackbox also offers fine-grained control and a rich set of customizable features. It is thus targeted both at application-oriented developers as well as machine learning experts and researchers.
Text Annotation Handbook: A Practical Guide for Machine Learning Projects
Oct 18, 2023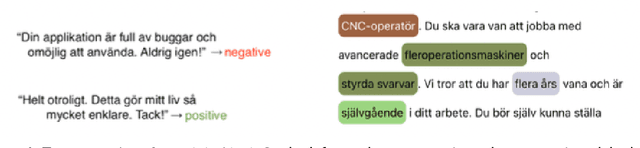

This handbook is a hands-on guide on how to approach text annotation tasks. It provides a gentle introduction to the topic, an overview of theoretical concepts as well as practical advice. The topics covered are mostly technical, but business, ethical and regulatory issues are also touched upon. The focus lies on readability and conciseness rather than completeness and scientific rigor. Experience with annotation and knowledge of machine learning are useful but not required. The document may serve as a primer or reference book for a wide range of professions such as team leaders, project managers, IT architects, software developers and machine learning engineers.
Annotated Job Ads with Named Entity Recognition
Oct 18, 2023
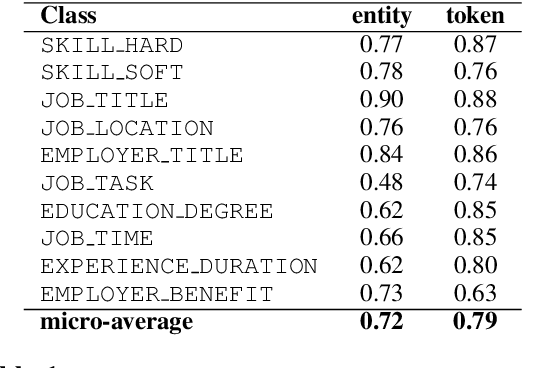
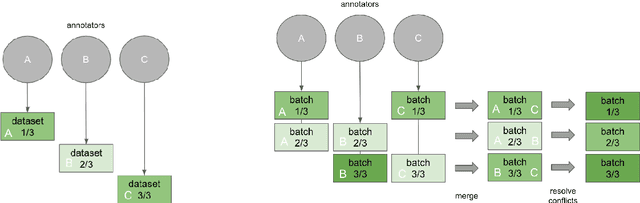

We have trained a named entity recognition (NER) model that screens Swedish job ads for different kinds of useful information (e.g. skills required from a job seeker). It was obtained by fine-tuning KB-BERT. The biggest challenge we faced was the creation of a labelled dataset, which required manual annotation. This paper gives an overview of the methods we employed to make the annotation process more efficient and to ensure high quality data. We also report on the performance of the resulting model.
GPT-SW3: An Autoregressive Language Model for the Nordic Languages
May 23, 2023This paper details the process of developing the first native large generative language model for the Nordic languages, GPT-SW3. We cover all parts of the development process, from data collection and processing, training configuration and instruction finetuning, to evaluation and considerations for release strategies. We hope that this paper can serve as a guide and reference for other researchers that undertake the development of large generative models for smaller languages.