 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWEb: A Large Web Dataset for the Scandinavian Languages
Oct 06, 2024



This paper presents the hitherto largest pretraining dataset for the Scandinavian languages: the Scandinavian WEb (SWEb), comprising over one trillion tokens. The paper details the collection and processing pipeline, and introduces a novel model-based text extractor that significantly reduces complexity in comparison with rule-based approaches. We also introduce a new cloze-style benchmark for evaluating language models in Swedish, and use this test to compare models trained on the SWEb data to models trained on FineWeb, with competitive results. All data, models and code are shared openly.
GPT-SW3: An Autoregressive Language Model for the Nordic Languages
May 23, 2023This paper details the process of developing the first native large generative language model for the Nordic languages, GPT-SW3. We cover all parts of the development process, from data collection and processing, training configuration and instruction finetuning, to evaluation and considerations for release strategies. We hope that this paper can serve as a guide and reference for other researchers that undertake the development of large generative models for smaller languages.
The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
Mar 30, 2023Pre-training Large Language Models (LLMs) require massive amounts of text data, and the performance of the LLMs typically correlates with the scale and quality of the datasets. This means that it may be challenging to build LLMs for smaller languages such as Nordic ones, where the availability of text corpora is limited. In order to facilitate the development of the LLMS in the Nordic languages, we curate a high-quality dataset consisting of 1.2TB of text, in all of the major North Germanic languages (Danish, Icelandic, Norwegian, and Swedish), as well as some high-quality English data. This paper details our considerations and processes for collecting, cleaning, and filtering the dataset.
A comprehensive comparative evaluation and analysis of Distributional Semantic Models
May 20, 2021
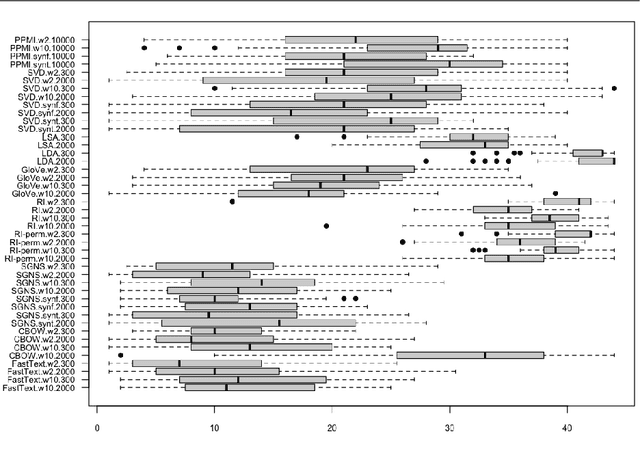

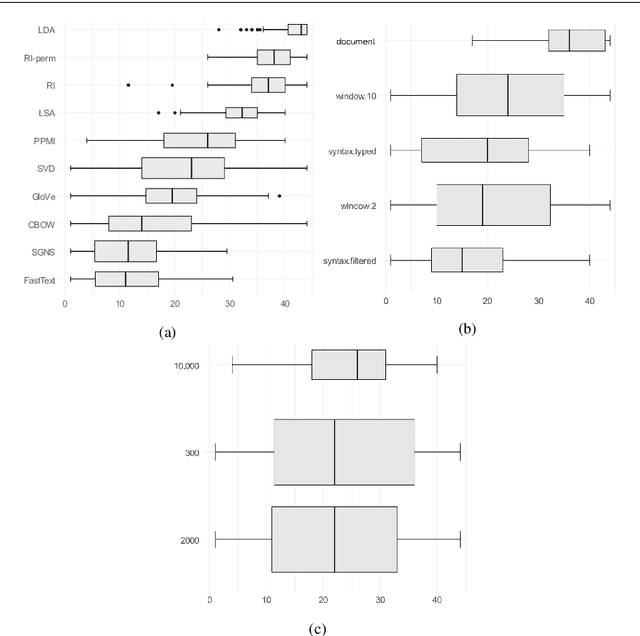
Distributional semantics has deeply changed in the last decades. First, predict models stole the thunder from traditional count ones, and more recently both of them were replaced in many NLP applications by contextualized vectors produced by Transformer neural language models. Although an extensive body of research has been devoted to Distributional Semantic Model (DSM) evaluation, we still lack a thorough comparison with respect to tested models, semantic tasks, and benchmark datasets. Moreover, previous work has mostly focused on task-driven evaluation, instead of exploring the differences between the way models represent the lexical semantic space. In this paper, we perform a comprehensive evaluation of type distributional vectors, either produced by static DSMs or obtained by averaging the contextualized vectors generated by BERT. First of all, we investigate the performance of embeddings in several semantic tasks, carrying out an in-depth statistical analysis to identify the major factors influencing the behavior of DSMs. The results show that i.) the alleged superiority of predict based models is more apparent than real, and surely not ubiquitous and ii.) static DSMs surpass contextualized representations in most out-of-context semantic tasks and datasets. Furthermore, we borrow from cognitive neuroscience the methodology of Representational Similarity Analysis (RSA) to inspect the semantic spaces generated by distributional models. RSA reveals important differences related to the frequency and part-of-speech of lexical items.
Measuring Issue Ownership using Word Embeddings
Oct 31, 2018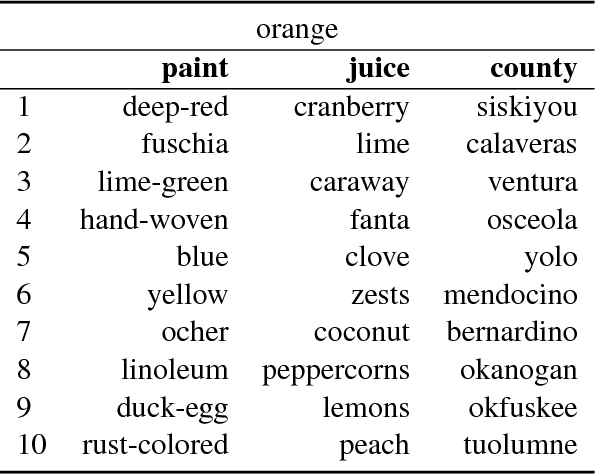
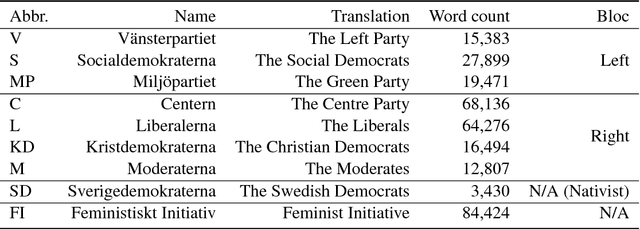
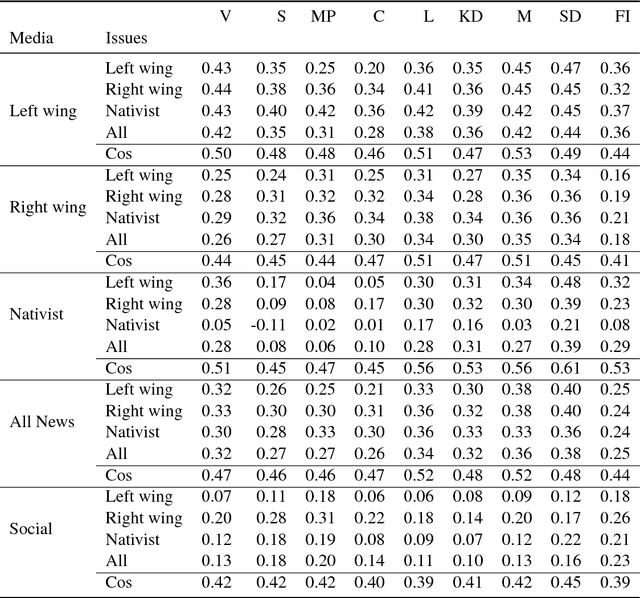
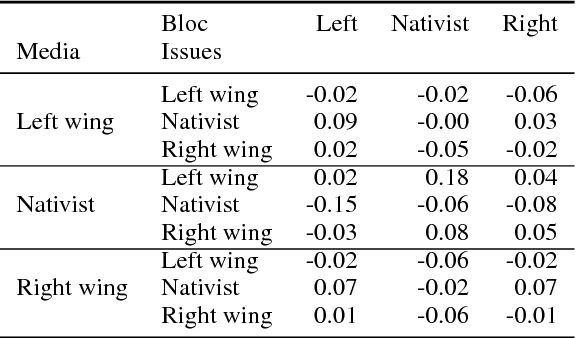
Sentiment and topic analysis are common methods used for social media monitoring. Essentially, these methods answers questions such as, "what is being talked about, regarding X", and "what do people feel, regarding X". In this paper, we investigate another venue for social media monitoring, namely issue ownership and agenda setting, which are concepts from political science that have been used to explain voter choice and electoral outcomes. We argue that issue alignment and agenda setting can be seen as a kind of semantic source similarity of the kind "how similar is source A to issue owner P, when talking about issue X", and as such can be measured using word/document embedding techniques. We present work in progress towards measuring that kind of conditioned similarity, and introduce a new notion of similarity for predictive embeddings. We then test this method by measuring the similarity between politically aligned media and political parties, conditioned on bloc-specific issues.
R-grams: Unsupervised Learning of Semantic Units in Natural Language
Aug 14, 2018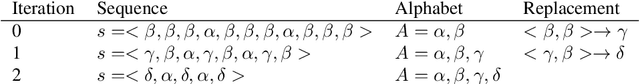
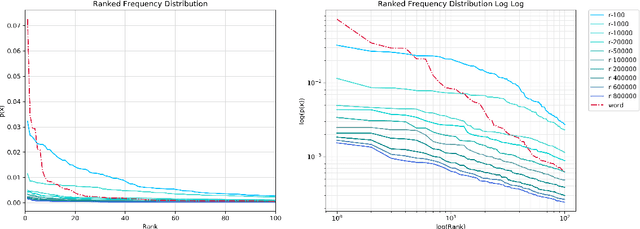

This paper introduces a novel type of data-driven segmented unit that we call r-grams. We illustrate one algorithm for calculating r-grams, and discuss its properties and impact on the frequency distribution of text representations. The proposed approach is evaluated by demonstrating its viability in embedding techniques, both in monolingual and multilingual test settings. We also provide a number of qualitative examples of the proposed methodology, demonstrating its viability as a language-invariant segmentation procedure.
Distributional Term Set Expansion
Feb 14, 2018
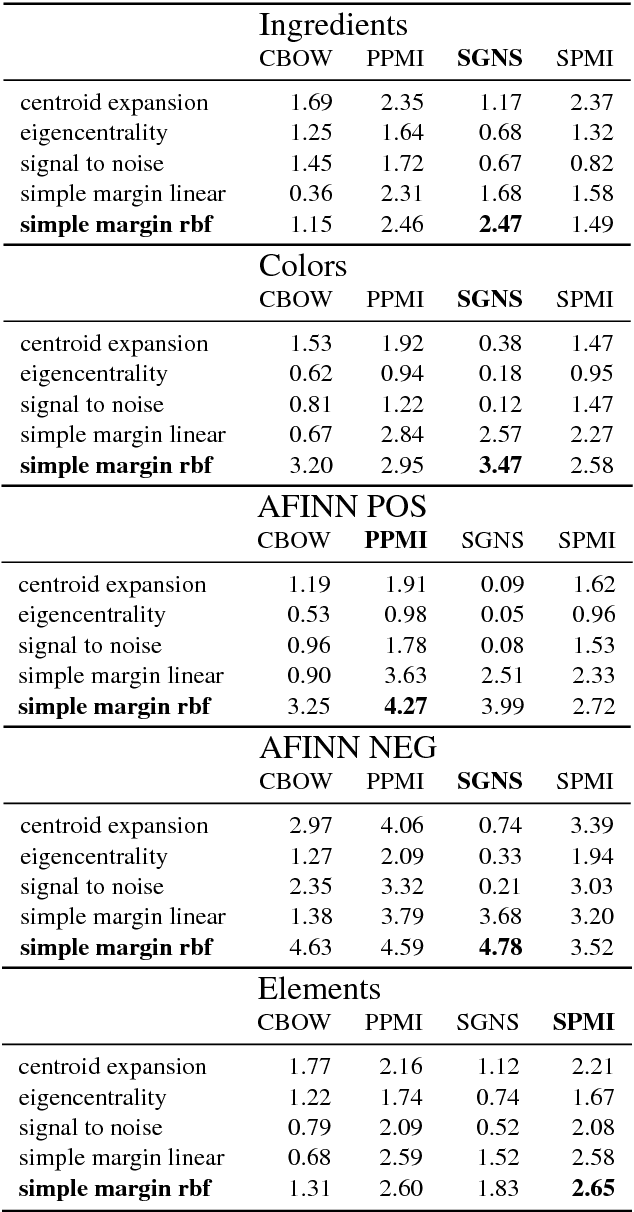

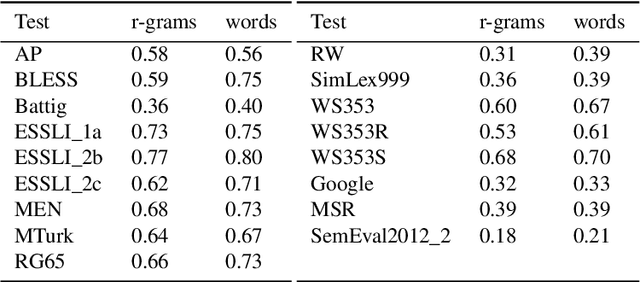
This paper is a short empirical study of the performance of centrality and classification based iterative term set expansion methods for distributional semantic models. Iterative term set expansion is an interactive process using distributional semantics models where a user labels terms as belonging to some sought after term set, and a system uses this labeling to supply the user with new, candidate, terms to label, trying to maximize the number of positive examples found. While centrality based methods have a long history in term set expansion, we compare them to classification methods based on the the Simple Margin method, an Active Learning approach to classification using Support Vector Machines. Examining the performance of various centrality and classification based methods for a variety of distributional models over five different term sets, we can show that active learning based methods consistently outperform centrality based methods.
Navigating the Semantic Horizon using Relative Neighborhood Graphs
Jan 12, 2015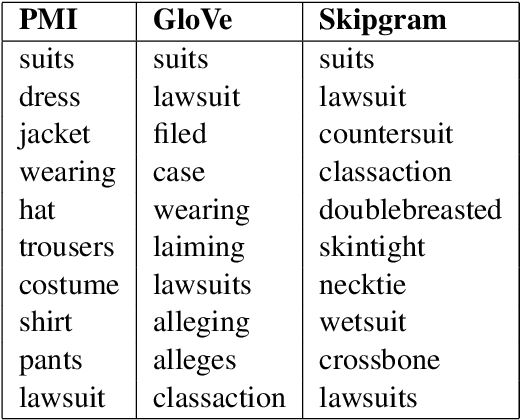

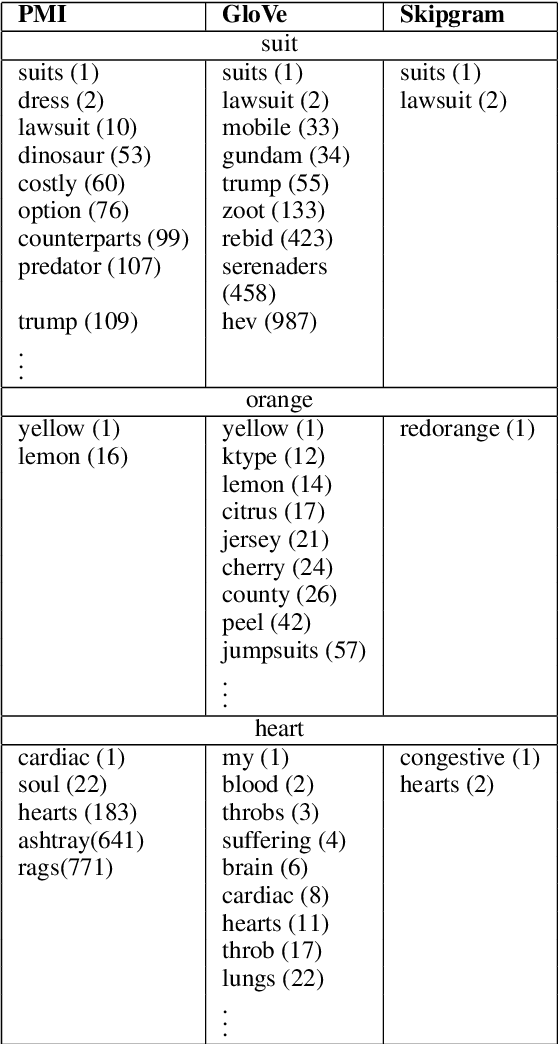

This paper is concerned with nearest neighbor search in distributional semantic models. A normal nearest neighbor search only returns a ranked list of neighbors, with no information about the structure or topology of the local neighborhood. This is a potentially serious shortcoming of the mode of querying a distributional semantic model, since a ranked list of neighbors may conflate several different senses. We argue that the topology of neighborhoods in semantic space provides important information about the different senses of terms, and that such topological structures can be used for word-sense induction. We also argue that the topology of the neighborhoods in semantic space can be used to determine the semantic horizon of a point, which we define as the set of neighbors that have a direct connection to the point. We introduce relative neighborhood graphs as method to uncover the topological properties of neighborhoods in semantic models. We also provide examples of relative neighborhood graphs for three well-known semantic models; the PMI model, the GloVe model, and the skipgram model.