 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpliCa: Evaluating Explicit Causal Reasoning in Large Language Models
Feb 21, 2025Large Language Models (LLMs) are increasingly used in tasks requiring interpretive and inferential accuracy. In this paper, we introduce ExpliCa, a new dataset for evaluating LLMs in explicit causal reasoning. ExpliCa uniquely integrates both causal and temporal relations presented in different linguistic orders and explicitly expressed by linguistic connectives. The dataset is enriched with crowdsourced human acceptability ratings. We tested LLMs on ExpliCa through prompting and perplexity-based metrics. We assessed seven commercial and open-source LLMs, revealing that even top models struggle to reach 0.80 accuracy. Interestingly, models tend to confound temporal relations with causal ones, and their performance is also strongly influenced by the linguistic order of the events. Finally, perplexity-based scores and prompting performance are differently affected by model size.
Prompting Encoder Models for Zero-Shot Classification: A Cross-Domain Study in Italian
Jul 30, 2024



Addressing the challenge of limited annotated data in specialized fields and low-resource languages is crucial for the effective use of Language Models (LMs). While most Large Language Models (LLMs) are trained on general-purpose English corpora, there is a notable gap in models specifically tailored for Italian, particularly for technical and bureaucratic jargon. This paper explores the feasibility of employing smaller, domain-specific encoder LMs alongside prompting techniques to enhance performance in these specialized contexts. Our study concentrates on the Italian bureaucratic and legal language, experimenting with both general-purpose and further pre-trained encoder-only models. We evaluated the models on downstream tasks such as document classification and entity typing and conducted intrinsic evaluations using Pseudo-Log-Likelihood. The results indicate that while further pre-trained models may show diminished robustness in general knowledge, they exhibit superior adaptability for domain-specific tasks, even in a zero-shot setting. Furthermore, the application of calibration techniques and in-domain verbalizers significantly enhances the efficacy of encoder models. These domain-specialized models prove to be particularly advantageous in scenarios where in-domain resources or expertise are scarce. In conclusion, our findings offer new insights into the use of Italian models in specialized contexts, which may have a significant impact on both research and industrial applications in the digital transformation era.
A comprehensive comparative evaluation and analysis of Distributional Semantic Models
May 20, 2021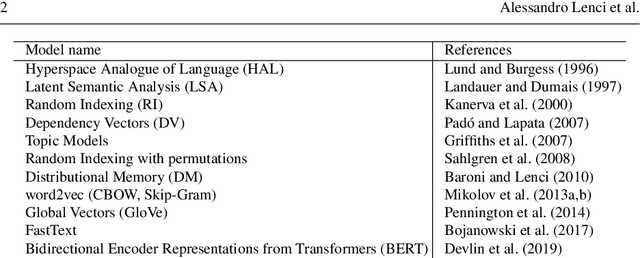
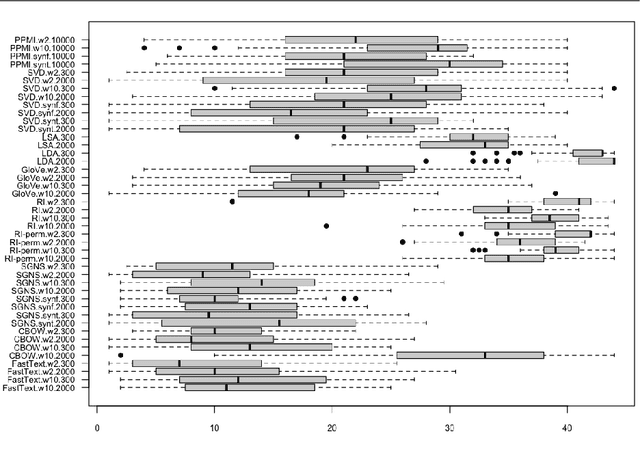

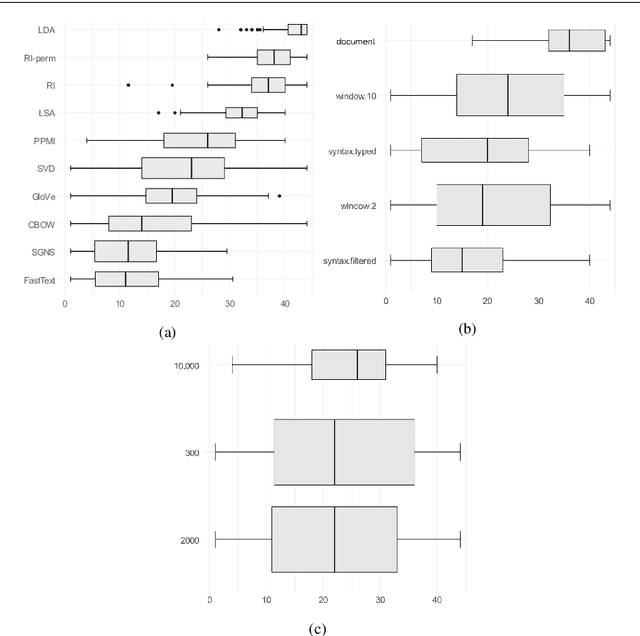
Distributional semantics has deeply changed in the last decades. First, predict models stole the thunder from traditional count ones, and more recently both of them were replaced in many NLP applications by contextualized vectors produced by Transformer neural language models. Although an extensive body of research has been devoted to Distributional Semantic Model (DSM) evaluation, we still lack a thorough comparison with respect to tested models, semantic tasks, and benchmark datasets. Moreover, previous work has mostly focused on task-driven evaluation, instead of exploring the differences between the way models represent the lexical semantic space. In this paper, we perform a comprehensive evaluation of type distributional vectors, either produced by static DSMs or obtained by averaging the contextualized vectors generated by BERT. First of all, we investigate the performance of embeddings in several semantic tasks, carrying out an in-depth statistical analysis to identify the major factors influencing the behavior of DSMs. The results show that i.) the alleged superiority of predict based models is more apparent than real, and surely not ubiquitous and ii.) static DSMs surpass contextualized representations in most out-of-context semantic tasks and datasets. Furthermore, we borrow from cognitive neuroscience the methodology of Representational Similarity Analysis (RSA) to inspect the semantic spaces generated by distributional models. RSA reveals important differences related to the frequency and part-of-speech of lexical items.