 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Capture Embodied Cognition and Cultural Variation? Cross-Linguistic Evidence from Demonstratives
Apr 28, 2026Do large language models (LLMs) truly acquire embodied cognition and cultural conventions from text? We introduce demonstratives, fundamental spatial expressions like "this/that" in English and "zhè/nà" in Chinese, as a novel probe for grounded knowledge. Using 6,400 responses from 320 native speakers, we establish a human baseline: English speakers reliably distinguish proximal-distal referents but struggle with perspective-taking, while Chinese speakers switch perspectives fluently but tolerate distal ambiguity. In contrast, five state-of-the-art LLMs fail to inherently understand the proximal-distal contrast and show no cultural differences, defaulting to English-centric reasoning. Our study contributes (i) a new task, based on demonstratives, as a new lens for evaluating embodied cognition and cultural conventions; (ii) empirical evidence of cross-cultural asymmetries in human interpretation; (iii) a new perspective on the egocentric-sociocentric debate, showing both orientations coexist but vary across languages; and (iv) a call to address individual variation in future model design.
Good Arguments Against the People Pleasers: How Reasoning Mitigates (Yet Masks) LLM Sycophancy
Mar 17, 2026Alignment techniques often inadvertently induce sycophancy in LLMs. While prior studies studied this behaviour in direct-answer settings, the role of Chain-of-Thought (CoT) reasoning remains under-explored: does it serve as a logical constraint that mitigates sycophancy, or a tool for post-hoc rationalization that masks it? We evaluate a range of models across objective and subjective tasks to investigate the issue. Results show that reasoning generally reduces sycophancy in final decisions but also masks sycophancy in some samples, where models construct deceptive justifications through logical inconsistencies, calculation errors, and one-sided arguments etc. Furthermore, LLMs are more prone to sycophancy in subjective tasks and under authority-bias. Our mechanistic analysis on three open-source models reveals that the tendency of sycophancy is dynamic during the reasoning process rather than being pre-determined at the input stage.
Is Length Really A Liability? An Evaluation of Multi-turn LLM Conversations using BoolQ
Jan 23, 2026Single-prompt evaluations dominate current LLM benchmarking, yet they fail to capture the conversational dynamics where real-world harm occurs. In this study, we examined whether conversation length affects response veracity by evaluating LLM performance on the BoolQ dataset under varying length and scaffolding conditions. Our results across three distinct LLMs revealed model-specific vulnerabilities that are invisible under single-turn testing. The length-dependent and scaffold-specific effects we observed demonstrate a fundamental limitation of static evaluations, as deployment-relevant vulnerabilities could only be spotted in a multi-turn conversational setting.
Can Large Language Models Understand, Reason About, and Generate Code-Switched Text?
Jan 12, 2026Code-switching is a pervasive phenomenon in multilingual communication, yet the robustness of large language models (LLMs) in mixed-language settings remains insufficiently understood. In this work, we present a comprehensive evaluation of LLM capabilities in understanding, reasoning over, and generating code-switched text. We introduce CodeMixQA a novel benchmark with high-quality human annotations, comprising 16 diverse parallel code-switched language-pair variants that span multiple geographic regions and code-switching patterns, and include both original scripts and their transliterated forms. Using this benchmark, we analyze the reasoning behavior of LLMs on code-switched question-answering tasks, shedding light on how models process and reason over mixed-language inputs. We further conduct a systematic evaluation of LLM-generated synthetic code-switched text, focusing on both naturalness and semantic fidelity, and uncover key limitations in current generation capabilities. Our findings reveal persistent challenges in both reasoning and generation under code-switching conditions and provide actionable insights for building more robust multilingual LLMs. We release the dataset and code as open source.
Learning to Look at the Other Side: A Semantic Probing Study of Word Embeddings in LLMs with Enabled Bidirectional Attention
Oct 02, 2025Autoregressive Large Language Models (LLMs) demonstrate exceptional performance in language understanding and generation. However, their application in text embedding tasks has been relatively slow, along with the analysis of their semantic representation in probing tasks, due to the constraints of the unidirectional attention mechanism. This paper aims to explore whether such constraints can be overcome by enabling bidirectional attention in LLMs. We tested different variants of the Llama architecture through additional training steps, progressively enabling bidirectional attention and unsupervised/supervised contrastive learning.
From BERT to LLMs: Comparing and Understanding Chinese Classifier Prediction in Language Models
Aug 25, 2025Classifiers are an important and defining feature of the Chinese language, and their correct prediction is key to numerous educational applications. Yet, whether the most popular Large Language Models (LLMs) possess proper knowledge the Chinese classifiers is an issue that has largely remain unexplored in the Natural Language Processing (NLP) literature. To address such a question, we employ various masking strategies to evaluate the LLMs' intrinsic ability, the contribution of different sentence elements, and the working of the attention mechanisms during prediction. Besides, we explore fine-tuning for LLMs to enhance the classifier performance. Our findings reveal that LLMs perform worse than BERT, even with fine-tuning. The prediction, as expected, greatly benefits from the information about the following noun, which also explains the advantage of models with a bidirectional attention mechanism such as BERT.
Sparse Brains are Also Adaptive Brains: Cognitive-Load-Aware Dynamic Activation for LLMs
Feb 26, 2025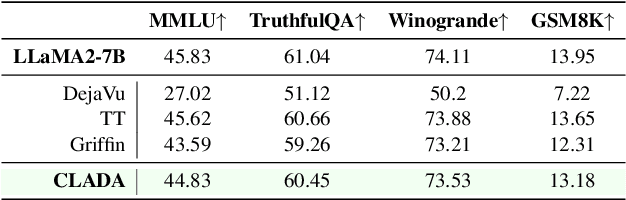
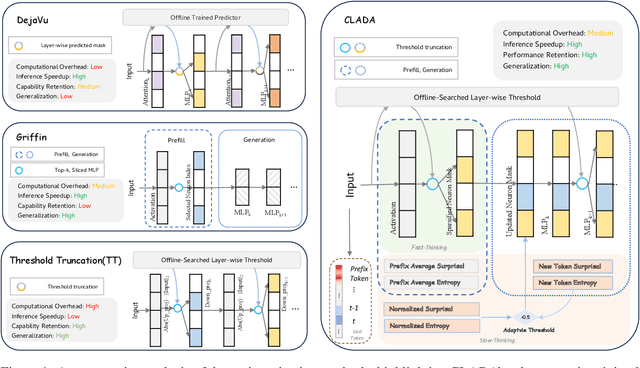
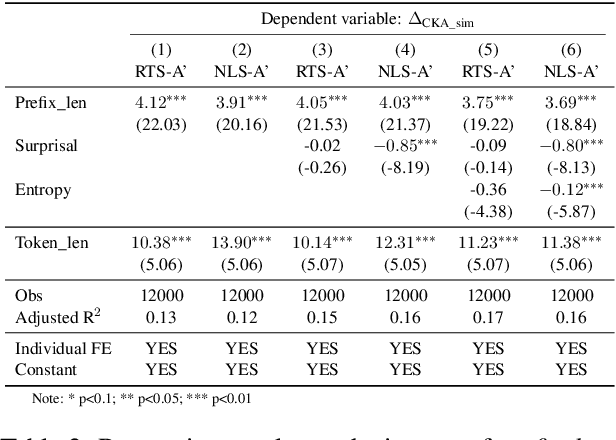
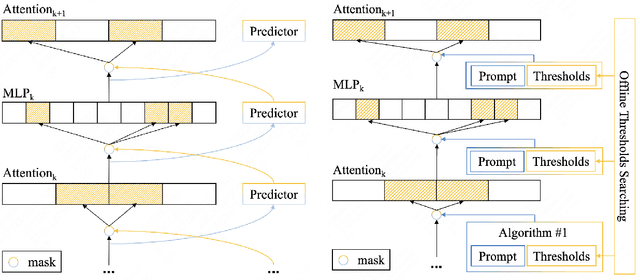
Dense large language models(LLMs) face critical efficiency bottlenecks as they rigidly activate all parameters regardless of input complexity. While existing sparsity methods(static pruning or dynamic activation) address this partially, they either lack adaptivity to contextual or model structural demands or incur prohibitive computational overhead. Inspired by human brain's dual-process mechanisms - predictive coding (N400) for backbone sparsity and structural reanalysis (P600) for complex context - we propose CLADA, a \textit{\textbf{C}ognitive-\textbf{L}oad-\textbf{A}ware \textbf{D}ynamic \textbf{A}ctivation} framework that synergizes statistical sparsity with semantic adaptability. Our key insight is that LLM activations exhibit two complementary patterns: 1) \textit{Global statistical sparsity} driven by sequence-level prefix information, and 2) \textit{Local semantic adaptability} modulated by cognitive load metrics(e.g., surprisal and entropy). CLADA employs a hierarchical thresholding strategy: a baseline from offline error-controlled optimization ensures 40\%+ sparsity, dynamically adjusted by real-time cognitive signals. Evaluations across six mainstream LLMs and nine benchmarks demonstrate that CLADA achieves \textbf{~20\% average speedup with <2\% accuracy drop}, outperforming Griffin (5\%+ degradation) and TT (negligible speedup). Crucially, we establish the first formal connection between neurolinguistic event-related potential (ERP) components and LLM efficiency mechanisms through multi-level regression analysis ($R^2=0.17$ for sparsity-adaptation synergy). Requiring no retraining or architectural changes, CLADA offers a deployable solution for resource-aware LLM inference while advancing biologically-inspired AI design. Our code is available at \href{https://github.com/Oldify/CLADA}{CLADA}.
ExpliCa: Evaluating Explicit Causal Reasoning in Large Language Models
Feb 21, 2025Large Language Models (LLMs) are increasingly used in tasks requiring interpretive and inferential accuracy. In this paper, we introduce ExpliCa, a new dataset for evaluating LLMs in explicit causal reasoning. ExpliCa uniquely integrates both causal and temporal relations presented in different linguistic orders and explicitly expressed by linguistic connectives. The dataset is enriched with crowdsourced human acceptability ratings. We tested LLMs on ExpliCa through prompting and perplexity-based metrics. We assessed seven commercial and open-source LLMs, revealing that even top models struggle to reach 0.80 accuracy. Interestingly, models tend to confound temporal relations with causal ones, and their performance is also strongly influenced by the linguistic order of the events. Finally, perplexity-based scores and prompting performance are differently affected by model size.
Composing or Not Composing? Towards Distributional Construction Grammars
Dec 10, 2024The mechanisms of comprehension during language processing remains an open question. Classically, building the meaning of a linguistic utterance is said to be incremental, step-by-step, based on a compositional process. However, many different works have shown for a long time that non-compositional phenomena are also at work. It is therefore necessary to propose a framework bringing together both approaches. We present in this paper an approach based on Construction Grammars and completing this framework in order to account for these different mechanisms. We propose first a formal definition of this framework by completing the feature structure representation proposed in Sign-Based Construction Grammars. In a second step, we present a general representation of the meaning based on the interaction of constructions, frames and events. This framework opens the door to a processing mechanism for building the meaning based on the notion of activation evaluated in terms of similarity and unification. This new approach integrates features from distributional semantics into the constructionist framework, leading to what we call Distributional Construction Grammars.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.