 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Brains are Also Adaptive Brains: Cognitive-Load-Aware Dynamic Activation for LLMs
Feb 26, 2025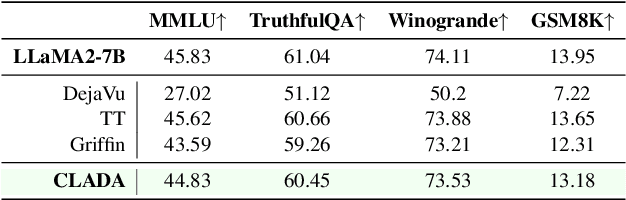
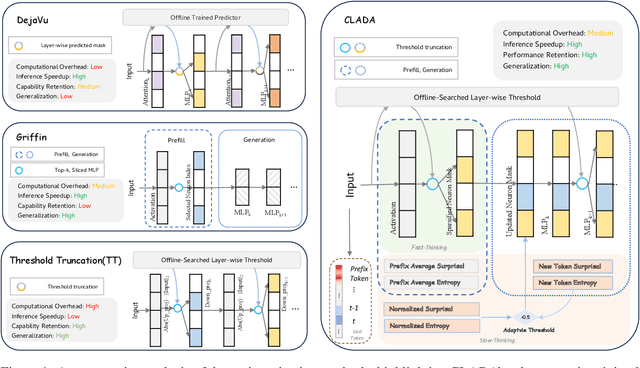
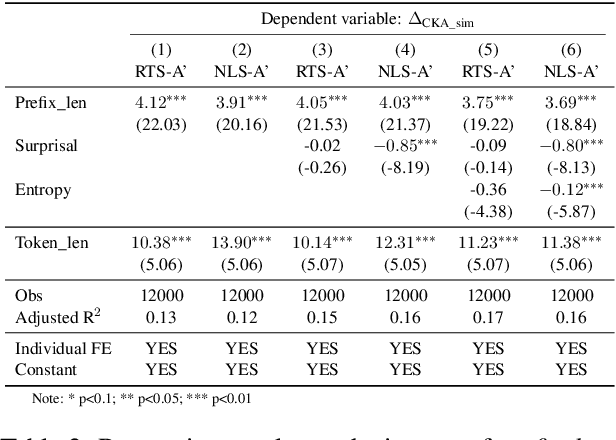
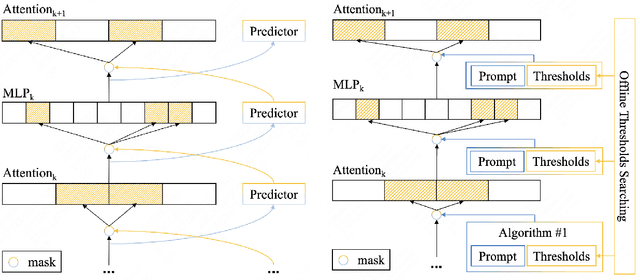
Dense large language models(LLMs) face critical efficiency bottlenecks as they rigidly activate all parameters regardless of input complexity. While existing sparsity methods(static pruning or dynamic activation) address this partially, they either lack adaptivity to contextual or model structural demands or incur prohibitive computational overhead. Inspired by human brain's dual-process mechanisms - predictive coding (N400) for backbone sparsity and structural reanalysis (P600) for complex context - we propose CLADA, a \textit{\textbf{C}ognitive-\textbf{L}oad-\textbf{A}ware \textbf{D}ynamic \textbf{A}ctivation} framework that synergizes statistical sparsity with semantic adaptability. Our key insight is that LLM activations exhibit two complementary patterns: 1) \textit{Global statistical sparsity} driven by sequence-level prefix information, and 2) \textit{Local semantic adaptability} modulated by cognitive load metrics(e.g., surprisal and entropy). CLADA employs a hierarchical thresholding strategy: a baseline from offline error-controlled optimization ensures 40\%+ sparsity, dynamically adjusted by real-time cognitive signals. Evaluations across six mainstream LLMs and nine benchmarks demonstrate that CLADA achieves \textbf{~20\% average speedup with <2\% accuracy drop}, outperforming Griffin (5\%+ degradation) and TT (negligible speedup). Crucially, we establish the first formal connection between neurolinguistic event-related potential (ERP) components and LLM efficiency mechanisms through multi-level regression analysis ($R^2=0.17$ for sparsity-adaptation synergy). Requiring no retraining or architectural changes, CLADA offers a deployable solution for resource-aware LLM inference while advancing biologically-inspired AI design. Our code is available at \href{https://github.com/Oldify/CLADA}{CLADA}.
RGD: Multi-LLM Based Agent Debugger via Refinement and Generation Guidance
Oct 02, 2024



Large Language Models (LLMs) have shown incredible potential in code generation tasks, and recent research in prompt engineering have enhanced LLMs' understanding of textual information. However, ensuring the accuracy of generated code often requires extensive testing and validation by programmers. While LLMs can typically generate code based on task descriptions, their accuracy remains limited, especially for complex tasks that require a deeper understanding of both the problem statement and the code generation process. This limitation is primarily due to the LLMs' need to simultaneously comprehend text and generate syntactically and semantically correct code, without having the capability to automatically refine the code. In real-world software development, programmers rarely produce flawless code in a single attempt based on the task description alone, they rely on iterative feedback and debugging to refine their programs. Inspired by this process, we introduce a novel architecture of LLM-based agents for code generation and automatic debugging: Refinement and Guidance Debugging (RGD). The RGD framework is a multi-LLM-based agent debugger that leverages three distinct LLM agents-Guide Agent, Debug Agent, and Feedback Agent. RGD decomposes the code generation task into multiple steps, ensuring a clearer workflow and enabling iterative code refinement based on self-reflection and feedback. Experimental results demonstrate that RGD exhibits remarkable code generation capabilities, achieving state-of-the-art performance with a 9.8% improvement on the HumanEval dataset and a 16.2% improvement on the MBPP dataset compared to the state-of-the-art approaches and traditional direct prompting approaches. We highlight the effectiveness of the RGD framework in enhancing LLMs' ability to generate and refine code autonomously.
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022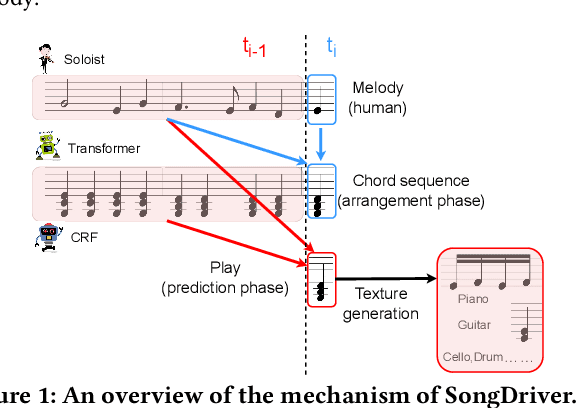
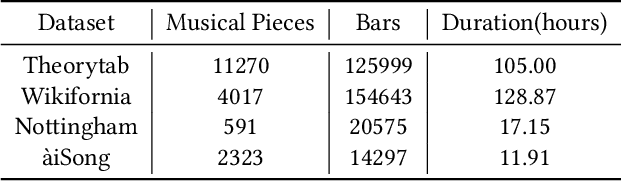
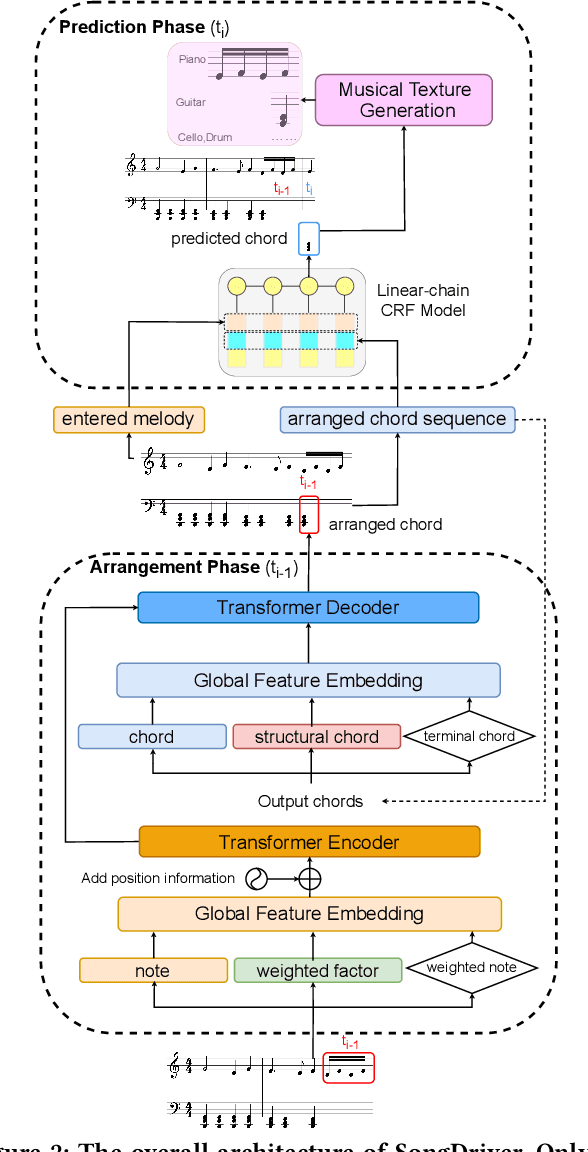

Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.