 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAD: Self-Evolving Agent for Multi-Turn Service Dialogue
Feb 03, 2026Large Language Models have demonstrated remarkable capabilities in open-domain dialogues. However, current methods exhibit suboptimal performance in service dialogues, as they rely on noisy, low-quality human conversation data. This limitation arises from data scarcity and the difficulty of simulating authentic, goal-oriented user behaviors. To address these issues, we propose SEAD (Self-Evolving Agent for Service Dialogue), a framework that enables agents to learn effective strategies without large-scale human annotations. SEAD decouples user modeling into two components: a Profile Controller that generates diverse user states to manage training curriculum, and a User Role-play Model that focuses on realistic role-playing. This design ensures the environment provides adaptive training scenarios rather than acting as an unfair adversary. Experiments demonstrate that SEAD significantly outperforms Open-source Foundation Models and Closed-source Commercial Models, improving task completion rate by 17.6% and dialogue efficiency by 11.1%. Code is available at: https://github.com/Da1yuqin/SEAD.
Urban Socio-Semantic Segmentation with Vision-Language Reasoning
Jan 15, 2026As hubs of human activity, urban surfaces consist of a wealth of semantic entities. Segmenting these various entities from satellite imagery is crucial for a range of downstream applications. Current advanced segmentation models can reliably segment entities defined by physical attributes (e.g., buildings, water bodies) but still struggle with socially defined categories (e.g., schools, parks). In this work, we achieve socio-semantic segmentation by vision-language model reasoning. To facilitate this, we introduce the Urban Socio-Semantic Segmentation dataset named SocioSeg, a new resource comprising satellite imagery, digital maps, and pixel-level labels of social semantic entities organized in a hierarchical structure. Additionally, we propose a novel vision-language reasoning framework called SocioReasoner that simulates the human process of identifying and annotating social semantic entities via cross-modal recognition and multi-stage reasoning. We employ reinforcement learning to optimize this non-differentiable process and elicit the reasoning capabilities of the vision-language model. Experiments demonstrate our approach's gains over state-of-the-art models and strong zero-shot generalization. Our dataset and code are available in https://github.com/AMAP-ML/SocioReasoner.
APD-Agents: A Large Language Model-Driven Multi-Agents Collaborative Framework for Automated Page Design
Nov 18, 2025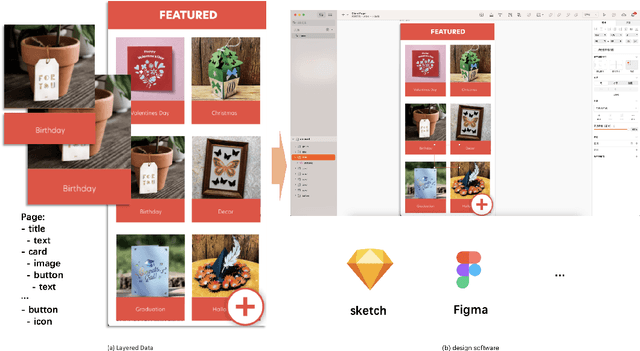
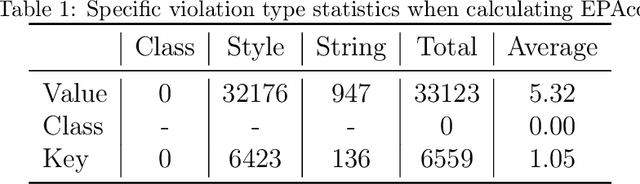
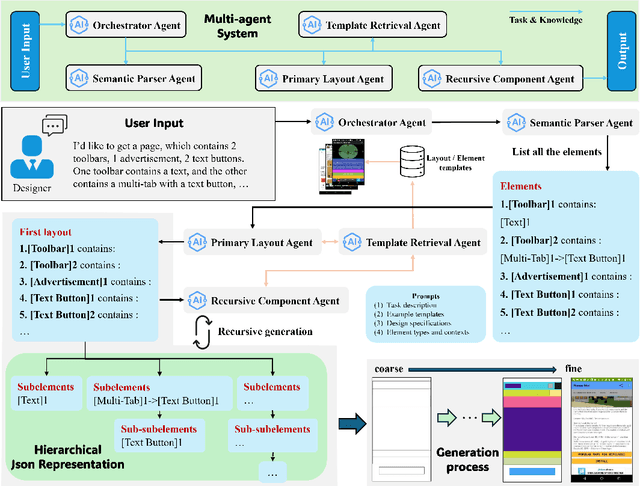
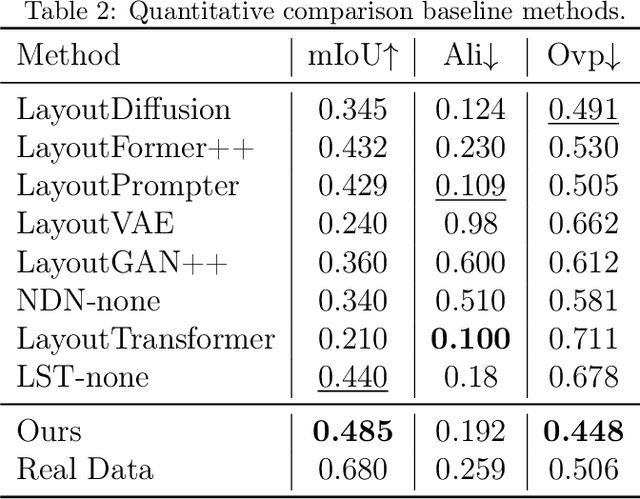
Layout design is a crucial step in developing mobile app pages. However, crafting satisfactory designs is time-intensive for designers: they need to consider which controls and content to present on the page, and then repeatedly adjust their size, position, and style for better aesthetics and structure. Although many design software can now help to perform these repetitive tasks, extensive training is needed to use them effectively. Moreover, collaborative design across app pages demands extra time to align standards and ensure consistent styling. In this work, we propose APD-agents, a large language model (LLM) driven multi-agent framework for automated page design in mobile applications. Our framework contains OrchestratorAgent, SemanticParserAgent, PrimaryLayoutAgent, TemplateRetrievalAgent, and RecursiveComponentAgent. Upon receiving the user's description of the page, the OrchestratorAgent can dynamically can direct other agents to accomplish users' design task. To be specific, the SemanticParserAgent is responsible for converting users' descriptions of page content into structured data. The PrimaryLayoutAgent can generate an initial coarse-grained layout of this page. The TemplateRetrievalAgent can fetch semantically relevant few-shot examples and enhance the quality of layout generation. Besides, a RecursiveComponentAgent can be used to decide how to recursively generate all the fine-grained sub-elements it contains for each element in the layout. Our work fully leverages the automatic collaboration capabilities of large-model-driven multi-agent systems. Experimental results on the RICO dataset show that our APD-agents achieve state-of-the-art performance.
Evaluating Cognitive-Behavioral Fixation via Multimodal User Viewing Patterns on Social Media
Sep 05, 2025Digital social media platforms frequently contribute to cognitive-behavioral fixation, a phenomenon in which users exhibit sustained and repetitive engagement with narrow content domains. While cognitive-behavioral fixation has been extensively studied in psychology, methods for computationally detecting and evaluating such fixation remain underexplored. To address this gap, we propose a novel framework for assessing cognitive-behavioral fixation by analyzing users' multimodal social media engagement patterns. Specifically, we introduce a multimodal topic extraction module and a cognitive-behavioral fixation quantification module that collaboratively enable adaptive, hierarchical, and interpretable assessment of user behavior. Experiments on existing benchmarks and a newly curated multimodal dataset demonstrate the effectiveness of our approach, laying the groundwork for scalable computational analysis of cognitive fixation. All code in this project is publicly available for research purposes at https://github.com/Liskie/cognitive-fixation-evaluation.
Galvatron: An Automatic Distributed System for Efficient Foundation Model Training
Apr 30, 2025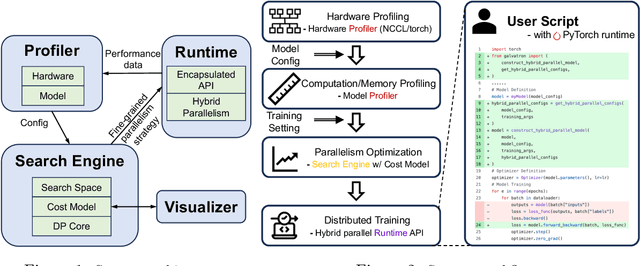
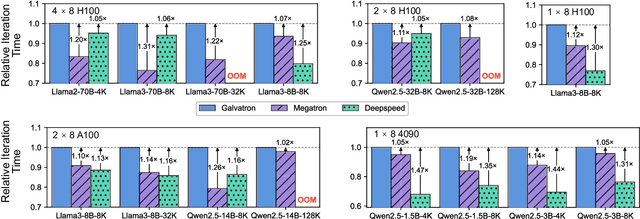
Galvatron is a distributed system for efficiently training large-scale Foundation Models. It overcomes the complexities of selecting optimal parallelism strategies by automatically identifying the most efficient hybrid strategy, incorporating data, tensor, pipeline, sharded data, and sequence parallelism, along with recomputation. The system's architecture includes a profiler for hardware and model analysis, a search engine for strategy optimization using decision trees and dynamic programming, and a runtime for executing these strategies efficiently. Benchmarking on various clusters demonstrates Galvatron's superior throughput compared to existing frameworks. This open-source system offers user-friendly interfaces and comprehensive documentation, making complex distributed training accessible and efficient. The source code of Galvatron is available at https://github.com/PKU-DAIR/Hetu-Galvatron.
IsoSEL: Isometric Structural Entropy Learning for Deep Graph Clustering in Hyperbolic Space
Apr 14, 2025Graph clustering is a longstanding topic in machine learning. In recent years, deep learning methods have achieved encouraging results, but they still require predefined cluster numbers K, and typically struggle with imbalanced graphs, especially in identifying minority clusters. The limitations motivate us to study a challenging yet practical problem: deep graph clustering without K considering the imbalance in reality. We approach this problem from a fresh perspective of information theory (i.e., structural information). In the literature, structural information has rarely been touched in deep clustering, and the classic definition falls short in its discrete formulation, neglecting node attributes and exhibiting prohibitive complexity. In this paper, we first establish a new Differentiable Structural Information, generalizing the discrete formalism to continuous realm, so that the optimal partitioning tree, revealing the cluster structure, can be created by the gradient backpropagation. Theoretically, we demonstrate its capability in clustering without requiring K and identifying the minority clusters in imbalanced graphs, while reducing the time complexity to O(N) w.r.t. the number of nodes. Subsequently, we present a novel IsoSEL framework for deep graph clustering, where we design a hyperbolic neural network to learn the partitioning tree in the Lorentz model of hyperbolic space, and further conduct Lorentz Tree Contrastive Learning with isometric augmentation. As a result, the partitioning tree incorporates node attributes via mutual information maximization, while the cluster assignment is refined by the proposed tree contrastive learning. Extensive experiments on five benchmark datasets show the IsoSEL outperforms 14 recent baselines by an average of +1.3% in NMI.
Striving for Simplicity: Simple Yet Effective Prior-Aware Pseudo-Labeling for Semi-Supervised Ultrasound Image Segmentation
Mar 18, 2025Medical ultrasound imaging is ubiquitous, but manual analysis struggles to keep pace. Automated segmentation can help but requires large labeled datasets, which are scarce. Semi-supervised learning leveraging both unlabeled and limited labeled data is a promising approach. State-of-the-art methods use consistency regularization or pseudo-labeling but grow increasingly complex. Without sufficient labels, these models often latch onto artifacts or allow anatomically implausible segmentations. In this paper, we present a simple yet effective pseudo-labeling method with an adversarially learned shape prior to regularize segmentations. Specifically, we devise an encoder-twin-decoder network where the shape prior acts as an implicit shape model, penalizing anatomically implausible but not ground-truth-deviating predictions. Without bells and whistles, our simple approach achieves state-of-the-art performance on two benchmarks under different partition protocols. We provide a strong baseline for future semi-supervised medical image segmentation. Code is available at https://github.com/WUTCM-Lab/Shape-Prior-Semi-Seg.
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
Feb 28, 2025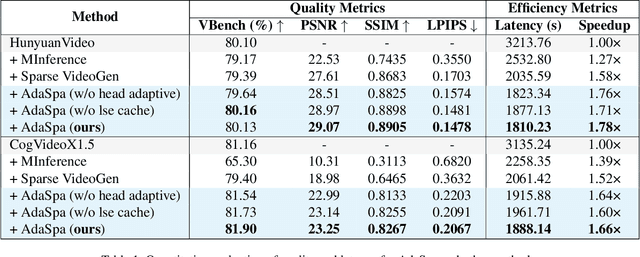
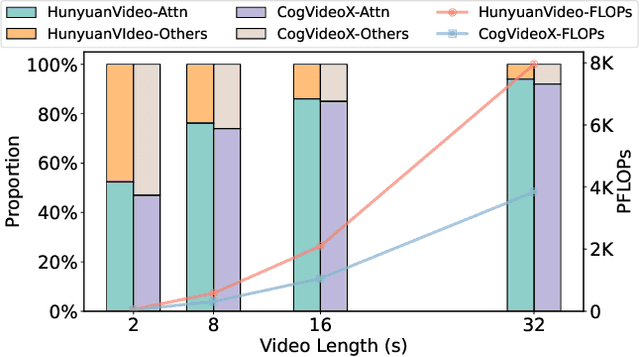
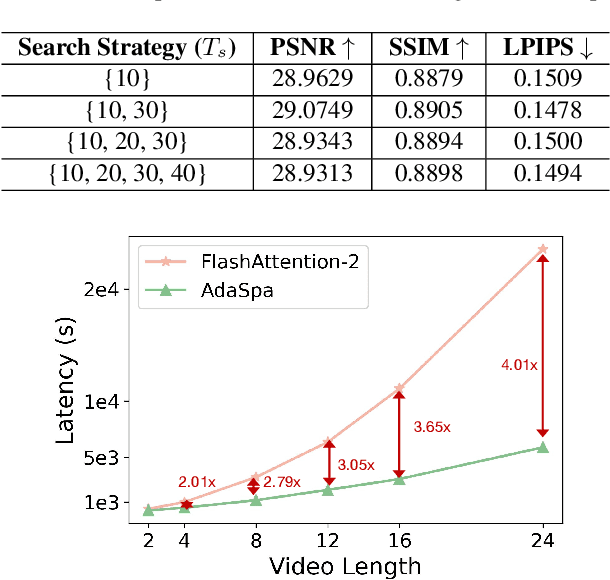
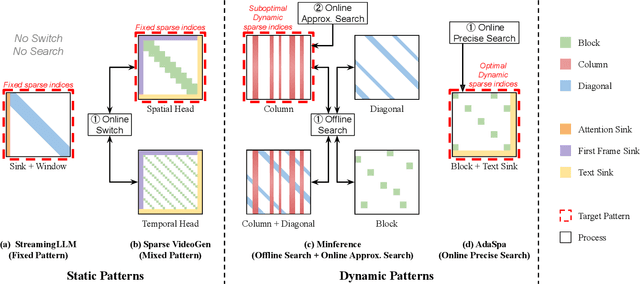
Generating high-fidelity long videos with Diffusion Transformers (DiTs) is often hindered by significant latency, primarily due to the computational demands of attention mechanisms. For instance, generating an 8-second 720p video (110K tokens) with HunyuanVideo takes about 600 PFLOPs, with around 500 PFLOPs consumed by attention computations. To address this issue, we propose AdaSpa, the first Dynamic Pattern and Online Precise Search sparse attention method. Firstly, to realize the Dynamic Pattern, we introduce a blockified pattern to efficiently capture the hierarchical sparsity inherent in DiTs. This is based on our observation that sparse characteristics of DiTs exhibit hierarchical and blockified structures between and within different modalities. This blockified approach significantly reduces the complexity of attention computation while maintaining high fidelity in the generated videos. Secondly, to enable Online Precise Search, we propose the Fused LSE-Cached Search with Head-adaptive Hierarchical Block Sparse Attention. This method is motivated by our finding that DiTs' sparse pattern and LSE vary w.r.t. inputs, layers, and heads, but remain invariant across denoising steps. By leveraging this invariance across denoising steps, it adapts to the dynamic nature of DiTs and allows for precise, real-time identification of sparse indices with minimal overhead. AdaSpa is implemented as an adaptive, plug-and-play solution and can be integrated seamlessly with existing DiTs, requiring neither additional fine-tuning nor a dataset-dependent profiling. Extensive experiments validate that AdaSpa delivers substantial acceleration across various models while preserving video quality, establishing itself as a robust and scalable approach to efficient video generation.
Sparse Brains are Also Adaptive Brains: Cognitive-Load-Aware Dynamic Activation for LLMs
Feb 26, 2025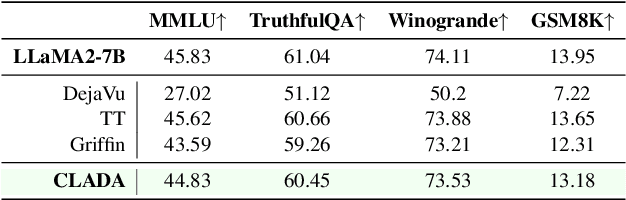
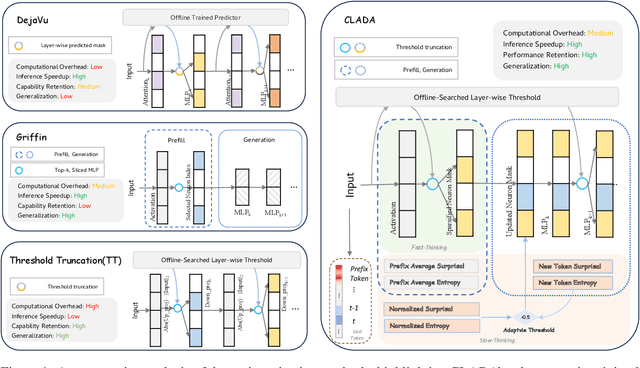
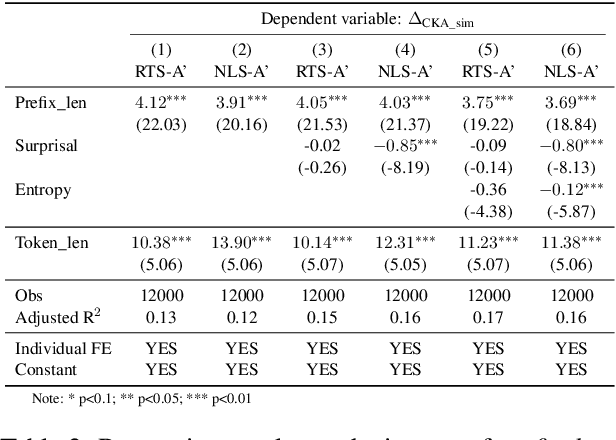
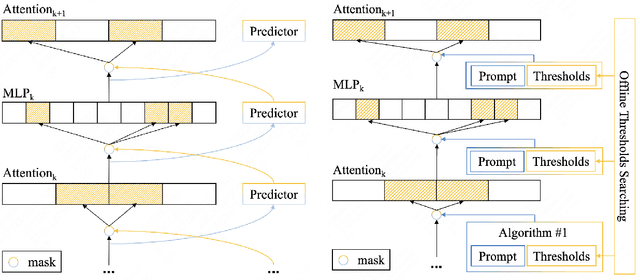
Dense large language models(LLMs) face critical efficiency bottlenecks as they rigidly activate all parameters regardless of input complexity. While existing sparsity methods(static pruning or dynamic activation) address this partially, they either lack adaptivity to contextual or model structural demands or incur prohibitive computational overhead. Inspired by human brain's dual-process mechanisms - predictive coding (N400) for backbone sparsity and structural reanalysis (P600) for complex context - we propose CLADA, a \textit{\textbf{C}ognitive-\textbf{L}oad-\textbf{A}ware \textbf{D}ynamic \textbf{A}ctivation} framework that synergizes statistical sparsity with semantic adaptability. Our key insight is that LLM activations exhibit two complementary patterns: 1) \textit{Global statistical sparsity} driven by sequence-level prefix information, and 2) \textit{Local semantic adaptability} modulated by cognitive load metrics(e.g., surprisal and entropy). CLADA employs a hierarchical thresholding strategy: a baseline from offline error-controlled optimization ensures 40\%+ sparsity, dynamically adjusted by real-time cognitive signals. Evaluations across six mainstream LLMs and nine benchmarks demonstrate that CLADA achieves \textbf{~20\% average speedup with <2\% accuracy drop}, outperforming Griffin (5\%+ degradation) and TT (negligible speedup). Crucially, we establish the first formal connection between neurolinguistic event-related potential (ERP) components and LLM efficiency mechanisms through multi-level regression analysis ($R^2=0.17$ for sparsity-adaptation synergy). Requiring no retraining or architectural changes, CLADA offers a deployable solution for resource-aware LLM inference while advancing biologically-inspired AI design. Our code is available at \href{https://github.com/Oldify/CLADA}{CLADA}.
Pioneer: Physics-informed Riemannian Graph ODE for Entropy-increasing Dynamics
Feb 05, 2025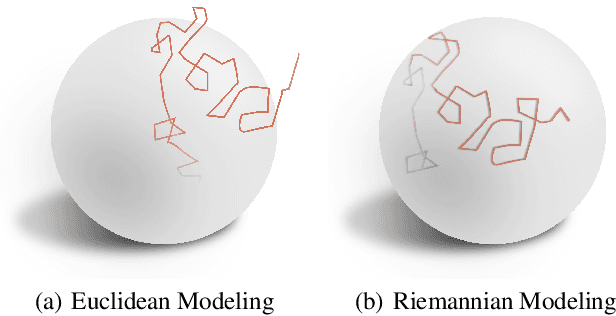
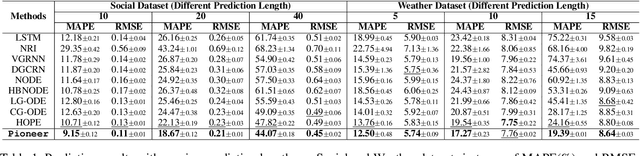
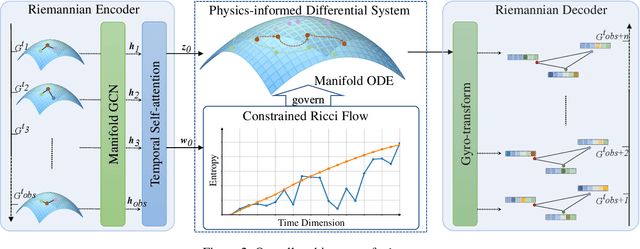
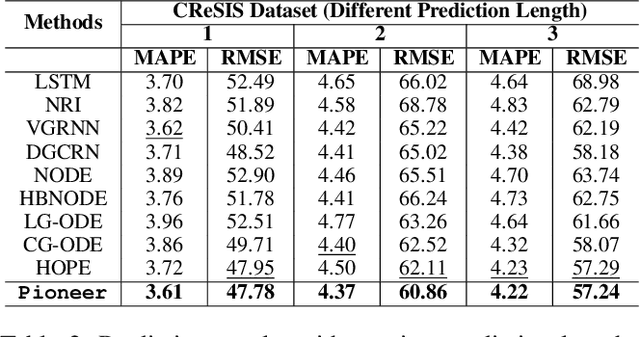
Dynamic interacting system modeling is important for understanding and simulating real world systems. The system is typically described as a graph, where multiple objects dynamically interact with each other and evolve over time. In recent years, graph Ordinary Differential Equations (ODE) receive increasing research attentions. While achieving encouraging results, existing solutions prioritize the traditional Euclidean space, and neglect the intrinsic geometry of the system and physics laws, e.g., the principle of entropy increasing. The limitations above motivate us to rethink the system dynamics from a fresh perspective of Riemannian geometry, and pose a more realistic problem of physics-informed dynamic system modeling, considering the underlying geometry and physics law for the first time. In this paper, we present a novel physics-informed Riemannian graph ODE for a wide range of entropy-increasing dynamic systems (termed as Pioneer). In particular, we formulate a differential system on the Riemannian manifold, where a manifold-valued graph ODE is governed by the proposed constrained Ricci flow, and a manifold preserving Gyro-transform aware of system geometry. Theoretically, we report the provable entropy non-decreasing of our formulation, obeying the physics laws. Empirical results show the superiority of Pioneer on real datasets.