 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Law of Neural Koopman Operators
Feb 23, 2026Data-driven neural Koopman operator theory has emerged as a powerful tool for linearizing and controlling nonlinear robotic systems. However, the performance of these data-driven models fundamentally depends on the trade-off between sample size and model dimensions, a relationship for which the scaling laws have remained unclear. This paper establishes a rigorous framework to address this challenge by deriving and empirically validating scaling laws that connect sample size, latent space dimension, and downstream control quality. We derive a theoretical upper bound on the Koopman approximation error, explicitly decomposing it into sampling error and projection error. We show that these terms decay at specific rates relative to dataset size and latent dimension, providing a rigorous basis for the scaling law. Based on the theoretical results, we introduce two lightweight regularizers for the neural Koopman operator: a covariance loss to help stabilize the learned latent features and an inverse control loss to ensure the model aligns with physical actuation. The results from systematic experiments across six robotic environments confirm that model fitting error follows the derived scaling laws, and the regularizers improve dynamic model fitting fidelity, with enhanced closed-loop control performance. Together, our results provide a simple recipe for allocating effort between data collection and model capacity when learning Koopman dynamics for control.
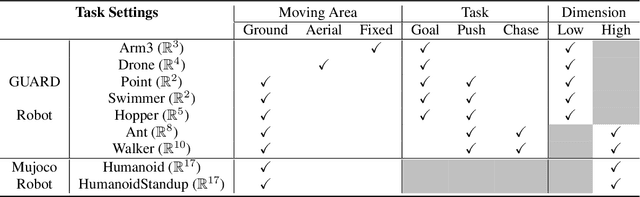
SPARK: A Modular Benchmark for Humanoid Robot Safety
Feb 05, 2025This paper introduces the Safe Protective and Assistive Robot Kit (SPARK), a comprehensive benchmark designed to ensure safety in humanoid autonomy and teleoperation. Humanoid robots pose significant safety risks due to their physical capabilities of interacting with complex environments. The physical structures of humanoid robots further add complexity to the design of general safety solutions. To facilitate the safe deployment of complex robot systems, SPARK can be used as a toolbox that comes with state-of-the-art safe control algorithms in a modular and composable robot control framework. Users can easily configure safety criteria and sensitivity levels to optimize the balance between safety and performance. To accelerate humanoid safety research and development, SPARK provides a simulation benchmark that compares safety approaches in a variety of environments, tasks, and robot models. Furthermore, SPARK allows quick deployment of synthesized safe controllers on real robots. For hardware deployment, SPARK supports Apple Vision Pro (AVP) or a Motion Capture System as external sensors, while also offering interfaces for seamless integration with alternative hardware setups. This paper demonstrates SPARK's capability with both simulation experiments and case studies with a Unitree G1 humanoid robot. Leveraging these advantages of SPARK, users and researchers can significantly improve the safety of their humanoid systems as well as accelerate relevant research. The open-source code is available at https://github.com/intelligent-control-lab/spark.
Continual Learning and Lifting of Koopman Dynamics for Linear Control of Legged Robots
Nov 21, 2024The control of legged robots, particularly humanoid and quadruped robots, presents significant challenges due to their high-dimensional and nonlinear dynamics. While linear systems can be effectively controlled using methods like Model Predictive Control (MPC), the control of nonlinear systems remains complex. One promising solution is the Koopman Operator, which approximates nonlinear dynamics with a linear model, enabling the use of proven linear control techniques. However, achieving accurate linearization through data-driven methods is difficult due to issues like approximation error, domain shifts, and the limitations of fixed linear state-space representations. These challenges restrict the scalability of Koopman-based approaches. This paper addresses these challenges by proposing a continual learning algorithm designed to iteratively refine Koopman dynamics for high-dimensional legged robots. The key idea is to progressively expand the dataset and latent space dimension, enabling the learned Koopman dynamics to converge towards accurate approximations of the true system dynamics. Theoretical analysis shows that the linear approximation error of our method converges monotonically. Experimental results demonstrate that our method achieves high control performance on robots like Unitree G1/H1/A1/Go2 and ANYmal D, across various terrains using simple linear MPC controllers. This work is the first to successfully apply linearized Koopman dynamics for locomotion control of high-dimensional legged robots, enabling a scalable model-based control solution.
Absolute State-wise Constrained Policy Optimization: High-Probability State-wise Constraints Satisfaction
Oct 02, 2024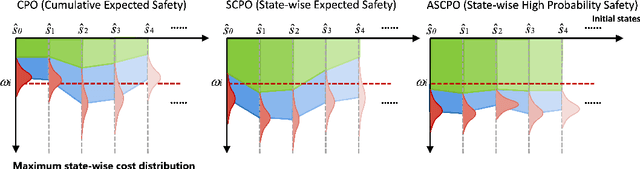

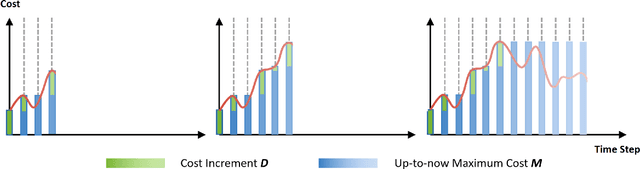

Enforcing state-wise safety constraints is critical for the application of reinforcement learning (RL) in real-world problems, such as autonomous driving and robot manipulation. However, existing safe RL methods only enforce state-wise constraints in expectation or enforce hard state-wise constraints with strong assumptions. The former does not exclude the probability of safety violations, while the latter is impractical. Our insight is that although it is intractable to guarantee hard state-wise constraints in a model-free setting, we can enforce state-wise safety with high probability while excluding strong assumptions. To accomplish the goal, we propose Absolute State-wise Constrained Policy Optimization (ASCPO), a novel general-purpose policy search algorithm that guarantees high-probability state-wise constraint satisfaction for stochastic systems. We demonstrate the effectiveness of our approach by training neural network policies for extensive robot locomotion tasks, where the agent must adhere to various state-wise safety constraints. Our results show that ASCPO significantly outperforms existing methods in handling state-wise constraints across challenging continuous control tasks, highlighting its potential for real-world applications.
Implicit Safe Set Algorithm for Provably Safe Reinforcement Learning
May 04, 2024Deep reinforcement learning (DRL) has demonstrated remarkable performance in many continuous control tasks. However, a significant obstacle to the real-world application of DRL is the lack of safety guarantees. Although DRL agents can satisfy system safety in expectation through reward shaping, designing agents to consistently meet hard constraints (e.g., safety specifications) at every time step remains a formidable challenge. In contrast, existing work in the field of safe control provides guarantees on persistent satisfaction of hard safety constraints. However, these methods require explicit analytical system dynamics models to synthesize safe control, which are typically inaccessible in DRL settings. In this paper, we present a model-free safe control algorithm, the implicit safe set algorithm, for synthesizing safeguards for DRL agents that ensure provable safety throughout training. The proposed algorithm synthesizes a safety index (barrier certificate) and a subsequent safe control law solely by querying a black-box dynamic function (e.g., a digital twin simulator). Moreover, we theoretically prove that the implicit safe set algorithm guarantees finite time convergence to the safe set and forward invariance for both continuous-time and discrete-time systems. We validate the proposed algorithm on the state-of-the-art Safety Gym benchmark, where it achieves zero safety violations while gaining $95\% \pm 9\%$ cumulative reward compared to state-of-the-art safe DRL methods. Furthermore, the resulting algorithm scales well to high-dimensional systems with parallel computing.
Absolute Policy Optimization
Oct 20, 2023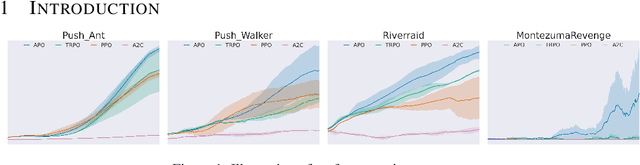

In recent years, trust region on-policy reinforcement learning has achieved impressive results in addressing complex control tasks and gaming scenarios. However, contemporary state-of-the-art algorithms within this category primarily emphasize improvement in expected performance, lacking the ability to control over the worst-case performance outcomes. To address this limitation, we introduce a novel objective function; by optimizing which, it will lead to guaranteed monotonic improvement in the lower bound of near-total performance samples (absolute performance). Considering this groundbreaking theoretical advancement, we then refine this theoretically grounded algorithm through a series of approximations, resulting in a practical solution called Absolute Policy Optimization (APO). Our experiments demonstrate the effectiveness of our approach across challenging continuous control benchmark tasks and extend its applicability to mastering Atari games. Our findings reveal that APO significantly outperforms state-of-the-art policy gradient algorithms, resulting in substantial improvements in both expected performance and worst-case performance.
Learn With Imagination: Safe Set Guided State-wise Constrained Policy Optimization
Aug 25, 2023Deep reinforcement learning (RL) excels in various control tasks, yet the absence of safety guarantees hampers its real-world applicability. In particular, explorations during learning usually results in safety violations, while the RL agent learns from those mistakes. On the other hand, safe control techniques ensure persistent safety satisfaction but demand strong priors on system dynamics, which is usually hard to obtain in practice. To address these problems, we present Safe Set Guided State-wise Constrained Policy Optimization (S-3PO), a pioneering algorithm generating state-wise safe optimal policies with zero training violations, i.e., learning without mistakes. S-3PO first employs a safety-oriented monitor with black-box dynamics to ensure safe exploration. It then enforces a unique cost for the RL agent to converge to optimal behaviors within safety constraints. S-3PO outperforms existing methods in high-dimensional robotics tasks, managing state-wise constraints with zero training violation. This innovation marks a significant stride towards real-world safe RL deployment.