 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Nov 19, 2025
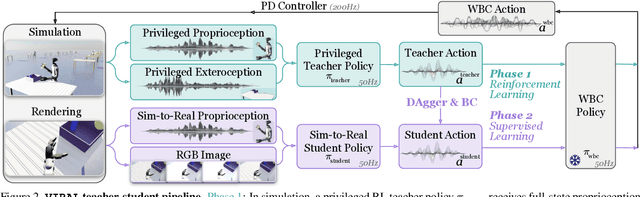

A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays--with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control
May 30, 2025Can your humanoid walk up and hand you a full cup of beer, without spilling a drop? While humanoids are increasingly featured in flashy demos like dancing, delivering packages, traversing rough terrain, fine-grained control during locomotion remains a significant challenge. In particular, stabilizing a filled end-effector (EE) while walking is far from solved, due to a fundamental mismatch in task dynamics: locomotion demands slow-timescale, robust control, whereas EE stabilization requires rapid, high-precision corrections. To address this, we propose SoFTA, a Slow-Fast TwoAgent framework that decouples upper-body and lower-body control into separate agents operating at different frequencies and with distinct rewards. This temporal and objective separation mitigates policy interference and enables coordinated whole-body behavior. SoFTA executes upper-body actions at 100 Hz for precise EE control and lower-body actions at 50 Hz for robust gait. It reduces EE acceleration by 2-5x relative to baselines and performs much closer to human-level stability, enabling delicate tasks such as carrying nearly full cups, capturing steady video during locomotion, and disturbance rejection with EE stability.
Sampling-Based System Identification with Active Exploration for Legged Robot Sim2Real Learning
May 20, 2025Sim-to-real discrepancies hinder learning-based policies from achieving high-precision tasks in the real world. While Domain Randomization (DR) is commonly used to bridge this gap, it often relies on heuristics and can lead to overly conservative policies with degrading performance when not properly tuned. System Identification (Sys-ID) offers a targeted approach, but standard techniques rely on differentiable dynamics and/or direct torque measurement, assumptions that rarely hold for contact-rich legged systems. To this end, we present SPI-Active (Sampling-based Parameter Identification with Active Exploration), a two-stage framework that estimates physical parameters of legged robots to minimize the sim-to-real gap. SPI-Active robustly identifies key physical parameters through massive parallel sampling, minimizing state prediction errors between simulated and real-world trajectories. To further improve the informativeness of collected data, we introduce an active exploration strategy that maximizes the Fisher Information of the collected real-world trajectories via optimizing the input commands of an exploration policy. This targeted exploration leads to accurate identification and better generalization across diverse tasks. Experiments demonstrate that SPI-Active enables precise sim-to-real transfer of learned policies to the real world, outperforming baselines by 42-63% in various locomotion tasks.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation
May 10, 2025Humanoid loco-manipulation holds transformative potential for daily service and industrial tasks, yet achieving precise, robust whole-body control with 3D end-effector force interaction remains a major challenge. Prior approaches are often limited to lightweight tasks or quadrupedal/wheeled platforms. To overcome these limitations, we propose FALCON, a dual-agent reinforcement-learning-based framework for robust force-adaptive humanoid loco-manipulation. FALCON decomposes whole-body control into two specialized agents: (1) a lower-body agent ensuring stable locomotion under external force disturbances, and (2) an upper-body agent precisely tracking end-effector positions with implicit adaptive force compensation. These two agents are jointly trained in simulation with a force curriculum that progressively escalates the magnitude of external force exerted on the end effector while respecting torque limits. Experiments demonstrate that, compared to the baselines, FALCON achieves 2x more accurate upper-body joint tracking, while maintaining robust locomotion under force disturbances and achieving faster training convergence. Moreover, FALCON enables policy training without embodiment-specific reward or curriculum tuning. Using the same training setup, we obtain policies that are deployed across multiple humanoids, enabling forceful loco-manipulation tasks such as transporting payloads (0-20N force), cart-pulling (0-100N), and door-opening (0-40N) in the real world.
Humanoid Policy ~ Human Policy
Mar 17, 2025Training manipulation policies for humanoid robots with diverse data enhances their robustness and generalization across tasks and platforms. However, learning solely from robot demonstrations is labor-intensive, requiring expensive tele-operated data collection which is difficult to scale. This paper investigates a more scalable data source, egocentric human demonstrations, to serve as cross-embodiment training data for robot learning. We mitigate the embodiment gap between humanoids and humans from both the data and modeling perspectives. We collect an egocentric task-oriented dataset (PH2D) that is directly aligned with humanoid manipulation demonstrations. We then train a human-humanoid behavior policy, which we term Human Action Transformer (HAT). The state-action space of HAT is unified for both humans and humanoid robots and can be differentiably retargeted to robot actions. Co-trained with smaller-scale robot data, HAT directly models humanoid robots and humans as different embodiments without additional supervision. We show that human data improves both generalization and robustness of HAT with significantly better data collection efficiency. Code and data: https://human-as-robot.github.io/
ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills
Feb 03, 2025Humanoid robots hold the potential for unparalleled versatility in performing human-like, whole-body skills. However, achieving agile and coordinated whole-body motions remains a significant challenge due to the dynamics mismatch between simulation and the real world. Existing approaches, such as system identification (SysID) and domain randomization (DR) methods, often rely on labor-intensive parameter tuning or result in overly conservative policies that sacrifice agility. In this paper, we present ASAP (Aligning Simulation and Real-World Physics), a two-stage framework designed to tackle the dynamics mismatch and enable agile humanoid whole-body skills. In the first stage, we pre-train motion tracking policies in simulation using retargeted human motion data. In the second stage, we deploy the policies in the real world and collect real-world data to train a delta (residual) action model that compensates for the dynamics mismatch. Then, ASAP fine-tunes pre-trained policies with the delta action model integrated into the simulator to align effectively with real-world dynamics. We evaluate ASAP across three transfer scenarios: IsaacGym to IsaacSim, IsaacGym to Genesis, and IsaacGym to the real-world Unitree G1 humanoid robot. Our approach significantly improves agility and whole-body coordination across various dynamic motions, reducing tracking error compared to SysID, DR, and delta dynamics learning baselines. ASAP enables highly agile motions that were previously difficult to achieve, demonstrating the potential of delta action learning in bridging simulation and real-world dynamics. These results suggest a promising sim-to-real direction for developing more expressive and agile humanoids.
Bridging Adaptivity and Safety: Learning Agile Collision-Free Locomotion Across Varied Physics
Jan 08, 2025Real-world legged locomotion systems often need to reconcile agility and safety for different scenarios. Moreover, the underlying dynamics are often unknown and time-variant (e.g., payload, friction). In this paper, we introduce BAS (Bridging Adaptivity and Safety), which builds upon the pipeline of prior work Agile But Safe (ABS)(He et al.) and is designed to provide adaptive safety even in dynamic environments with uncertainties. BAS involves an agile policy to avoid obstacles rapidly and a recovery policy to prevent collisions, a physical parameter estimator that is concurrently trained with agile policy, and a learned control-theoretic RA (reach-avoid) value network that governs the policy switch. Also, the agile policy and RA network are both conditioned on physical parameters to make them adaptive. To mitigate the distribution shift issue, we further introduce an on-policy fine-tuning phase for the estimator to enhance its robustness and accuracy. The simulation results show that BAS achieves 50% better safety than baselines in dynamic environments while maintaining a higher speed on average. In real-world experiments, BAS shows its capability in complex environments with unknown physics (e.g., slippery floors with unknown frictions, unknown payloads up to 8kg), while baselines lack adaptivity, leading to collisions or. degraded agility. As a result, BAS achieves a 19.8% increase in speed and gets a 2.36 times lower collision rate than ABS in the real world. Videos: https://adaptive-safe-locomotion.github.io.
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
Oct 28, 2024



Humanoid whole-body control requires adapting to diverse tasks such as navigation, loco-manipulation, and tabletop manipulation, each demanding a different mode of control. For example, navigation relies on root velocity tracking, while tabletop manipulation prioritizes upper-body joint angle tracking. Existing approaches typically train individual policies tailored to a specific command space, limiting their transferability across modes. We present the key insight that full-body kinematic motion imitation can serve as a common abstraction for all these tasks and provide general-purpose motor skills for learning multiple modes of whole-body control. Building on this, we propose HOVER (Humanoid Versatile Controller), a multi-mode policy distillation framework that consolidates diverse control modes into a unified policy. HOVER enables seamless transitions between control modes while preserving the distinct advantages of each, offering a robust and scalable solution for humanoid control across a wide range of modes. By eliminating the need for policy retraining for each control mode, our approach improves efficiency and flexibility for future humanoid applications.