 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Peel with a Knife: Aligning Fine-Grained Manipulation with Human Preference
Mar 03, 2026Many essential manipulation tasks - such as food preparation, surgery, and craftsmanship - remain intractable for autonomous robots. These tasks are characterized not only by contact-rich, force-sensitive dynamics, but also by their "implicit" success criteria: unlike pick-and-place, task quality in these domains is continuous and subjective (e.g. how well a potato is peeled), making quantitative evaluation and reward engineering difficult. We present a learning framework for such tasks, using peeling with a knife as a representative example. Our approach follows a two-stage pipeline: first, we learn a robust initial policy via force-aware data collection and imitation learning, enabling generalization across object variations; second, we refine the policy through preference-based finetuning using a learned reward model that combines quantitative task metrics with qualitative human feedback, aligning policy behavior with human notions of task quality. Using only 50-200 peeling trajectories, our system achieves over 90% average success rates on challenging produce including cucumbers, apples, and potatoes, with performance improving by up to 40% through preference-based finetuning. Remarkably, policies trained on a single produce category exhibit strong zero-shot generalization to unseen in-category instances and to out-of-distribution produce from different categories while maintaining over 90% success rates.
Coordinated Humanoid Manipulation with Choice Policies
Dec 31, 2025Humanoid robots hold great promise for operating in human-centric environments, yet achieving robust whole-body coordination across the head, hands, and legs remains a major challenge. We present a system that combines a modular teleoperation interface with a scalable learning framework to address this problem. Our teleoperation design decomposes humanoid control into intuitive submodules, which include hand-eye coordination, grasp primitives, arm end-effector tracking, and locomotion. This modularity allows us to collect high-quality demonstrations efficiently. Building on this, we introduce Choice Policy, an imitation learning approach that generates multiple candidate actions and learns to score them. This architecture enables both fast inference and effective modeling of multimodal behaviors. We validate our approach on two real-world tasks: dishwasher loading and whole-body loco-manipulation for whiteboard wiping. Experiments show that Choice Policy significantly outperforms diffusion policies and standard behavior cloning. Furthermore, our results indicate that hand-eye coordination is critical for success in long-horizon tasks. Our work demonstrates a practical path toward scalable data collection and learning for coordinated humanoid manipulation in unstructured environments.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids
Feb 27, 2025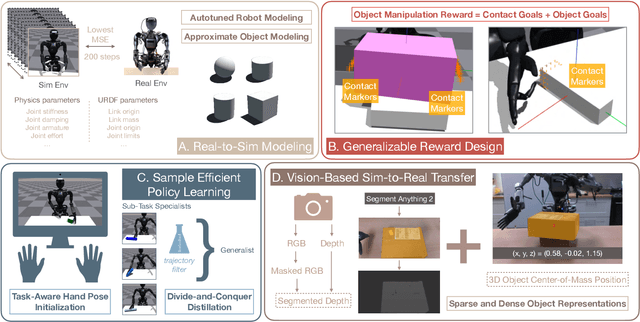

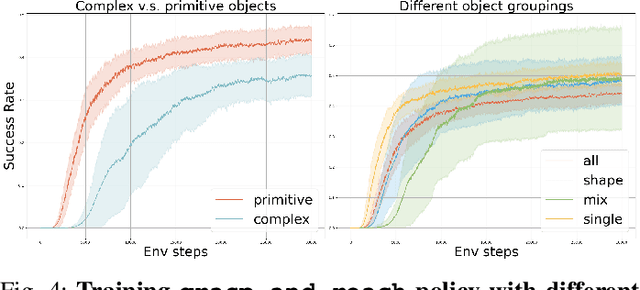
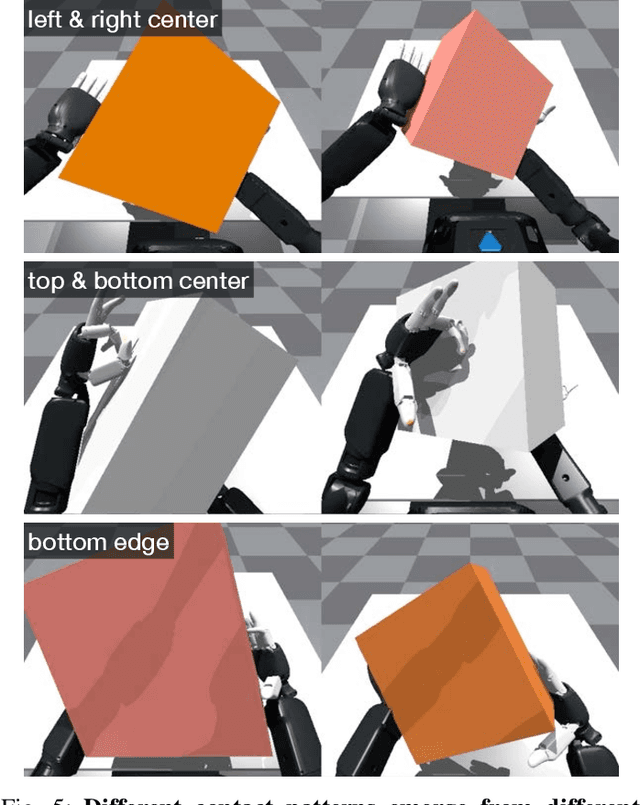
Reinforcement learning has delivered promising results in achieving human- or even superhuman-level capabilities across diverse problem domains, but success in dexterous robot manipulation remains limited. This work investigates the key challenges in applying reinforcement learning to solve a collection of contact-rich manipulation tasks on a humanoid embodiment. We introduce novel techniques to overcome the identified challenges with empirical validation. Our main contributions include an automated real-to-sim tuning module that brings the simulated environment closer to the real world, a generalized reward design scheme that simplifies reward engineering for long-horizon contact-rich manipulation tasks, a divide-and-conquer distillation process that improves the sample efficiency of hard-exploration problems while maintaining sim-to-real performance, and a mixture of sparse and dense object representations to bridge the sim-to-real perception gap. We show promising results on three humanoid dexterous manipulation tasks, with ablation studies on each technique. Our work presents a successful approach to learning humanoid dexterous manipulation using sim-to-real reinforcement learning, achieving robust generalization and high performance without the need for human demonstration.
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
Oct 28, 2024



Humanoid whole-body control requires adapting to diverse tasks such as navigation, loco-manipulation, and tabletop manipulation, each demanding a different mode of control. For example, navigation relies on root velocity tracking, while tabletop manipulation prioritizes upper-body joint angle tracking. Existing approaches typically train individual policies tailored to a specific command space, limiting their transferability across modes. We present the key insight that full-body kinematic motion imitation can serve as a common abstraction for all these tasks and provide general-purpose motor skills for learning multiple modes of whole-body control. Building on this, we propose HOVER (Humanoid Versatile Controller), a multi-mode policy distillation framework that consolidates diverse control modes into a unified policy. HOVER enables seamless transitions between control modes while preserving the distinct advantages of each, offering a robust and scalable solution for humanoid control across a wide range of modes. By eliminating the need for policy retraining for each control mode, our approach improves efficiency and flexibility for future humanoid applications.
Learning Visuotactile Skills with Two Multifingered Hands
Apr 25, 2024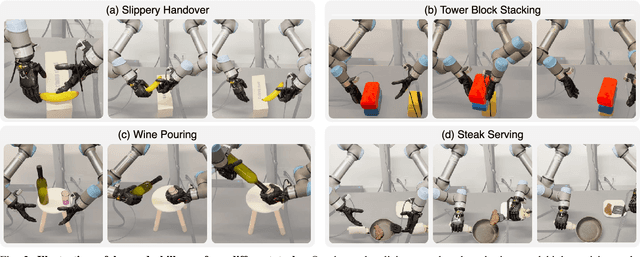
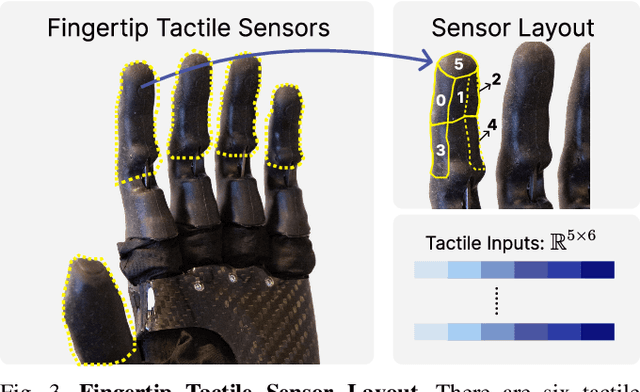
Aiming to replicate human-like dexterity, perceptual experiences, and motion patterns, we explore learning from human demonstrations using a bimanual system with multifingered hands and visuotactile data. Two significant challenges exist: the lack of an affordable and accessible teleoperation system suitable for a dual-arm setup with multifingered hands, and the scarcity of multifingered hand hardware equipped with touch sensing. To tackle the first challenge, we develop HATO, a low-cost hands-arms teleoperation system that leverages off-the-shelf electronics, complemented with a software suite that enables efficient data collection; the comprehensive software suite also supports multimodal data processing, scalable policy learning, and smooth policy deployment. To tackle the latter challenge, we introduce a novel hardware adaptation by repurposing two prosthetic hands equipped with touch sensors for research. Using visuotactile data collected from our system, we learn skills to complete long-horizon, high-precision tasks which are difficult to achieve without multifingered dexterity and touch feedback. Furthermore, we empirically investigate the effects of dataset size, sensing modality, and visual input preprocessing on policy learning. Our results mark a promising step forward in bimanual multifingered manipulation from visuotactile data. Videos, code, and datasets can be found at https://toruowo.github.io/hato/ .
Twisting Lids Off with Two Hands
Mar 04, 2024

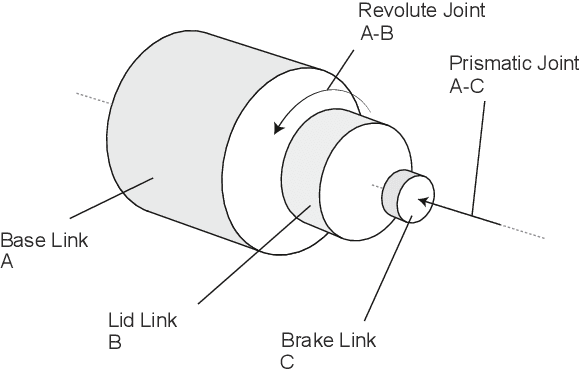

Manipulating objects with two multi-fingered hands has been a long-standing challenge in robotics, attributed to the contact-rich nature of many manipulation tasks and the complexity inherent in coordinating a high-dimensional bimanual system. In this work, we consider the problem of twisting lids of various bottle-like objects with two hands, and demonstrate that policies trained in simulation using deep reinforcement learning can be effectively transferred to the real world. With novel engineering insights into physical modeling, real-time perception, and reward design, the policy demonstrates generalization capabilities across a diverse set of unseen objects, showcasing dynamic and dexterous behaviors. Our findings serve as compelling evidence that deep reinforcement learning combined with sim-to-real transfer remains a promising approach for addressing manipulation problems of unprecedented complexity.
MIMEx: Intrinsic Rewards from Masked Input Modeling
May 15, 2023
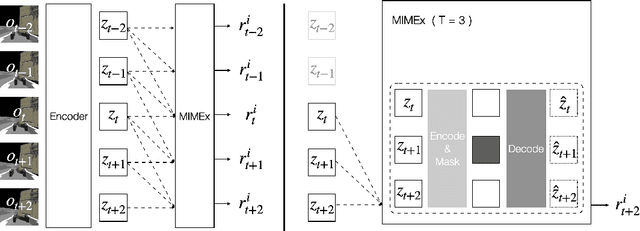
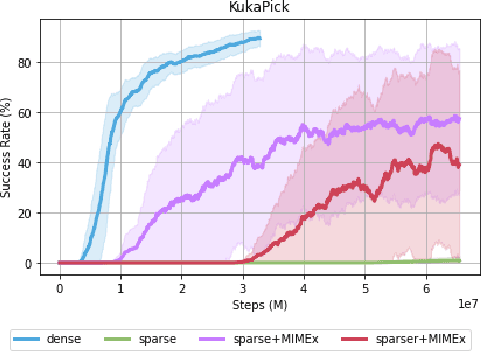
Exploring in environments with high-dimensional observations is hard. One promising approach for exploration is to use intrinsic rewards, which often boils down to estimating "novelty" of states, transitions, or trajectories with deep networks. Prior works have shown that conditional prediction objectives such as masked autoencoding can be seen as stochastic estimation of pseudo-likelihood. We show how this perspective naturally leads to a unified view on existing intrinsic reward approaches: they are special cases of conditional prediction, where the estimation of novelty can be seen as pseudo-likelihood estimation with different mask distributions. From this view, we propose a general framework for deriving intrinsic rewards -- Masked Input Modeling for Exploration (MIMEx) -- where the mask distribution can be flexibly tuned to control the difficulty of the underlying conditional prediction task. We demonstrate that MIMEx can achieve superior results when compared against competitive baselines on a suite of challenging sparse-reward visuomotor tasks.
Learning to Ground Multi-Agent Communication with Autoencoders
Oct 28, 2021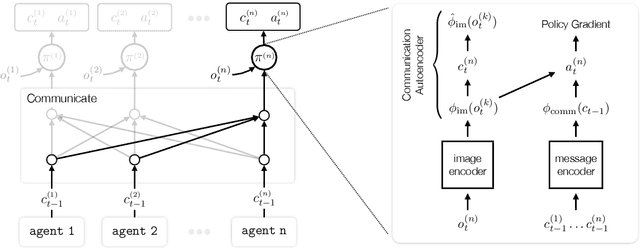
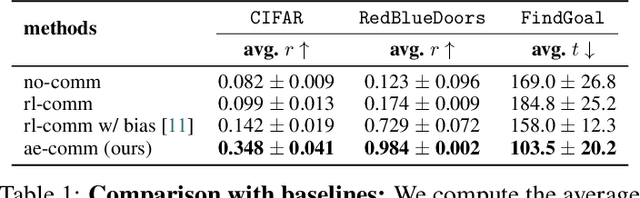
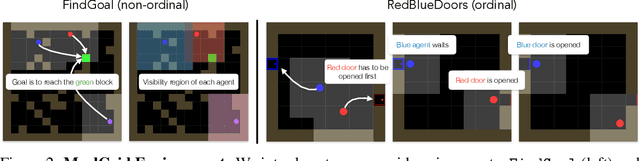

Communication requires having a common language, a lingua franca, between agents. This language could emerge via a consensus process, but it may require many generations of trial and error. Alternatively, the lingua franca can be given by the environment, where agents ground their language in representations of the observed world. We demonstrate a simple way to ground language in learned representations, which facilitates decentralized multi-agent communication and coordination. We find that a standard representation learning algorithm -- autoencoding -- is sufficient for arriving at a grounded common language. When agents broadcast these representations, they learn to understand and respond to each other's utterances and achieve surprisingly strong task performance across a variety of multi-agent communication environments.
Visual Grounding of Learned Physical Models
Apr 28, 2020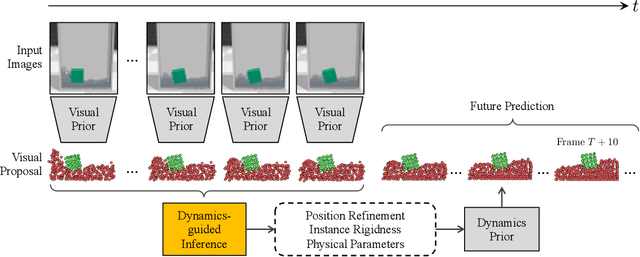
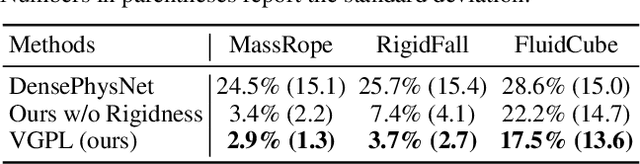
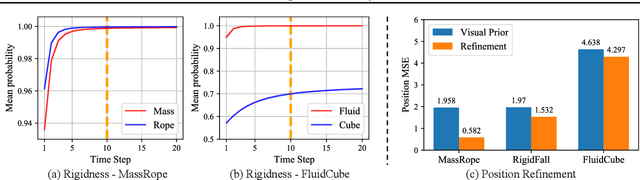

Humans intuitively recognize objects' physical properties and predict their motion, even when the objects are engaged in complicated interactions. The abilities to perform physical reasoning and to adapt to new environments, while intrinsic to humans, remain challenging to state-of-the-art computational models. In this work, we present a neural model that simultaneously reasons about physics and make future predictions based on visual and dynamics priors. The visual prior predicts a particle-based representation of the system from visual observations. An inference module operates on those particles, predicting and refining estimates of particle locations, object states, and physical parameters, subject to the constraints imposed by the dynamics prior, which we refer to as visual grounding. We demonstrate the effectiveness of our method in environments involving rigid objects, deformable materials, and fluids. Experiments show that our model can infer the physical properties within a few observations, which allows the model to quickly adapt to unseen scenarios and make accurate predictions into the future.