 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFuse: Accelerating Dynamic Adapter Inference via Token-Level Pre-Gating and Fused Kernel Optimization
Mar 12, 2026The integration of dynamic, sparse structures like Mixture-of-Experts (MoE) with parameter-efficient adapters (e.g., LoRA) is a powerful technique for enhancing Large Language Models (LLMs). However, this architectural enhancement comes at a steep cost: despite minimal increases in computational load, the inference latency often skyrockets, leading to decoding speeds slowing by over 2.5 times. Through a fine-grained performance analysis, we pinpoint the primary bottleneck not in the computation itself, but in the severe overhead from fragmented, sequential CUDA kernel launches required for conventional dynamic routing. To address this challenge, we introduce AdaFuse, a framework built on a tight co-design between the algorithm and the underlying hardware system to enable efficient dynamic adapter execution. Departing from conventional layer-wise or block-wise routing, AdaFuse employs a token-level pre-gating strategy, which makes a single, global routing decision for all adapter layers before a token is processed. This "decide-once, apply-everywhere" approach effectively staticizes the execution path for each token, creating an opportunity for holistic optimization. We capitalize on this by developing a custom CUDA kernel that performs a fused switching operation, merging the parameters of all selected LoRA adapters into the backbone model in a single, efficient pass. Experimental results on popular open-source LLMs show that AdaFuse achieves accuracy on par with state-of-the-art dynamic adapters while drastically cutting decoding latency by a factor of over 2.4x, thereby bridging the gap between model capability and inference efficiency.
Q-learning with Adjoint Matching
Jan 20, 2026We propose Q-learning with Adjoint Matching (QAM), a novel TD-based reinforcement learning (RL) algorithm that tackles a long-standing challenge in continuous-action RL: efficient optimization of an expressive diffusion or flow-matching policy with respect to a parameterized Q-function. Effective optimization requires exploiting the first-order information of the critic, but it is challenging to do so for flow or diffusion policies because direct gradient-based optimization via backpropagation through their multi-step denoising process is numerically unstable. Existing methods work around this either by only using the value and discarding the gradient information, or by relying on approximations that sacrifice policy expressivity or bias the learned policy. QAM sidesteps both of these challenges by leveraging adjoint matching, a recently proposed technique in generative modeling, which transforms the critic's action gradient to form a step-wise objective function that is free from unstable backpropagation, while providing an unbiased, expressive policy at the optimum. Combined with temporal-difference backup for critic learning, QAM consistently outperforms prior approaches on hard, sparse reward tasks in both offline and offline-to-online RL.
Decoupled Q-Chunking
Dec 12, 2025



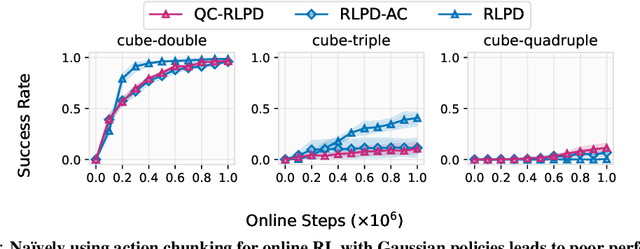
Temporal-difference (TD) methods learn state and action values efficiently by bootstrapping from their own future value predictions, but such a self-bootstrapping mechanism is prone to bootstrapping bias, where the errors in the value targets accumulate across steps and result in biased value estimates. Recent work has proposed to use chunked critics, which estimate the value of short action sequences ("chunks") rather than individual actions, speeding up value backup. However, extracting policies from chunked critics is challenging: policies must output the entire action chunk open-loop, which can be sub-optimal for environments that require policy reactivity and also challenging to model especially when the chunk length grows. Our key insight is to decouple the chunk length of the critic from that of the policy, allowing the policy to operate over shorter action chunks. We propose a novel algorithm that achieves this by optimizing the policy against a distilled critic for partial action chunks, constructed by optimistically backing up from the original chunked critic to approximate the maximum value achievable when a partial action chunk is extended to a complete one. This design retains the benefits of multi-step value propagation while sidestepping both the open-loop sub-optimality and the difficulty of learning action chunking policies for long action chunks. We evaluate our method on challenging, long-horizon offline goal-conditioned tasks and show that it reliably outperforms prior methods. Code: github.com/ColinQiyangLi/dqc.
EXPO: Stable Reinforcement Learning with Expressive Policies
Jul 10, 2025We study the problem of training and fine-tuning expressive policies with online reinforcement learning (RL) given an offline dataset. Training expressive policy classes with online RL present a unique challenge of stable value maximization. Unlike simpler Gaussian policies commonly used in online RL, expressive policies like diffusion and flow-matching policies are parameterized by a long denoising chain, which hinders stable gradient propagation from actions to policy parameters when optimizing against some value function. Our key insight is that we can address stable value maximization by avoiding direct optimization over value with the expressive policy and instead construct an on-the-fly RL policy to maximize Q-value. We propose Expressive Policy Optimization (EXPO), a sample-efficient online RL algorithm that utilizes an on-the-fly policy to maximize value with two parameterized policies -- a larger expressive base policy trained with a stable imitation learning objective and a light-weight Gaussian edit policy that edits the actions sampled from the base policy toward a higher value distribution. The on-the-fly policy optimizes the actions from the base policy with the learned edit policy and chooses the value maximizing action from the base and edited actions for both sampling and temporal-difference (TD) backup. Our approach yields up to 2-3x improvement in sample efficiency on average over prior methods both in the setting of fine-tuning a pretrained policy given offline data and in leveraging offline data to train online.
Reinforcement Learning with Action Chunking
Jul 10, 2025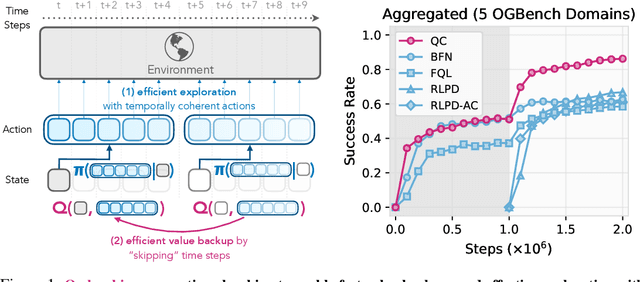

We present Q-chunking, a simple yet effective recipe for improving reinforcement learning (RL) algorithms for long-horizon, sparse-reward tasks. Our recipe is designed for the offline-to-online RL setting, where the goal is to leverage an offline prior dataset to maximize the sample-efficiency of online learning. Effective exploration and sample-efficient learning remain central challenges in this setting, as it is not obvious how the offline data should be utilized to acquire a good exploratory policy. Our key insight is that action chunking, a technique popularized in imitation learning where sequences of future actions are predicted rather than a single action at each timestep, can be applied to temporal difference (TD)-based RL methods to mitigate the exploration challenge. Q-chunking adopts action chunking by directly running RL in a 'chunked' action space, enabling the agent to (1) leverage temporally consistent behaviors from offline data for more effective online exploration and (2) use unbiased $n$-step backups for more stable and efficient TD learning. Our experimental results demonstrate that Q-chunking exhibits strong offline performance and online sample efficiency, outperforming prior best offline-to-online methods on a range of long-horizon, sparse-reward manipulation tasks.
Flow Q-Learning
Feb 04, 2025We present flow Q-learning (FQL), a simple and performant offline reinforcement learning (RL) method that leverages an expressive flow-matching policy to model arbitrarily complex action distributions in data. Training a flow policy with RL is a tricky problem, due to the iterative nature of the action generation process. We address this challenge by training an expressive one-step policy with RL, rather than directly guiding an iterative flow policy to maximize values. This way, we can completely avoid unstable recursive backpropagation, eliminate costly iterative action generation at test time, yet still mostly maintain expressivity. We experimentally show that FQL leads to strong performance across 73 challenging state- and pixel-based OGBench and D4RL tasks in offline RL and offline-to-online RL. Project page: https://seohong.me/projects/fql/
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
Dec 13, 2024Recent advances in robotic foundation models have enabled the development of generalist policies that can adapt to diverse tasks. While these models show impressive flexibility, their performance heavily depends on the quality of their training data. In this work, we propose Reinforcement Learning Distilled Generalists (RLDG), a method that leverages reinforcement learning to generate high-quality training data for finetuning generalist policies. Through extensive real-world experiments on precise manipulation tasks like connector insertion and assembly, we demonstrate that generalist policies trained with RL-generated data consistently outperform those trained with human demonstrations, achieving up to 40% higher success rates while generalizing better to new tasks. We also provide a detailed analysis that reveals this performance gain stems from both optimized action distributions and improved state coverage. Our results suggest that combining task-specific RL with generalist policy distillation offers a promising approach for developing more capable and efficient robotic manipulation systems that maintain the flexibility of foundation models while achieving the performance of specialized controllers. Videos and code can be found on our project website https://generalist-distillation.github.io
Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data
Dec 10, 2024



The modern paradigm in machine learning involves pre-training on diverse data, followed by task-specific fine-tuning. In reinforcement learning (RL), this translates to learning via offline RL on a diverse historical dataset, followed by rapid online RL fine-tuning using interaction data. Most RL fine-tuning methods require continued training on offline data for stability and performance. However, this is undesirable because training on diverse offline data is slow and expensive for large datasets, and in principle, also limit the performance improvement possible because of constraints or pessimism on offline data. In this paper, we show that retaining offline data is unnecessary as long as we use a properly-designed online RL approach for fine-tuning offline RL initializations. To build this approach, we start by analyzing the role of retaining offline data in online fine-tuning. We find that continued training on offline data is mostly useful for preventing a sudden divergence in the value function at the onset of fine-tuning, caused by a distribution mismatch between the offline data and online rollouts. This divergence typically results in unlearning and forgetting the benefits of offline pre-training. Our approach, Warm-start RL (WSRL), mitigates the catastrophic forgetting of pre-trained initializations using a very simple idea. WSRL employs a warmup phase that seeds the online RL run with a very small number of rollouts from the pre-trained policy to do fast online RL. The data collected during warmup helps ``recalibrate'' the offline Q-function to the online distribution, allowing us to completely discard offline data without destabilizing the online RL fine-tuning. We show that WSRL is able to fine-tune without retaining any offline data, and is able to learn faster and attains higher performance than existing algorithms irrespective of whether they retain offline data or not.
Leveraging Skills from Unlabeled Prior Data for Efficient Online Exploration
Oct 23, 2024



Unsupervised pretraining has been transformative in many supervised domains. However, applying such ideas to reinforcement learning (RL) presents a unique challenge in that fine-tuning does not involve mimicking task-specific data, but rather exploring and locating the solution through iterative self-improvement. In this work, we study how unlabeled prior trajectory data can be leveraged to learn efficient exploration strategies. While prior data can be used to pretrain a set of low-level skills, or as additional off-policy data for online RL, it has been unclear how to combine these ideas effectively for online exploration. Our method SUPE (Skills from Unlabeled Prior data for Exploration) demonstrates that a careful combination of these ideas compounds their benefits. Our method first extracts low-level skills using a variational autoencoder (VAE), and then pseudo-relabels unlabeled trajectories using an optimistic reward model, transforming prior data into high-level, task-relevant examples. Finally, SUPE uses these transformed examples as additional off-policy data for online RL to learn a high-level policy that composes pretrained low-level skills to explore efficiently. We empirically show that SUPE reliably outperforms prior strategies, successfully solving a suite of long-horizon, sparse-reward tasks. Code: https://github.com/rail-berkeley/supe.
LoRA-Switch: Boosting the Efficiency of Dynamic LLM Adapters via System-Algorithm Co-design
May 28, 2024Recent literature has found that an effective method to customize or further improve large language models (LLMs) is to add dynamic adapters, such as low-rank adapters (LoRA) with Mixture-of-Experts (MoE) structures. Though such dynamic adapters incur modest computational complexity, they surprisingly lead to huge inference latency overhead, slowing down the decoding speed by 2.5+ times. In this paper, we analyze the fine-grained costs of the dynamic adapters and find that the fragmented CUDA kernel calls are the root cause. Therefore, we propose LoRA-Switch, a system-algorithm co-designed architecture for efficient dynamic adapters. Unlike most existing dynamic structures that adopt layer-wise or block-wise dynamic routing, LoRA-Switch introduces a token-wise routing mechanism. It switches the LoRA adapters and weights for each token and merges them into the backbone for inference. For efficiency, this switching is implemented with an optimized CUDA kernel, which fuses the merging operations for all LoRA adapters at once. Based on experiments with popular open-source LLMs on common benchmarks, our approach has demonstrated similar accuracy improvement as existing dynamic adapters, while reducing the decoding latency by more than 2.4 times.