 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterating Toward Better Search: A Two-Agent Simulation Framework for Evaluating Agentic Search Architectures in E-Commerce
Jun 11, 2026We present a modular two-agent simulation framework for evaluating conversational shopping assistant architectures. An independent buyer agent, configured with personas, missions, and patience levels, is paired with an interchangeable responder that integrates with a real e-commerce search API. Holding the buyer constant across experiments enables controlled comparison of responder designs on identical scenarios. Using 2011 conversations across 14 persona buckets, we establish four empirical findings. First, rolling-window memory outperforms intent-extraction memory on all quality metrics while being 35% faster per query. Second, illustrating rapid evidence-driven iteration, a systematic failure analysis of a responder version enables targeted fixes that reduce failure and near-failure rates by 62% across the full dataset. Third, swapping the responder LLM backbone from Gemini~2.5 to Llama~3.3~70B costs 0.16--0.45 points despite identical architecture. Finally, we document systematic philosophical disagreement between frontier LLM judges: Gemini rewards process correctness while Claude demands concrete outcomes, despite using the same evaluation prompt.
Joint Agent Memory and Exploration Learning via Novelty Signals
Jun 01, 2026In open-ended environments, exploration is fundamental for autonomous agents, yet current language model agents struggle with this. Effective exploration requires memory, but retaining raw interaction histories is computationally expensive over long trajectories. While latent memory offers a solution to compress interaction histories, its training lacks reliable supervisory signals. We introduce \textbf{J}oint \textbf{A}gent \textbf{M}emory and \textbf{E}xploration \textbf{L}earning (\textbf{JAMEL}), a framework that trains agentic memory and exploration policy together through novelty-driven interaction. We observe that memory and exploration form a mutually dependent loop: sustained exploration requires memory to distinguish exhausted behaviors from unseen ones, while novelty-seeking interaction provides the supervision needed to make memory useful for future exploration. By utilizing deterministic and persistent novelty signals such as code coverage in the GUI domain, we provide natural, annotation-free supervision for the memory module. Empirical evaluations demonstrate that \ours successfully generalizes to unseen environments. Its exploration capability outperforms open-weight baselines and rivals the exploration depth of a closed-source model while reducing token consumption. Our code and model are open-sourced at https://github.com/MobileLLM/JAMEL.
EndPrompt: Efficient Long-Context Extension via Terminal Anchoring
May 14, 2026Extending the context window of large language models typically requires training on sequences at the target length, incurring quadratic memory and computational costs that make long-context adaptation expensive and difficult to reproduce. We propose EndPrompt, a method that achieves effective context extension using only short training sequences. The core insight is that exposing a model to long-range relative positional distances does not require constructing full-length inputs: we preserve the original short context as an intact first segment and append a brief terminal prompt as a second segment, assigning it positional indices near the target context length. This two-segment construction introduces both local and long-range relative distances within a short physical sequence while maintaining the semantic continuity of the training text--a property absent in chunk-based simulation approaches that split contiguous context. We provide a theoretical analysis grounded in Rotary Position Embedding and the Bernstein inequality, showing that position interpolation induces a rigorous smoothness constraint over the attention function, with shared Transformer parameters further suppressing unstable extrapolation to unobserved intermediate distances. Applied to LLaMA-family models extending the context window from 8K to 64K, EndPrompt achieves an average RULER score of 76.03 and the highest average on LongBench, surpassing LCEG (72.24), LongLoRA (72.95), and full-length fine-tuning (69.23) while requiring substantially less computation. These results demonstrate that long-context generalization can be induced from sparse positional supervision, challenging the prevailing assumption that dense long-sequence training is necessary for reliable context-window extension. The code is available at https://github.com/clx1415926/EndPrompt.
AdaFuse: Accelerating Dynamic Adapter Inference via Token-Level Pre-Gating and Fused Kernel Optimization
Mar 12, 2026The integration of dynamic, sparse structures like Mixture-of-Experts (MoE) with parameter-efficient adapters (e.g., LoRA) is a powerful technique for enhancing Large Language Models (LLMs). However, this architectural enhancement comes at a steep cost: despite minimal increases in computational load, the inference latency often skyrockets, leading to decoding speeds slowing by over 2.5 times. Through a fine-grained performance analysis, we pinpoint the primary bottleneck not in the computation itself, but in the severe overhead from fragmented, sequential CUDA kernel launches required for conventional dynamic routing. To address this challenge, we introduce AdaFuse, a framework built on a tight co-design between the algorithm and the underlying hardware system to enable efficient dynamic adapter execution. Departing from conventional layer-wise or block-wise routing, AdaFuse employs a token-level pre-gating strategy, which makes a single, global routing decision for all adapter layers before a token is processed. This "decide-once, apply-everywhere" approach effectively staticizes the execution path for each token, creating an opportunity for holistic optimization. We capitalize on this by developing a custom CUDA kernel that performs a fused switching operation, merging the parameters of all selected LoRA adapters into the backbone model in a single, efficient pass. Experimental results on popular open-source LLMs show that AdaFuse achieves accuracy on par with state-of-the-art dynamic adapters while drastically cutting decoding latency by a factor of over 2.4x, thereby bridging the gap between model capability and inference efficiency.
V-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.
LoRA-Switch: Boosting the Efficiency of Dynamic LLM Adapters via System-Algorithm Co-design
May 28, 2024Recent literature has found that an effective method to customize or further improve large language models (LLMs) is to add dynamic adapters, such as low-rank adapters (LoRA) with Mixture-of-Experts (MoE) structures. Though such dynamic adapters incur modest computational complexity, they surprisingly lead to huge inference latency overhead, slowing down the decoding speed by 2.5+ times. In this paper, we analyze the fine-grained costs of the dynamic adapters and find that the fragmented CUDA kernel calls are the root cause. Therefore, we propose LoRA-Switch, a system-algorithm co-designed architecture for efficient dynamic adapters. Unlike most existing dynamic structures that adopt layer-wise or block-wise dynamic routing, LoRA-Switch introduces a token-wise routing mechanism. It switches the LoRA adapters and weights for each token and merges them into the backbone for inference. For efficiency, this switching is implemented with an optimized CUDA kernel, which fuses the merging operations for all LoRA adapters at once. Based on experiments with popular open-source LLMs on common benchmarks, our approach has demonstrated similar accuracy improvement as existing dynamic adapters, while reducing the decoding latency by more than 2.4 times.
Data-Driven Stability Assessment of Power Electronic Converters with Multi-Resolution Dynamic Mode Decomposition
Apr 15, 2024



Harmonic instability occurs frequently in the power electronic converter system. This paper leverages multi-resolution dynamic mode decomposition (MR-DMD) as a data-driven diagnostic tool for the system stability of power electronic converters, not requiring complex modeling and detailed control information. By combining dynamic mode decomposition (DMD) with the multi-resolution analysis used in wavelet theory, dynamic modes and eigenvalues can be identified at different decomposition levels and time scales with the MR-DMD algorithm, thereby allowing for handling datasets with transient time behaviors, which is not achievable using conventional DMD. Further, the selection criteria for important parameters in MR-DMD are clearly defined through derivation, elucidating the reason for enabling it to extract eigenvalues within different frequency ranges. Finally, the analysis results are verified using the dataset collected from the experimental platform of a low-frequency oscillation scenario in electrified railways featuring a single-phase converter.
A Gray-Box Stability Analysis Mechanism for Power Electronic Converters
Apr 15, 2024This paper proposes a gray-box stability analysis mechanism based on data-driven dynamic mode decomposition (DMD) for commercial grid-tied power electronics converters with limited information on its control parameters and topology. By fusing the underlying physical constraints of the state equations into data snapshots, the system dynamic state matrix and input matrix are simultaneously approximated to identify the dominant system dynamic modes and eigenvalues using the DMD with control (DMDc) algorithm. While retaining the advantages of eliminating the need for intrinsic controller information, the proposed gray-box method establishes higher accuracy and interpretable outcomes over the conventional DMD method. Finally, under experimental conditions of a low-frequency oscillation scenario in electrified railways featuring a single-phase converter, the proposed gray-box DMDc is verified to identify the dominant eigenvalues more accurately.
Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
Jan 10, 2024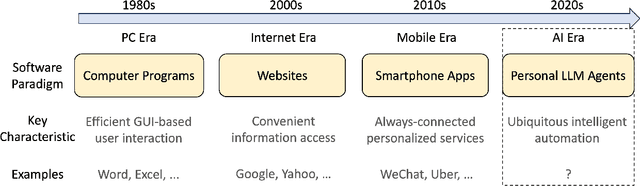
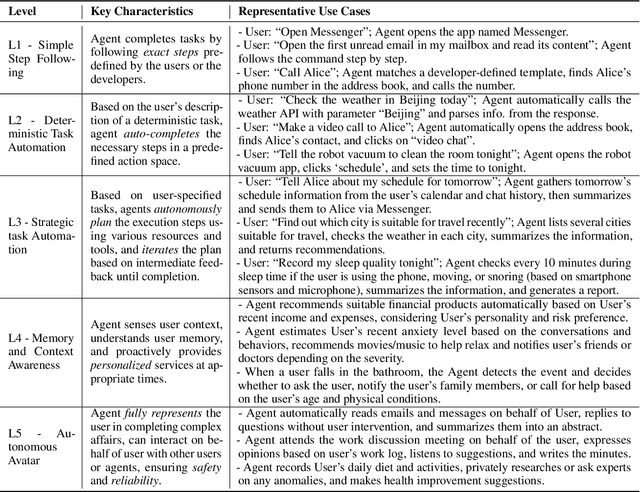
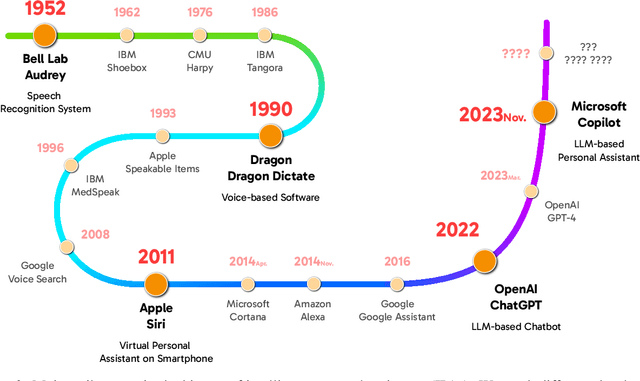
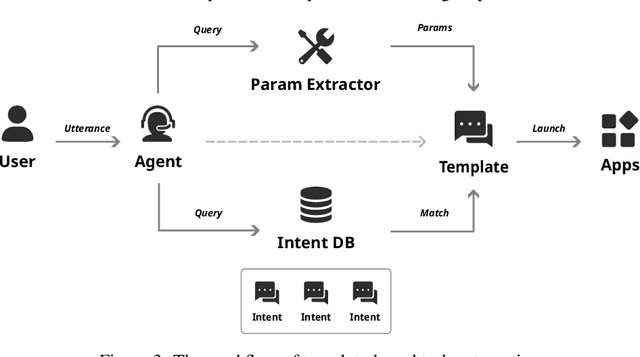
Since the advent of personal computing devices, intelligent personal assistants (IPAs) have been one of the key technologies that researchers and engineers have focused on, aiming to help users efficiently obtain information and execute tasks, and provide users with more intelligent, convenient, and rich interaction experiences. With the development of smartphones and IoT, computing and sensing devices have become ubiquitous, greatly expanding the boundaries of IPAs. However, due to the lack of capabilities such as user intent understanding, task planning, tool using, and personal data management etc., existing IPAs still have limited practicality and scalability. Recently, the emergence of foundation models, represented by large language models (LLMs), brings new opportunities for the development of IPAs. With the powerful semantic understanding and reasoning capabilities, LLM can enable intelligent agents to solve complex problems autonomously. In this paper, we focus on Personal LLM Agents, which are LLM-based agents that are deeply integrated with personal data and personal devices and used for personal assistance. We envision that Personal LLM Agents will become a major software paradigm for end-users in the upcoming era. To realize this vision, we take the first step to discuss several important questions about Personal LLM Agents, including their architecture, capability, efficiency and security. We start by summarizing the key components and design choices in the architecture of Personal LLM Agents, followed by an in-depth analysis of the opinions collected from domain experts. Next, we discuss several key challenges to achieve intelligent, efficient and secure Personal LLM Agents, followed by a comprehensive survey of representative solutions to address these challenges.
ACT: Empowering Decision Transformer with Dynamic Programming via Advantage Conditioning
Sep 12, 2023Decision Transformer (DT), which employs expressive sequence modeling techniques to perform action generation, has emerged as a promising approach to offline policy optimization. However, DT generates actions conditioned on a desired future return, which is known to bear some weaknesses such as the susceptibility to environmental stochasticity. To overcome DT's weaknesses, we propose to empower DT with dynamic programming. Our method comprises three steps. First, we employ in-sample value iteration to obtain approximated value functions, which involves dynamic programming over the MDP structure. Second, we evaluate action quality in context with estimated advantages. We introduce two types of advantage estimators, IAE and GAE, which are suitable for different tasks. Third, we train an Advantage-Conditioned Transformer (ACT) to generate actions conditioned on the estimated advantages. Finally, during testing, ACT generates actions conditioned on a desired advantage. Our evaluation results validate that, by leveraging the power of dynamic programming, ACT demonstrates effective trajectory stitching and robust action generation in spite of the environmental stochasticity, outperforming baseline methods across various benchmarks. Additionally, we conduct an in-depth analysis of ACT's various design choices through ablation studies.