 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.
Generative Model for Heterogeneous Inference
Apr 26, 2018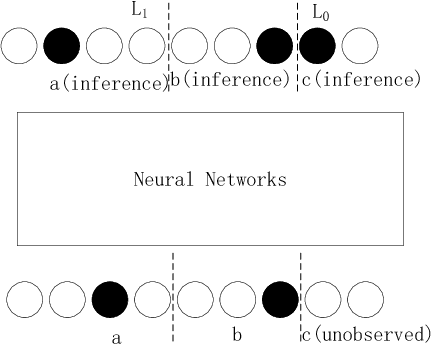
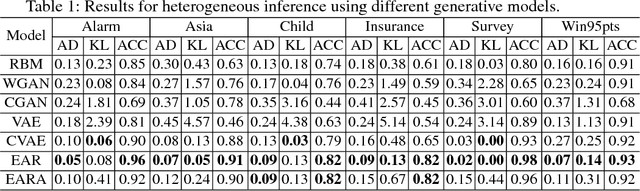
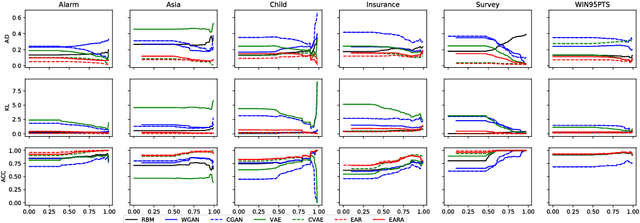
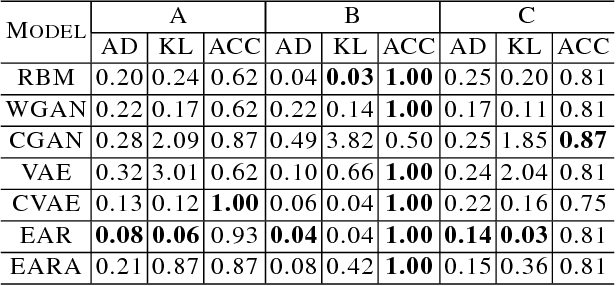
Generative models (GMs) such as Generative Adversary Network (GAN) and Variational Auto-Encoder (VAE) have thrived these years and achieved high quality results in generating new samples. Especially in Computer Vision, GMs have been used in image inpainting, denoising and completion, which can be treated as the inference from observed pixels to corrupted pixels. However, images are hierarchically structured which are quite different from many real-world inference scenarios with non-hierarchical features. These inference scenarios contain heterogeneous stochastic variables and irregular mutual dependences. Traditionally they are modeled by Bayesian Network (BN). However, the learning and inference of BN model are NP-hard thus the number of stochastic variables in BN is highly constrained. In this paper, we adapt typical GMs to enable heterogeneous learning and inference in polynomial time.We also propose an extended autoregressive (EAR) model and an EAR with adversary loss (EARA) model and give theoretical results on their effectiveness. Experiments on several BN datasets show that our proposed EAR model achieves the best performance in most cases compared to other GMs. Except for black box analysis, we've also done a serial of experiments on Markov border inference of GMs for white box analysis and give theoretical results.
Using Deep Neural Network Approximate Bayesian Network
Jan 11, 2018



We present a new method to approximate posterior probabilities of Bayesian Network using Deep Neural Network. Experiment results on several public Bayesian Network datasets shows that Deep Neural Network is capable of learning joint probability distri- bution of Bayesian Network by learning from a few observation and posterior probability distribution pairs with high accuracy. Compared with traditional approximate method likelihood weighting sampling algorithm, our method is much faster and gains higher accuracy in medium sized Bayesian Network. Another advantage of our method is that our method can be parallelled much easier in GPU without extra effort. We also ex- plored the connection between the accuracy of our model and the number of training examples. The result shows that our model saturate as the number of training examples grow and we don't need many training examples to get reasonably good result. Another contribution of our work is that we have shown discriminative model like Deep Neural Network can approximate generative model like Bayesian Network.