 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Reality-Virtuality Interconnections in Urban Digital Twins for Superior Intelligent Road Inspection
Dec 23, 2024



Road inspection is essential for ensuring road maintenance and traffic safety, as road defects gradually emerge and compromise road functionality. Traditional methods, which rely on manual evaluations, are labor-intensive, costly, and time-consuming. Although data-driven approaches are gaining traction, the scarcity and spatial sparsity of road defects in the real world pose significant challenges in acquiring high-quality datasets. Existing simulators designed to generate detailed synthetic driving scenes, however, lack models for road defects. Furthermore, advanced driving tasks involving interactions with road surfaces, such as planning and control in defective areas, remain underexplored. To address these limitations, we propose a system based on Urban Digital Twin (UDT) technology for intelligent road inspection. First, hierarchical road models are constructed from real-world driving data, creating highly detailed representations of road defect structures and surface elevations. Next, digital road twins are generated to create simulation environments for comprehensive analysis and evaluation. These scenarios are subsequently imported into a simulator to enable both data acquisition and physical simulation. Experimental results demonstrate that driving tasks, including perception and decision-making, can be significantly improved using the high-fidelity road defect scenes generated by our system.
These Maps Are Made by Propagation: Adapting Deep Stereo Networks to Road Scenarios with Decisive Disparity Diffusion
Nov 06, 2024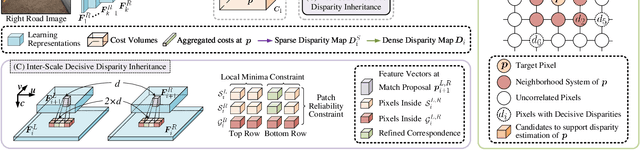
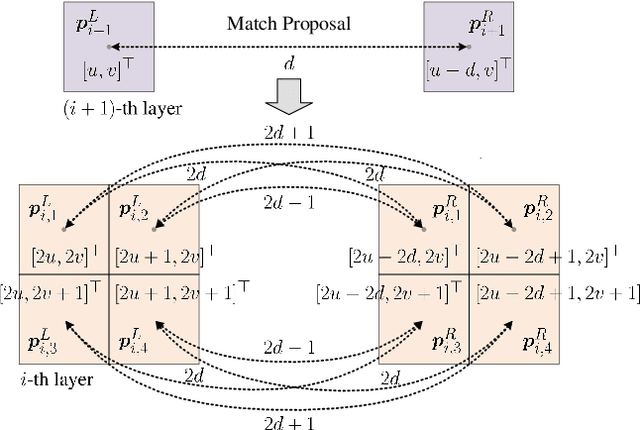
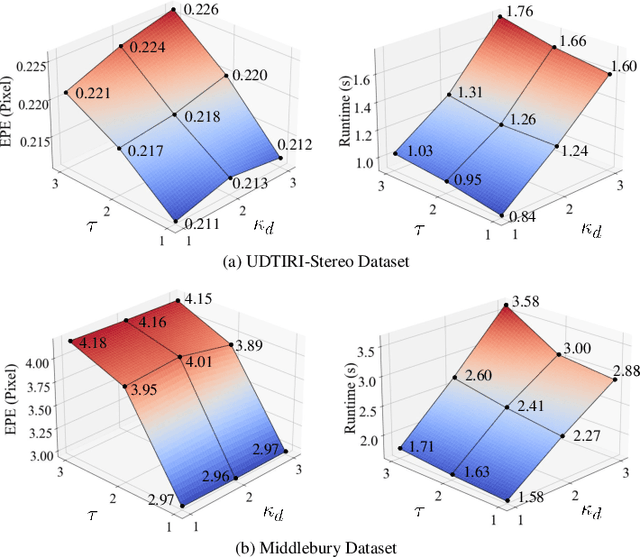
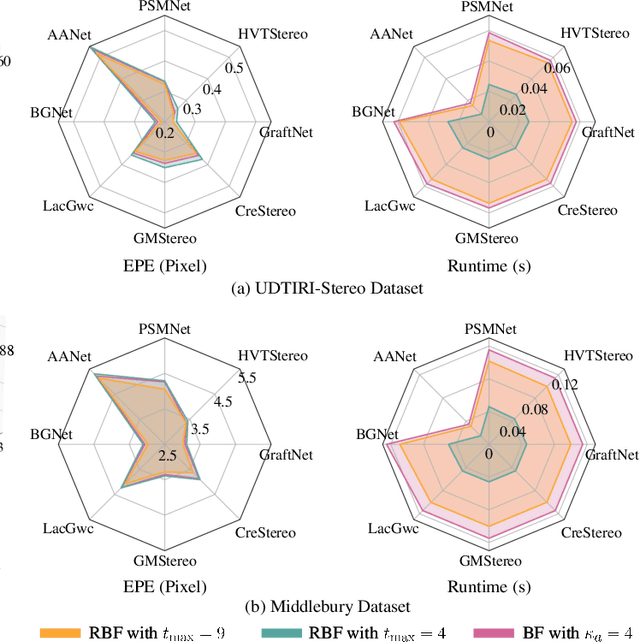
Stereo matching has emerged as a cost-effective solution for road surface 3D reconstruction, garnering significant attention towards improving both computational efficiency and accuracy. This article introduces decisive disparity diffusion (D3Stereo), marking the first exploration of dense deep feature matching that adapts pre-trained deep convolutional neural networks (DCNNs) to previously unseen road scenarios. A pyramid of cost volumes is initially created using various levels of learned representations. Subsequently, a novel recursive bilateral filtering algorithm is employed to aggregate these costs. A key innovation of D3Stereo lies in its alternating decisive disparity diffusion strategy, wherein intra-scale diffusion is employed to complete sparse disparity images, while inter-scale inheritance provides valuable prior information for higher resolutions. Extensive experiments conducted on our created UDTIRI-Stereo and Stereo-Road datasets underscore the effectiveness of D3Stereo strategy in adapting pre-trained DCNNs and its superior performance compared to all other explicit programming-based algorithms designed specifically for road surface 3D reconstruction. Additional experiments conducted on the Middlebury dataset with backbone DCNNs pre-trained on the ImageNet database further validate the versatility of D3Stereo strategy in tackling general stereo matching problems.
V-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.
Online,Target-Free LiDAR-Camera Extrinsic Calibration via Cross-Modal Mask Matching
Apr 28, 2024
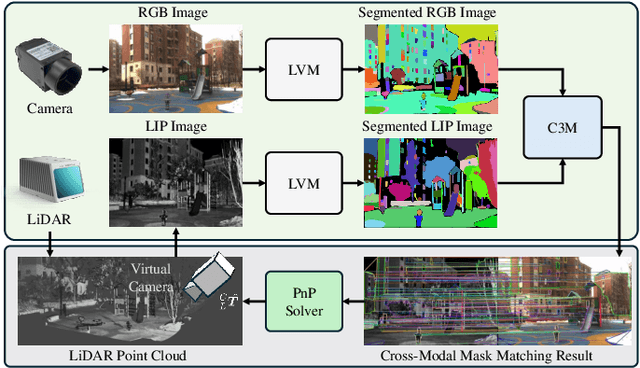
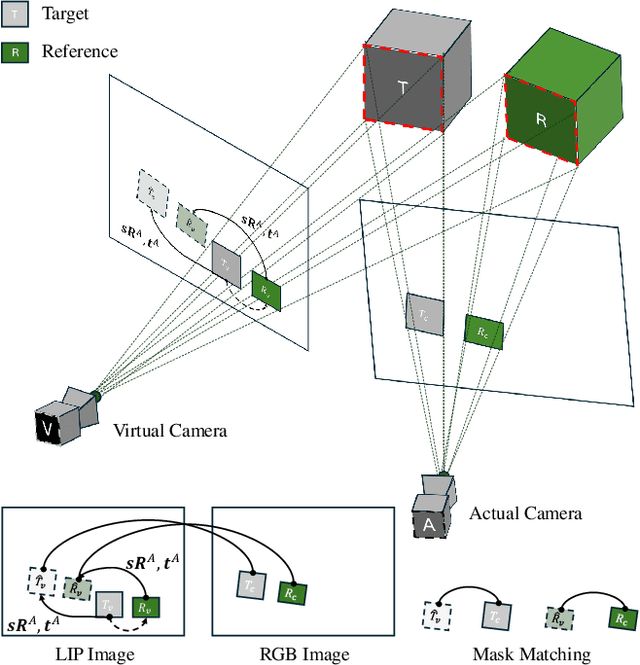
LiDAR-camera extrinsic calibration (LCEC) is crucial for data fusion in intelligent vehicles. Offline, target-based approaches have long been the preferred choice in this field. However, they often demonstrate poor adaptability to real-world environments. This is largely because extrinsic parameters may change significantly due to moderate shocks or during extended operations in environments with vibrations. In contrast, online, target-free approaches provide greater adaptability yet typically lack robustness, primarily due to the challenges in cross-modal feature matching. Therefore, in this article, we unleash the full potential of large vision models (LVMs), which are emerging as a significant trend in the fields of computer vision and robotics, especially for embodied artificial intelligence, to achieve robust and accurate online, target-free LCEC across a variety of challenging scenarios. Our main contributions are threefold: we introduce a novel framework known as MIAS-LCEC, provide an open-source versatile calibration toolbox with an interactive visualization interface, and publish three real-world datasets captured from various indoor and outdoor environments. The cornerstone of our framework and toolbox is the cross-modal mask matching (C3M) algorithm, developed based on a state-of-the-art (SoTA) LVM and capable of generating sufficient and reliable matches. Extensive experiments conducted on these real-world datasets demonstrate the robustness of our approach and its superior performance compared to SoTA methods, particularly for the solid-state LiDARs with super-wide fields of view.
Dive Deeper into Rectifying Homography for Stereo Camera Online Self-Calibration
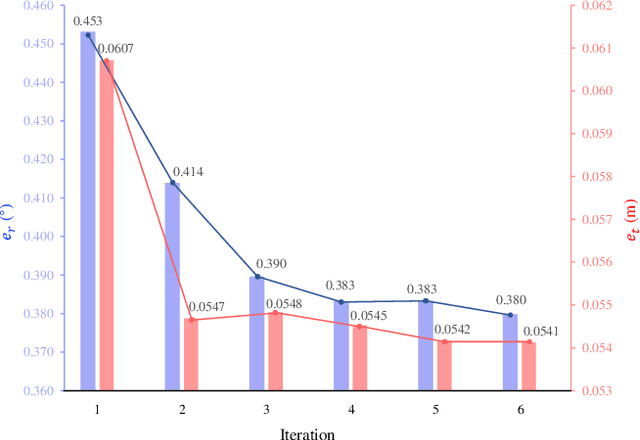
Sep 21, 2023Accurate estimation of stereo camera extrinsic parameters is the key to guarantee the performance of stereo matching algorithms. In prior arts, the online self-calibration of stereo cameras has commonly been formulated as a specialized visual odometry problem, without taking into account the principles of stereo rectification. In this paper, we first delve deeply into the concept of rectifying homography, which serves as the cornerstone for the development of our novel stereo camera online self-calibration algorithm, for cases where only a single pair of images is available. Furthermore, we introduce a simple yet effective solution for global optimum extrinsic parameter estimation in the presence of stereo video sequences. Additionally, we emphasize the impracticality of using three Euler angles and three components in the translation vectors for performance quantification. Instead, we introduce four new evaluation metrics to quantify the robustness and accuracy of extrinsic parameter estimation, applicable to both single-pair and multi-pair cases. Extensive experiments conducted across indoor and outdoor environments using various experimental setups validate the effectiveness of our proposed algorithm. The comprehensive evaluation results demonstrate its superior performance in comparison to the baseline algorithm. Our source code, demo video, and supplement are publicly available at mias.group/StereoCalibrator.
RoadFormer: Duplex Transformer for RGB-Normal Semantic Road Scene Parsing
Sep 19, 2023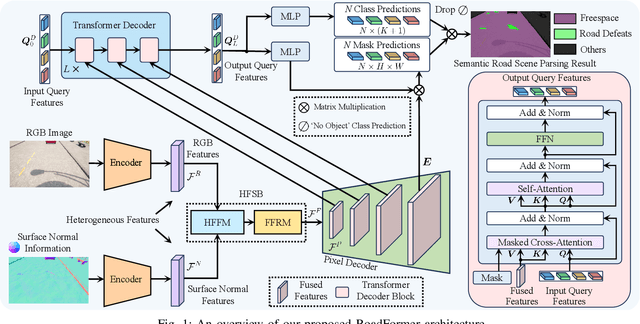
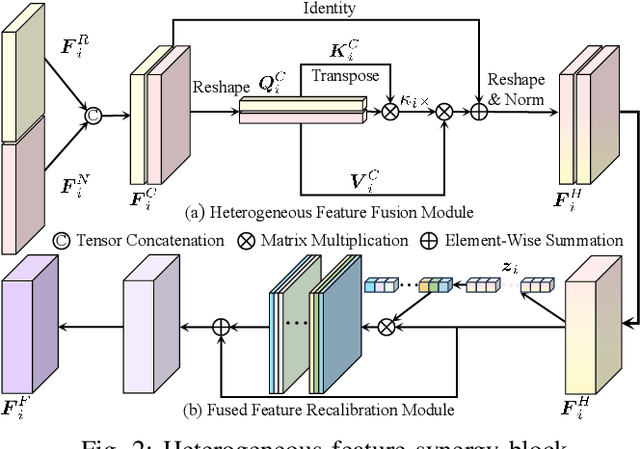
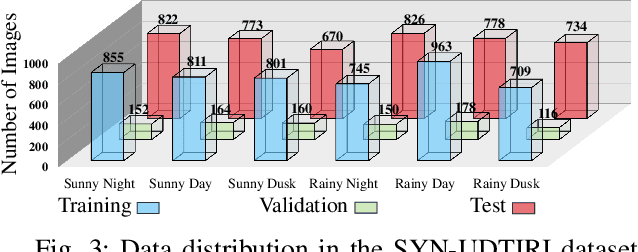

The recent advancements in deep convolutional neural networks have shown significant promise in the domain of road scene parsing. Nevertheless, the existing works focus primarily on freespace detection, with little attention given to hazardous road defects that could compromise both driving safety and comfort. In this paper, we introduce RoadFormer, a novel Transformer-based data-fusion network developed for road scene parsing. RoadFormer utilizes a duplex encoder architecture to extract heterogeneous features from both RGB images and surface normal information. The encoded features are subsequently fed into a novel heterogeneous feature synergy block for effective feature fusion and recalibration. The pixel decoder then learns multi-scale long-range dependencies from the fused and recalibrated heterogeneous features, which are subsequently processed by a Transformer decoder to produce the final semantic prediction. Additionally, we release SYN-UDTIRI, the first large-scale road scene parsing dataset that contains over 10,407 RGB images, dense depth images, and the corresponding pixel-level annotations for both freespace and road defects of different shapes and sizes. Extensive experimental evaluations conducted on our SYN-UDTIRI dataset, as well as on three public datasets, including KITTI road, CityScapes, and ORFD, demonstrate that RoadFormer outperforms all other state-of-the-art networks for road scene parsing. Specifically, RoadFormer ranks first on the KITTI road benchmark. Our source code, created dataset, and demo video are publicly available at mias.group/RoadFormer.
SemanticCAP: Chromatin Accessibility Prediction Enhanced by Features Learning from a Language Model
Apr 06, 2022
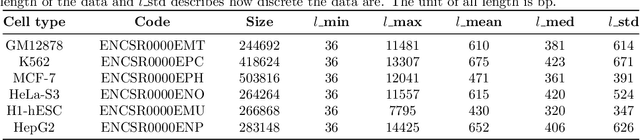
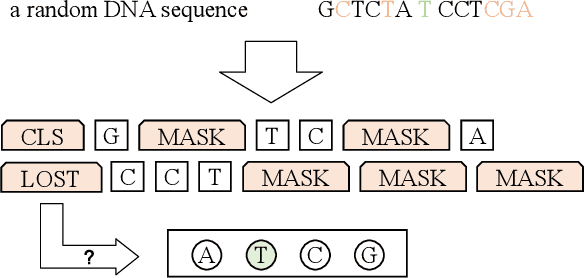
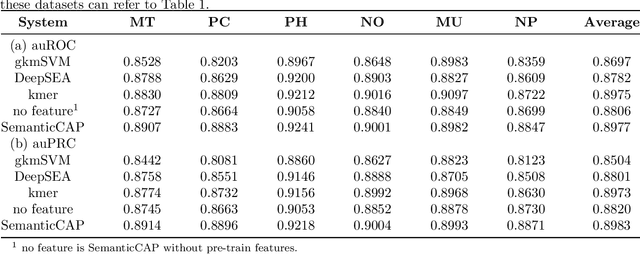
A large number of inorganic and organic compounds are able to bind DNA and form complexes, among which drug-related molecules are important. Chromatin accessibility changes not only directly affects drug-DNA interactions, but also promote or inhibit the expression of critical genes associated with drug resistance by affecting the DNA binding capacity of TFs and transcriptional regulators. However, Biological experimental techniques for measuring it are expensive and time consuming. In recent years, several kinds of computational methods have been proposed to identify accessible regions of the genome. Existing computational models mostly ignore the contextual information of bases in gene sequences. To address these issues, we proposed a new solution named SemanticCAP. It introduces a gene language model which models the context of gene sequences, thus being able to provide an effective representation of a certain site in gene sequences. Basically, we merge the features provided by the gene language model into our chromatin accessibility model. During the process, we designed some methods to make feature fusion smoother. Compared with other systems under public benchmarks, our model proved to have better performance.
TrajGen: Generating Realistic and Diverse Trajectories with Reactive and Feasible Agent Behaviors for Autonomous Driving
Mar 31, 2022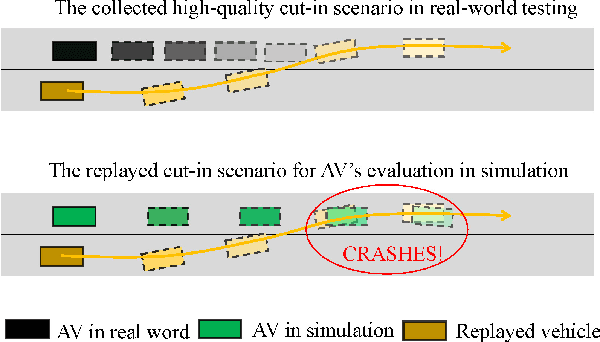
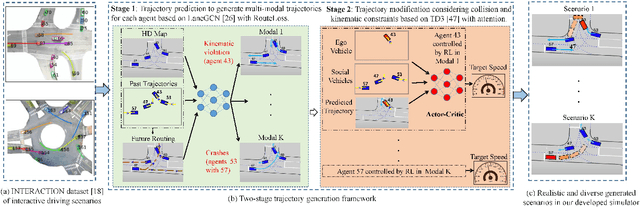
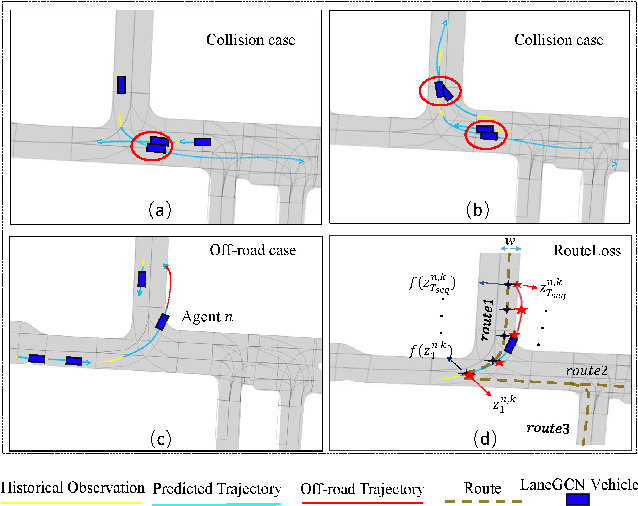
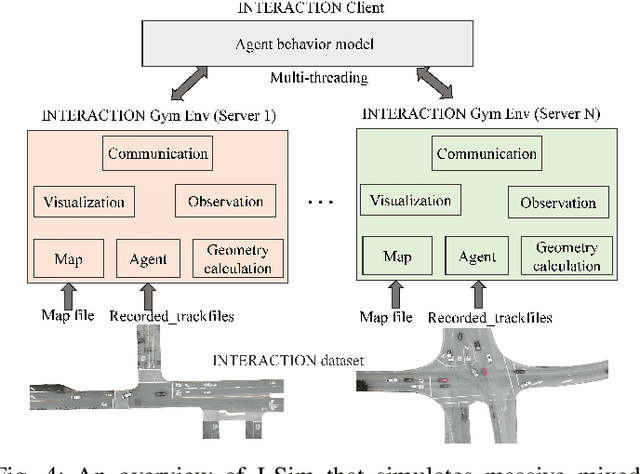
Realistic and diverse simulation scenarios with reactive and feasible agent behaviors can be used for validation and verification of self-driving system performance without relying on expensive and time-consuming real-world testing. Existing simulators rely on heuristic-based behavior models for background vehicles, which cannot capture the complex interactive behaviors in real-world scenarios. To bridge the gap between simulation and the real world, we propose TrajGen, a two-stage trajectory generation framework, which can capture more realistic behaviors directly from human demonstration. In particular, TrajGen consists of the multi-modal trajectory prediction stage and the reinforcement learning based trajectory modification stage. In the first stage, we propose a novel auxiliary RouteLoss for the trajectory prediction model to generate multi-modal diverse trajectories in the drivable area. In the second stage, reinforcement learning is used to track the predicted trajectories while avoiding collisions, which can improve the feasibility of generated trajectories. In addition, we develop a data-driven simulator I-Sim that can be used to train reinforcement learning models in parallel based on naturalistic driving data. The vehicle model in I-Sim can guarantee that the generated trajectories by TrajGen satisfy vehicle kinematic constraints. Finally, we give comprehensive metrics to evaluate generated trajectories for simulation scenarios, which shows that TrajGen outperforms either trajectory prediction or inverse reinforcement learning in terms of fidelity, reactivity, feasibility, and diversity.
Collaboration of Experts: Achieving 80% Top-1 Accuracy on ImageNet with 100M FLOPs
Jul 08, 2021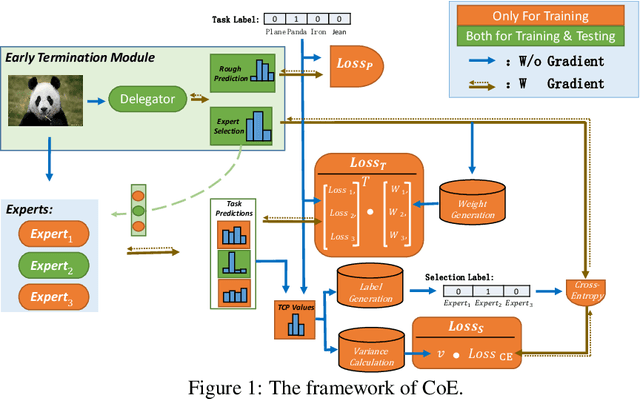
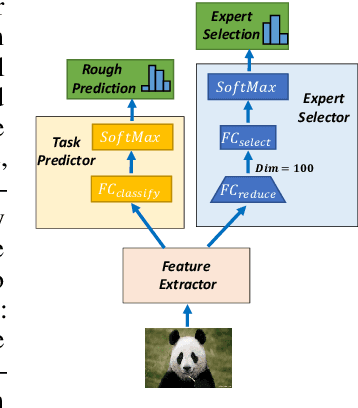
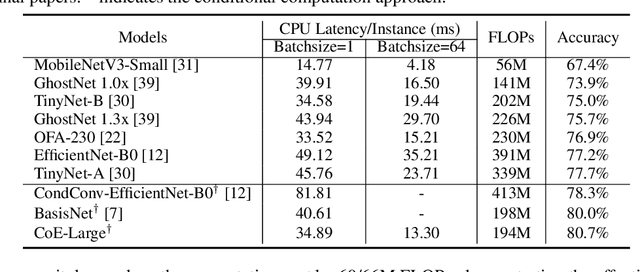
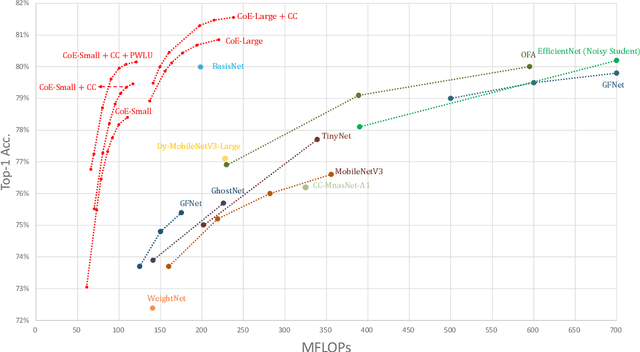
In this paper, we propose a Collaboration of Experts (CoE) framework to pool together the expertise of multiple networks towards a common aim. Each expert is an individual network with expertise on a unique portion of the dataset, which enhances the collective capacity. Given a sample, an expert is selected by the delegator, which simultaneously outputs a rough prediction to support early termination. To fulfill this framework, we propose three modules to impel each model to play its role, namely weight generation module (WGM), label generation module (LGM) and variance calculation module (VCM). Our method achieves the state-of-the-art performance on ImageNet, 80.7% top-1 accuracy with 194M FLOPs. Combined with PWLU activation function and CondConv, CoE further achieves the accuracy of 80.0% with only 100M FLOPs for the first time. More importantly, our method is hardware friendly and achieves a 3-6x speedup compared with some existing conditional computation approaches.
AutoBSS: An Efficient Algorithm for Block Stacking Style Search
Oct 20, 2020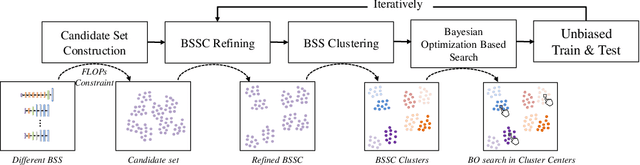
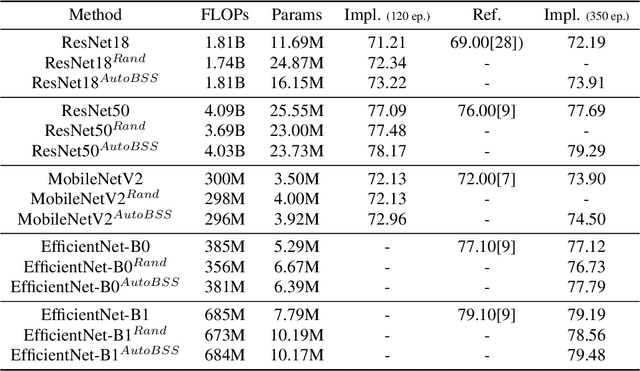
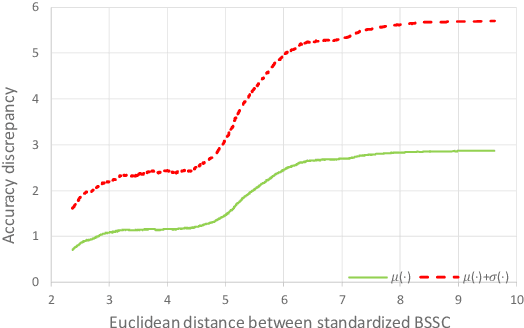
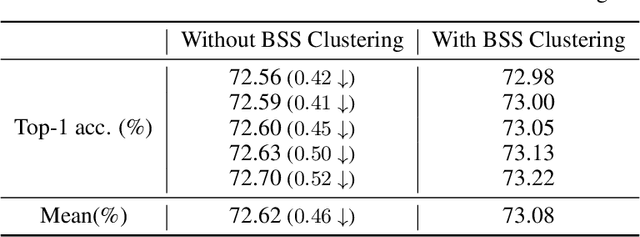
Neural network architecture design mostly focuses on the new convolutional operator or special topological structure of network block, little attention is drawn to the configuration of stacking each block, called Block Stacking Style (BSS). Recent studies show that BSS may also have an unneglectable impact on networks, thus we design an efficient algorithm to search it automatically. The proposed method, AutoBSS, is a novel AutoML algorithm based on Bayesian optimization by iteratively refining and clustering Block Stacking Style Code (BSSC), which can find optimal BSS in a few trials without biased evaluation. On ImageNet classification task, ResNet50/MobileNetV2/EfficientNet-B0 with our searched BSS achieve 79.29%/74.5%/77.79%, which outperform the original baselines by a large margin. More importantly, experimental results on model compression, object detection and instance segmentation show the strong generalizability of the proposed AutoBSS, and further verify the unneglectable impact of BSS on neural networks.