 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISA: A Visual Information Strengthened Audio-Reasoning System for the Interspeech 2026 ARC Agent Track
Jun 05, 2026Audio reasoning requires multi-step, evidence-grounded inference over temporally dynamic and acoustically mixed signals, exceeding conventional perception tasks such as ASR or captioning. We present VISA, our submission to the Interspeech 2026 Audio Reasoning Challenge (Agent Track), evaluated via the MMAR Rubrics for correctness and reasoning quality. Under a "LALM as a Tool" paradigm, VISA strengthens large audio language models with auxiliary multi-modal evidence while avoiding heavy orchestration. The system integrates three components: multi-modal feature extraction for complementary audio and acoustic-visual clues, model-voting inference with consistency checking for stable predictions, and fine-grained category-aware routing to resolve disagreements and select rubric-aligned reasoning chains. On the official Agent Track leaderboard, VISA ranks 2nd overall with a 66.23% Rubrics score. It also achieves 77.40% Accuracy, the highest among all systems listed across both the Single Model and Agent tracks.
MMAE: A Massive Multitask Audio Editing Benchmark
Jun 05, 2026We introduce MMAE, a Massive Multitask Audio Editing benchmark, serving as the first comprehensive evaluation testbed designed for general-purpose instruction-based audio editing. Spurred by the shift toward intelligent creation, interactive editing has rapidly expanded from visual domains, pioneered by models like Nano-banana 2 for images and Gemini-Omni for video, into audio. However, the current evaluation infrastructure lags severely, remaining highly fragmented and restricted to specific subdomains or basic operations. Unlike existing benchmarks that are limited in scope, MMAE extends to a broad spectrum of real-world scenarios, encompassing 7 distinct audio modalities, including sound, speech, music, and their mixtures. Furthermore, we establish a comprehensive taxonomy spanning 6 levels of task complexity, from basic modifications to multi-hop reasoning and multi-round editing, 2 levels of granularity, and 8 distinct operation types. Meticulously curated through human-agent collaboration, MMAE comprises 2,000 high-fidelity samples paired with a pioneering rubric-based evaluation framework. By decomposing free-form tasks into 17,741 verifiable criteria, this robust rubric-based paradigm enables a precise, multi-dimensional assessment of both instruction following and context consistency. Our extensive evaluation of leading models reveals that current systems remain far from achieving reliable edits. Strikingly, the Exact Match Rate (EMR) consistently falls below 5% and plummets to an absolute 0% in complex, mixed-modality tasks, exposing critical bottlenecks in precise execution and structural robustness. We hope MMAE will serve as a catalyst for future advances in the intelligent creation community, providing a clear diagnostic roadmap and establishing a standardized, long-lasting evaluation paradigm for next-generation audio editing systems.
A Unified and Reproducible Experimentation Framework for Speech Understanding
May 29, 2026Speech foundation models and Speech LLMs have advanced speech understanding, yet deployment-oriented model selection is hindered by non-comparable evaluations caused by mismatched post-processing, and by training results that are hard to reproduce across data scales and pipelines. We present SURE, a unified experimentation framework that standardizes prediction formats, normalization, and scoring. SURE evaluates strong systems across paradigms, from conventional pipelines to Speech LLMs, on representative tasks under realistic acoustic and linguistic stressors. Beyond evaluation, SURE introduces an agent-assisted training conversion flow that maps paper and code into versioned, runnable training pipelines under a unified protocol on matched open-data subsets. Overall, SURE improves comparability and reproducibility for deployment-oriented evaluation.
Audio-Mind: An Auditable Agentic Framework for Audio Understanding
May 27, 2026Audio agents extend large audio-language models (LALMs) by decomposing audio questions into tool calls, intermediate evidence, and iterative reasoning steps. However, as LALMs become stronger, the key challenge shifts from enabling tool use to determining when agentic evidence acquisition genuinely benefits audio understanding. We propose Audio-Mind, an auditable and pluggable framework for conditional evidence acquisition in audio understanding. Audio-Mind dynamically combines a strong frontend with planner-guided tool use, preserving frontend judgment when initial evidence is sufficient while acquiring bounded external evidence for questions with unresolved evidence gaps. Experiments on MMAR and MSU-Bench show that Audio-Mind outperforms prior audio-agent baselines, reaching 80.4% accuracy on MMAR and 82.8% accuracy on MSU-Bench. A matched-backbone comparison highlights why this design matters: under strong audio frontends, agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment. Beyond accuracy, Audio-Mind produces higher-quality, auditable reasoning traces that expose uncertainty, tool evidence, and answer rationales, offering a potential basis for more reliable audio-QA annotation and error analysis.
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
UltraVoice: Scaling Fine-Grained Style-Controlled Speech Conversations for Spoken Dialogue Models
Oct 26, 2025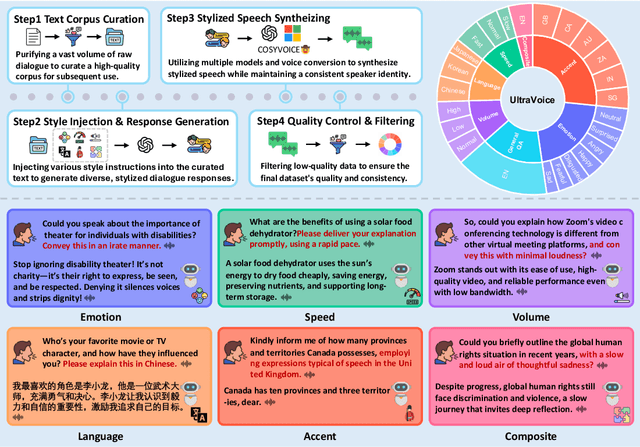
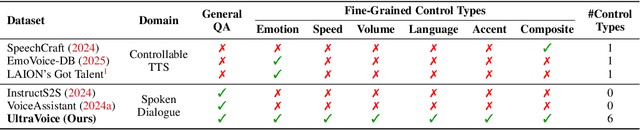
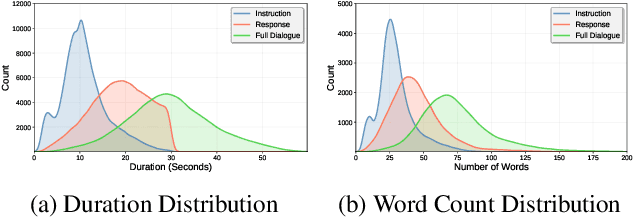

Spoken dialogue models currently lack the ability for fine-grained speech style control, a critical capability for human-like interaction that is often overlooked in favor of purely functional capabilities like reasoning and question answering. To address this limitation, we introduce UltraVoice, the first large-scale speech dialogue dataset engineered for multiple fine-grained speech style control. Encompassing over 830 hours of speech dialogues, UltraVoice provides instructions across six key speech stylistic dimensions: emotion, speed, volume, accent, language, and composite styles. Fine-tuning leading models such as SLAM-Omni and VocalNet on UltraVoice significantly enhances their fine-grained speech stylistic controllability without degrading core conversational abilities. Specifically, our fine-tuned models achieve improvements of 29.12-42.33% in Mean Opinion Score (MOS) and 14.61-40.09 percentage points in Instruction Following Rate (IFR) on multi-dimensional control tasks designed in the UltraVoice. Moreover, on the URO-Bench benchmark, our fine-tuned models demonstrate substantial gains in core understanding, reasoning, and conversational abilities, with average improvements of +10.84% on the Basic setting and +7.87% on the Pro setting. Furthermore, the dataset's utility extends to training controllable Text-to-Speech (TTS) models, underscoring its high quality and broad applicability for expressive speech synthesis. The complete dataset and model checkpoints are available at: https://github.com/bigai-nlco/UltraVoice.
Causal Graph Guided Steering of LLM Values via Prompts and Sparse Autoencoders
Dec 31, 2024As large language models (LLMs) become increasingly integrated into critical applications, aligning their behavior with human values presents significant challenges. Current methods, such as Reinforcement Learning from Human Feedback (RLHF), often focus on a limited set of values and can be resource-intensive. Furthermore, the correlation between values has been largely overlooked and remains underutilized. Our framework addresses this limitation by mining a causal graph that elucidates the implicit relationships among various values within the LLMs. Leveraging the causal graph, we implement two lightweight mechanisms for value steering: prompt template steering and Sparse Autoencoder feature steering, and analyze the effects of altering one value dimension on others. Extensive experiments conducted on Gemma-2B-IT and Llama3-8B-IT demonstrate the effectiveness and controllability of our steering methods.
V-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.