 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
OPT-BENCH: Evaluating LLM Agent on Large-Scale Search Spaces Optimization Problems
Jun 12, 2025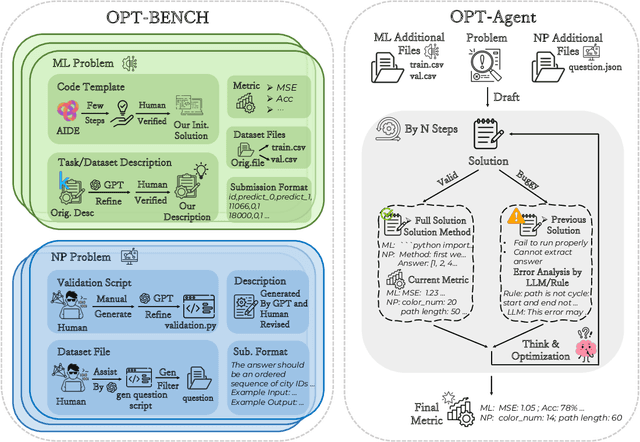


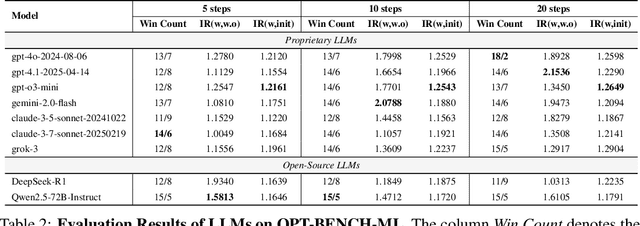
Large Language Models (LLMs) have shown remarkable capabilities in solving diverse tasks. However, their proficiency in iteratively optimizing complex solutions through learning from previous feedback remains insufficiently explored. To bridge this gap, we present OPT-BENCH, a comprehensive benchmark designed to evaluate LLM agents on large-scale search space optimization problems. OPT-BENCH includes 20 real-world machine learning tasks sourced from Kaggle and 10 classical NP problems, offering a diverse and challenging environment for assessing LLM agents on iterative reasoning and solution refinement. To enable rigorous evaluation, we introduce OPT-Agent, an end-to-end optimization framework that emulates human reasoning when tackling complex problems by generating, validating, and iteratively improving solutions through leveraging historical feedback. Through extensive experiments on 9 state-of-the-art LLMs from 6 model families, we analyze the effects of optimization iterations, temperature settings, and model architectures on solution quality and convergence. Our results demonstrate that incorporating historical context significantly enhances optimization performance across both ML and NP tasks. All datasets, code, and evaluation tools are open-sourced to promote further research in advancing LLM-driven optimization and iterative reasoning. Project page: \href{https://github.com/OliverLeeXZ/OPT-BENCH}{https://github.com/OliverLeeXZ/OPT-BENCH}.
Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLM
Mar 19, 2025



Creativity is a fundamental aspect of intelligence, involving the ability to generate novel and appropriate solutions across diverse contexts. While Large Language Models (LLMs) have been extensively evaluated for their creative capabilities, the assessment of Multimodal Large Language Models (MLLMs) in this domain remains largely unexplored. To address this gap, we introduce Creation-MMBench, a multimodal benchmark specifically designed to evaluate the creative capabilities of MLLMs in real-world, image-based tasks. The benchmark comprises 765 test cases spanning 51 fine-grained tasks. To ensure rigorous evaluation, we define instance-specific evaluation criteria for each test case, guiding the assessment of both general response quality and factual consistency with visual inputs. Experimental results reveal that current open-source MLLMs significantly underperform compared to proprietary models in creative tasks. Furthermore, our analysis demonstrates that visual fine-tuning can negatively impact the base LLM's creative abilities. Creation-MMBench provides valuable insights for advancing MLLM creativity and establishes a foundation for future improvements in multimodal generative intelligence. Full data and evaluation code is released on https://github.com/open-compass/Creation-MMBench.
OmniAlign-V: Towards Enhanced Alignment of MLLMs with Human Preference
Feb 25, 2025Recent advancements in open-source multi-modal large language models (MLLMs) have primarily focused on enhancing foundational capabilities, leaving a significant gap in human preference alignment. This paper introduces OmniAlign-V, a comprehensive dataset of 200K high-quality training samples featuring diverse images, complex questions, and varied response formats to improve MLLMs' alignment with human preferences. We also present MM-AlignBench, a human-annotated benchmark specifically designed to evaluate MLLMs' alignment with human values. Experimental results show that finetuning MLLMs with OmniAlign-V, using Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO), significantly enhances human preference alignment while maintaining or enhancing performance on standard VQA benchmarks, preserving their fundamental capabilities. Our datasets, benchmark, code and checkpoints have been released at https://github.com/PhoenixZ810/OmniAlign-V.
MME-Survey: A Comprehensive Survey on Evaluation of Multimodal LLMs
Nov 22, 2024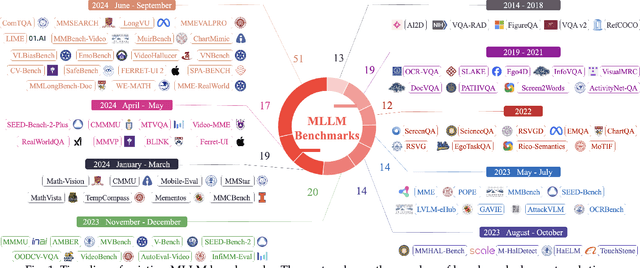
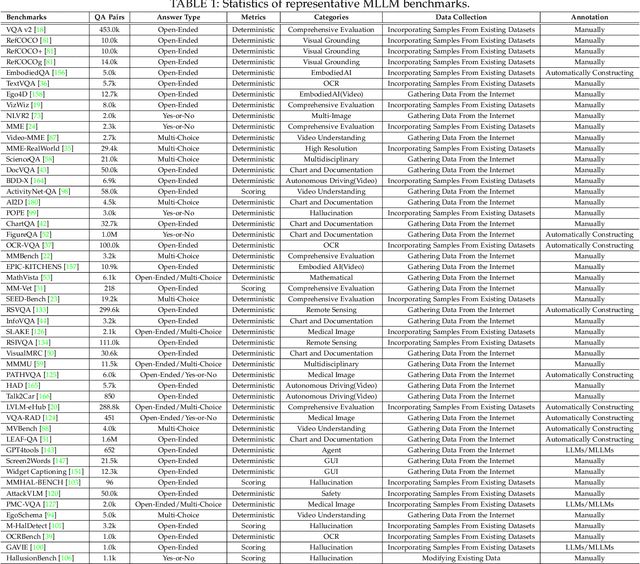
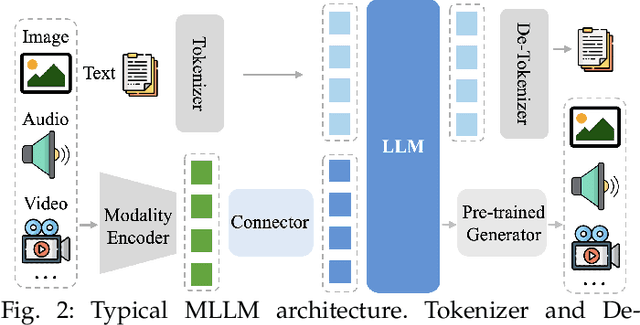
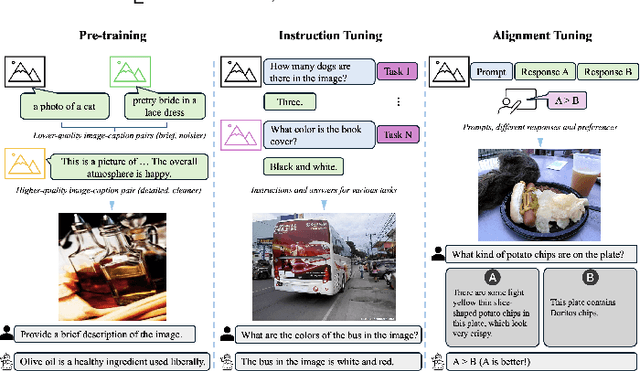
As a prominent direction of Artificial General Intelligence (AGI), Multimodal Large Language Models (MLLMs) have garnered increased attention from both industry and academia. Building upon pre-trained LLMs, this family of models further develops multimodal perception and reasoning capabilities that are impressive, such as writing code given a flow chart or creating stories based on an image. In the development process, evaluation is critical since it provides intuitive feedback and guidance on improving models. Distinct from the traditional train-eval-test paradigm that only favors a single task like image classification, the versatility of MLLMs has spurred the rise of various new benchmarks and evaluation methods. In this paper, we aim to present a comprehensive survey of MLLM evaluation, discussing four key aspects: 1) the summarised benchmarks types divided by the evaluation capabilities, including foundation capabilities, model self-analysis, and extented applications; 2) the typical process of benchmark counstruction, consisting of data collection, annotation, and precautions; 3) the systematic evaluation manner composed of judge, metric, and toolkit; 4) the outlook for the next benchmark. This work aims to offer researchers an easy grasp of how to effectively evaluate MLLMs according to different needs and to inspire better evaluation methods, thereby driving the progress of MLLM research.
V-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.
ProSA: Assessing and Understanding the Prompt Sensitivity of LLMs
Oct 16, 2024



Large language models (LLMs) have demonstrated impressive capabilities across various tasks, but their performance is highly sensitive to the prompts utilized. This variability poses challenges for accurate assessment and user satisfaction. Current research frequently overlooks instance-level prompt variations and their implications on subjective evaluations. To address these shortcomings, we introduce ProSA, a framework designed to evaluate and comprehend prompt sensitivity in LLMs. ProSA incorporates a novel sensitivity metric, PromptSensiScore, and leverages decoding confidence to elucidate underlying mechanisms. Our extensive study, spanning multiple tasks, uncovers that prompt sensitivity fluctuates across datasets and models, with larger models exhibiting enhanced robustness. We observe that few-shot examples can alleviate this sensitivity issue, and subjective evaluations are also susceptible to prompt sensitivities, particularly in complex, reasoning-oriented tasks. Furthermore, our findings indicate that higher model confidence correlates with increased prompt robustness. We believe this work will serve as a helpful tool in studying prompt sensitivity of LLMs. The project is released at: https://github.com/open-compass/ProSA .
MuMA-ToM: Multi-modal Multi-Agent Theory of Mind
Aug 22, 2024Understanding people's social interactions in complex real-world scenarios often relies on intricate mental reasoning. To truly understand how and why people interact with one another, we must infer the underlying mental states that give rise to the social interactions, i.e., Theory of Mind reasoning in multi-agent interactions. Additionally, social interactions are often multi-modal -- we can watch people's actions, hear their conversations, and/or read about their past behaviors. For AI systems to successfully and safely interact with people in real-world environments, they also need to understand people's mental states as well as their inferences about each other's mental states based on multi-modal information about their interactions. For this, we introduce MuMA-ToM, a Multi-modal Multi-Agent Theory of Mind benchmark. MuMA-ToM is the first multi-modal Theory of Mind benchmark that evaluates mental reasoning in embodied multi-agent interactions. In MuMA-ToM, we provide video and text descriptions of people's multi-modal behavior in realistic household environments. Based on the context, we then ask questions about people's goals, beliefs, and beliefs about others' goals. We validated MuMA-ToM in a human experiment and provided a human baseline. We also proposed a novel multi-modal, multi-agent ToM model, LIMP (Language model-based Inverse Multi-agent Planning). Our experimental results show that LIMP significantly outperforms state-of-the-art methods, including large multi-modal models (e.g., GPT-4o, Gemini-1.5 Pro) and a recent multi-modal ToM model, BIP-ALM.
JieHua Paintings Style Feature Extracting Model using Stable Diffusion with ControlNet
Aug 21, 2024


This study proposes a novel approach to extract stylistic features of Jiehua: the utilization of the Fine-tuned Stable Diffusion Model with ControlNet (FSDMC) to refine depiction techniques from artists' Jiehua. The training data for FSDMC is based on the opensource Jiehua artist's work collected from the Internet, which were subsequently manually constructed in the format of (Original Image, Canny Edge Features, Text Prompt). By employing the optimal hyperparameters identified in this paper, it was observed FSDMC outperforms CycleGAN, another mainstream style transfer model. FSDMC achieves FID of 3.27 on the dataset and also surpasses CycleGAN in terms of expert evaluation. This not only demonstrates the model's high effectiveness in extracting Jiehua's style features, but also preserves the original pre-trained semantic information. The findings of this study suggest that the application of FSDMC with appropriate hyperparameters can enhance the efficacy of the Stable Diffusion Model in the field of traditional art style migration tasks, particularly within the context of Jiehua.