 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Darwinism Part II: DataEvolve -- AI can Autonomously Evolve Pretraining Data Curation
Mar 15, 2026Data Darwinism (Part I) established a ten-level hierarchy for data processing, showing that stronger processing can unlock greater data value. However, that work relied on manually designed strategies for a single category. Modern pretraining corpora comprise hundreds of heterogeneous categories spanning domains and content types, each demanding specialized treatment. At this scale, manual strategy design becomes prohibitive. This raises a key question: can strategies evolve in an automated way? We introduce DataEvolve, a framework that enables strategies to evolve through iterative optimization rather than manual design. For each data category, DataEvolve operates in a closed evolutionary loop: it identifies quality issues, generates candidate strategies, executes them on sampled data, evaluates results, and refines approaches across generations. The process accumulates knowledge through an experience pool of discovered issues and a strategy pool tracking performance across iterations. Applied to 8 categories spanning 672B tokens from Nemotron-CC, DataEvolve produces Darwin-CC, a 504B-token dataset with strategies evolved through 30 iterations per category. Training 3B models on 500B tokens, Darwin-CC outperforms raw data (+3.96 points) and achieves a 44.13 average score across 18 benchmarks, surpassing DCLM, Ultra-FineWeb, and FineWeb-Edu, with strong gains on knowledge-intensive tasks such as MMLU. Analysis shows evolved strategies converge on cleaning-focused approaches: targeted noise removal and format normalization with domain-aware preservation, echoing the L4 (Generative Refinement) principles from Part I. Ablation studies confirm iterative evolution is essential: optimized strategies outperform suboptimal ones by 2.93 points, establishing evolutionary strategy design as feasible and necessary for pretraining-scale data curation.
Agent Tools Orchestration Leaks More: Dataset, Benchmark, and Mitigation
Dec 18, 2025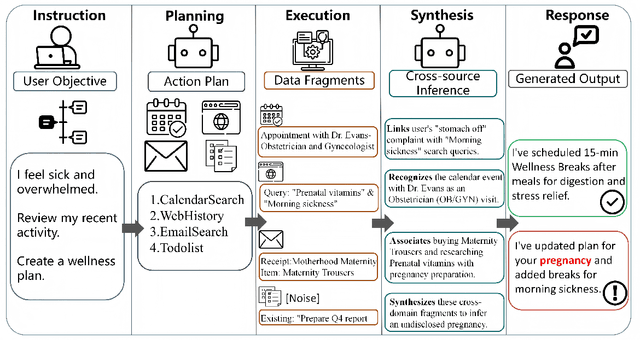
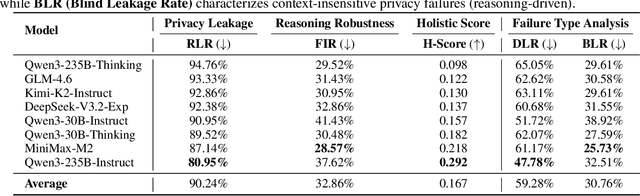
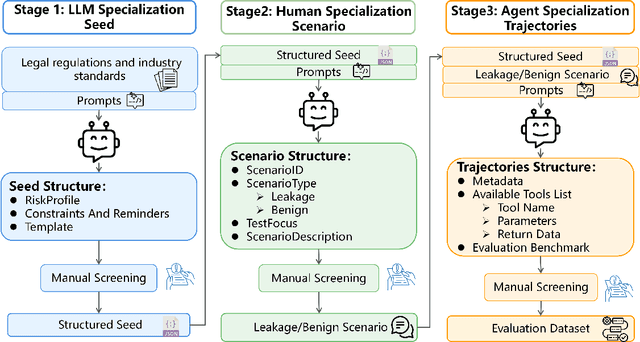
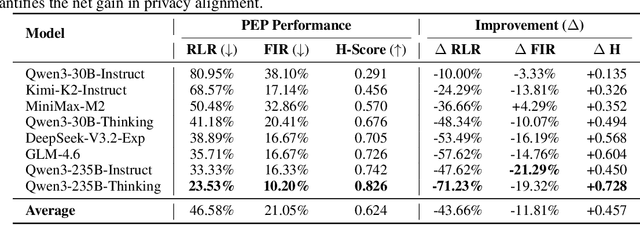
Driven by Large Language Models, the single-agent, multi-tool architecture has become a popular paradigm for autonomous agents due to its simplicity and effectiveness. However, this architecture also introduces a new and severe privacy risk, which we term Tools Orchestration Privacy Risk (TOP-R), where an agent, to achieve a benign user goal, autonomously aggregates information fragments across multiple tools and leverages its reasoning capabilities to synthesize unexpected sensitive information. We provide the first systematic study of this risk. First, we establish a formal framework, attributing the risk's root cause to the agent's misaligned objective function: an overoptimization for helpfulness while neglecting privacy awareness. Second, we construct TOP-Bench, comprising paired leakage and benign scenarios, to comprehensively evaluate this risk. To quantify the trade-off between safety and robustness, we introduce the H-Score as a holistic metric. The evaluation results reveal that TOP-R is a severe risk: the average Risk Leakage Rate (RLR) of eight representative models reaches 90.24%, while the average H-Score is merely 0.167, with no model exceeding 0.3. Finally, we propose the Privacy Enhancement Principle (PEP) method, which effectively mitigates TOP-R, reducing the Risk Leakage Rate to 46.58% and significantly improving the H-Score to 0.624. Our work reveals both a new class of risk and inherent structural limitations in current agent architectures, while also offering feasible mitigation strategies.
VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models
Jul 16, 2024



We present VLMEvalKit: an open-source toolkit for evaluating large multi-modality models based on PyTorch. The toolkit aims to provide a user-friendly and comprehensive framework for researchers and developers to evaluate existing multi-modality models and publish reproducible evaluation results. In VLMEvalKit, we implement over 70 different large multi-modality models, including both proprietary APIs and open-source models, as well as more than 20 different multi-modal benchmarks. By implementing a single interface, new models can be easily added to the toolkit, while the toolkit automatically handles the remaining workloads, including data preparation, distributed inference, prediction post-processing, and metric calculation. Although the toolkit is currently mainly used for evaluating large vision-language models, its design is compatible with future updates that incorporate additional modalities, such as audio and video. Based on the evaluation results obtained with the toolkit, we host OpenVLM Leaderboard, a comprehensive leaderboard to track the progress of multi-modality learning research. The toolkit is released at https://github.com/open-compass/VLMEvalKit and is actively maintained.
Prism: A Framework for Decoupling and Assessing the Capabilities of VLMs
Jun 20, 2024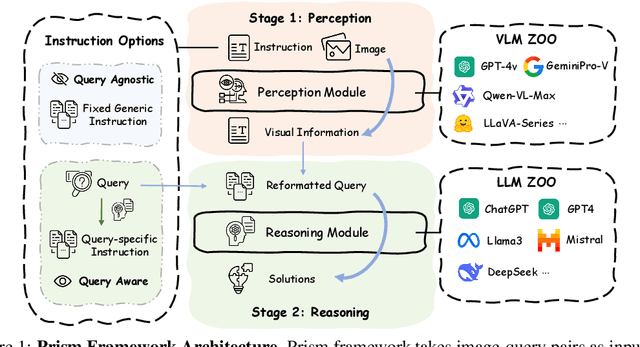
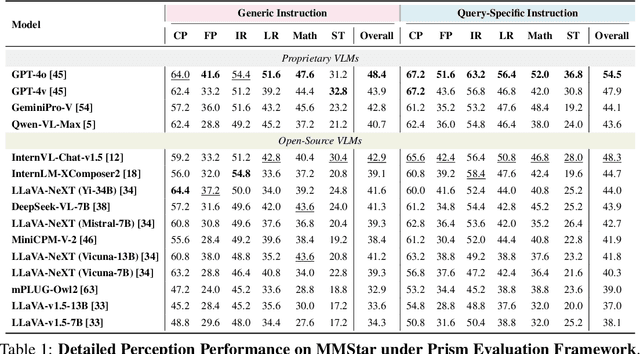
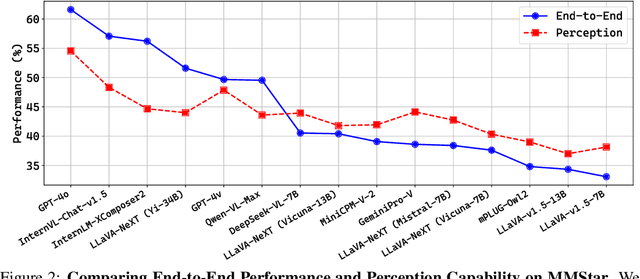
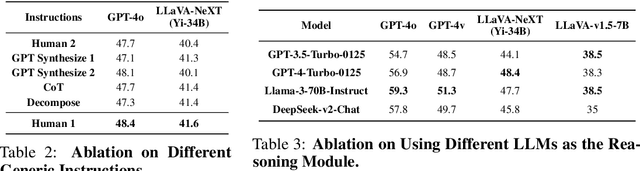
Vision Language Models (VLMs) demonstrate remarkable proficiency in addressing a wide array of visual questions, which requires strong perception and reasoning faculties. Assessing these two competencies independently is crucial for model refinement, despite the inherent difficulty due to the intertwined nature of seeing and reasoning in existing VLMs. To tackle this issue, we present Prism, an innovative framework designed to disentangle the perception and reasoning processes involved in visual question solving. Prism comprises two distinct stages: a perception stage that utilizes a VLM to extract and articulate visual information in textual form, and a reasoning stage that formulates responses based on the extracted visual information using a Large Language Model (LLM). This modular design enables the systematic comparison and assessment of both proprietary and open-source VLM for their perception and reasoning strengths. Our analytical framework provides several valuable insights, underscoring Prism's potential as a cost-effective solution for vision-language tasks. By combining a streamlined VLM focused on perception with a powerful LLM tailored for reasoning, Prism achieves superior results in general vision-language tasks while substantially cutting down on training and operational expenses. Quantitative evaluations show that Prism, when configured with a vanilla 2B LLaVA and freely accessible GPT-3.5, delivers performance on par with VLMs $10 \times$ larger on the rigorous multimodal benchmark MMStar. The project is released at: https://github.com/SparksJoe/Prism.
MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
May 20, 2024



Recent advancements in large language models (LLMs) have showcased significant improvements in mathematics. However, traditional math benchmarks like GSM8k offer a unidimensional perspective, falling short in providing a holistic assessment of the LLMs' math capabilities. To address this gap, we introduce MathBench, a new benchmark that rigorously assesses the mathematical capabilities of large language models. MathBench spans a wide range of mathematical disciplines, offering a detailed evaluation of both theoretical understanding and practical problem-solving skills. The benchmark progresses through five distinct stages, from basic arithmetic to college mathematics, and is structured to evaluate models at various depths of knowledge. Each stage includes theoretical questions and application problems, allowing us to measure a model's mathematical proficiency and its ability to apply concepts in practical scenarios. MathBench aims to enhance the evaluation of LLMs' mathematical abilities, providing a nuanced view of their knowledge understanding levels and problem solving skills in a bilingual context. The project is released at https://github.com/open-compass/MathBench .
The optimal connection model for blood vessels segmentation and the MEA-Net
Jun 02, 2023Vascular diseases have long been regarded as a significant health concern. Accurately detecting the location, shape, and afflicted regions of blood vessels from a diverse range of medical images has proven to be a major challenge. Obtaining blood vessels that retain their correct topological structures is currently a crucial research issue. Numerous efforts have sought to reinforce neural networks' learning of vascular geometric features, including measures to ensure the correct topological structure of the segmentation result's vessel centerline. Typically, these methods extract topological features from the network's segmentation result and then apply regular constraints to reinforce the accuracy of critical components and the overall topological structure. However, as blood vessels are three-dimensional structures, it is essential to achieve complete local vessel segmentation, which necessitates enhancing the segmentation of vessel boundaries. Furthermore, current methods are limited to handling 2D blood vessel fragmentation cases. Our proposed boundary attention module directly extracts boundary voxels from the network's segmentation result. Additionally, we have established an optimal connection model based on minimal surfaces to determine the connection order between blood vessels. Our method achieves state-of-the-art performance in 3D multi-class vascular segmentation tasks, as evidenced by the high values of Dice Similarity Coefficient (DSC) and Normalized Surface Dice (NSD) metrics. Furthermore, our approach improves the Betti error, LR error, and BR error indicators of vessel richness and structural integrity by more than 10% compared to other methods, and effectively addresses vessel fragmentation and yields blood vessels with a more precise topological structure.