 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Personalized Reward Model for Vision Generation
Feb 02, 2026Recent advancements in multimodal reward models (RMs) have significantly propelled the development of visual generation. Existing frameworks typically adopt Bradley-Terry-style preference modeling or leverage generative VLMs as judges, and subsequently optimize visual generation models via reinforcement learning. However, current RMs suffer from inherent limitations: they often follow a one-size-fits-all paradigm that assumes a monolithic preference distribution or relies on fixed evaluation rubrics. As a result, they are insensitive to content-specific visual cues, leading to systematic misalignment with subjective and context-dependent human preferences. To this end, inspired by human assessment, we propose UnifiedReward-Flex, a unified personalized reward model for vision generation that couples reward modeling with flexible and context-adaptive reasoning. Specifically, given a prompt and the generated visual content, it first interprets the semantic intent and grounds on visual evidence, then dynamically constructs a hierarchical assessment by instantiating fine-grained criteria under both predefined and self-generated high-level dimensions. Our training pipeline follows a two-stage process: (1) we first distill structured, high-quality reasoning traces from advanced closed-source VLMs to bootstrap SFT, equipping the model with flexible and context-adaptive reasoning behaviors; (2) we then perform direct preference optimization (DPO) on carefully curated preference pairs to further strengthen reasoning fidelity and discriminative alignment. To validate the effectiveness, we integrate UnifiedReward-Flex into the GRPO framework for image and video synthesis, and extensive results demonstrate its superiority.
EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents
Jan 23, 2026We introduce EMemBench, a programmatic benchmark for evaluating long-term memory of agents through interactive games. Rather than using a fixed set of questions, EMemBench generates questions from each agent's own trajectory, covering both text and visual game environments. Each template computes verifiable ground truth from underlying game signals, with controlled answerability and balanced coverage over memory skills: single/multi-hop recall, induction, temporal, spatial, logical, and adversarial. We evaluate memory agents with strong LMs/VLMs as backbones, using in-context prompting as baselines. Across 15 text games and multiple visual seeds, results are far from saturated: induction and spatial reasoning are persistent bottlenecks, especially in visual setting. Persistent memory yields clear gains for open backbones on text games, but improvements are less consistent for VLM agents, suggesting that visually grounded episodic memory remains an open challenge. A human study further confirms the difficulty of EMemBench.
Think Visually, Reason Textually: Vision-Language Synergy in ARC
Nov 19, 2025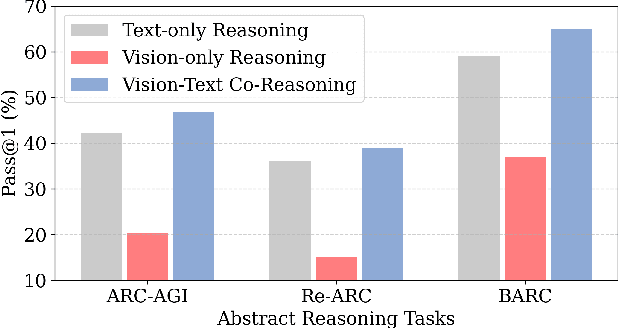
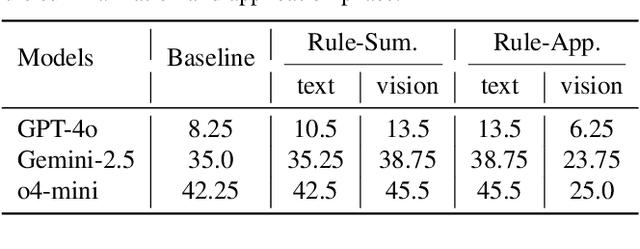

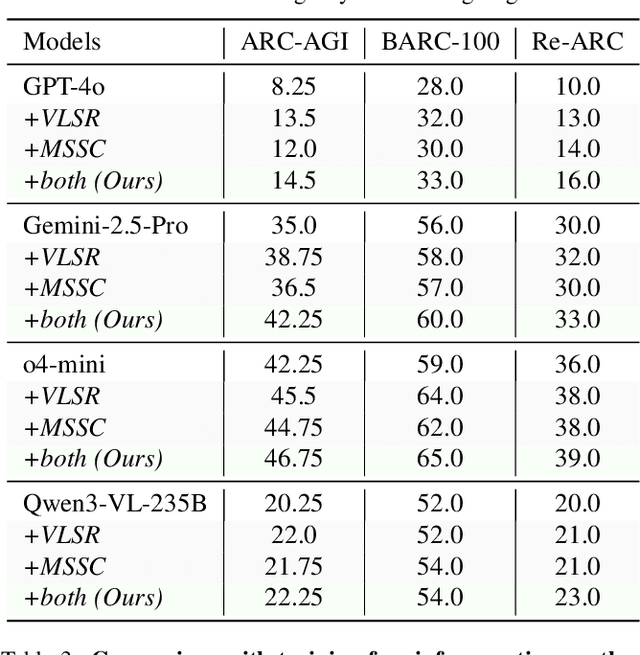
Abstract reasoning from minimal examples remains a core unsolved problem for frontier foundation models such as GPT-5 and Grok 4. These models still fail to infer structured transformation rules from a handful of examples, which is a key hallmark of human intelligence. The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) provides a rigorous testbed for this capability, demanding conceptual rule induction and transfer to novel tasks. Most existing methods treat ARC-AGI as a purely textual reasoning task, overlooking the fact that humans rely heavily on visual abstraction when solving such puzzles. However, our pilot experiments reveal a paradox: naively rendering ARC-AGI grids as images degrades performance due to imprecise rule execution. This leads to our central hypothesis that vision and language possess complementary strengths across distinct reasoning stages: vision supports global pattern abstraction and verification, whereas language specializes in symbolic rule formulation and precise execution. Building on this insight, we introduce two synergistic strategies: (1) Vision-Language Synergy Reasoning (VLSR), which decomposes ARC-AGI into modality-aligned subtasks; and (2) Modality-Switch Self-Correction (MSSC), which leverages vision to verify text-based reasoning for intrinsic error correction. Extensive experiments demonstrate that our approach yields up to a 4.33% improvement over text-only baselines across diverse flagship models and multiple ARC-AGI tasks. Our findings suggest that unifying visual abstraction with linguistic reasoning is a crucial step toward achieving generalizable, human-like intelligence in future foundation models. Source code will be released soon.
Generative Photographic Control for Scene-Consistent Video Cinematic Editing
Nov 17, 2025Cinematic storytelling is profoundly shaped by the artful manipulation of photographic elements such as depth of field and exposure. These effects are crucial in conveying mood and creating aesthetic appeal. However, controlling these effects in generative video models remains highly challenging, as most existing methods are restricted to camera motion control. In this paper, we propose CineCtrl, the first video cinematic editing framework that provides fine control over professional camera parameters (e.g., bokeh, shutter speed). We introduce a decoupled cross-attention mechanism to disentangle camera motion from photographic inputs, allowing fine-grained, independent control without compromising scene consistency. To overcome the shortage of training data, we develop a comprehensive data generation strategy that leverages simulated photographic effects with a dedicated real-world collection pipeline, enabling the construction of a large-scale dataset for robust model training. Extensive experiments demonstrate that our model generates high-fidelity videos with precisely controlled, user-specified photographic camera effects.
Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning
Oct 31, 2025Spatial understanding remains a weakness of Large Vision-Language Models (LVLMs). Existing supervised fine-tuning (SFT) and recent reinforcement learning with verifiable rewards (RLVR) pipelines depend on costly supervision, specialized tools, or constrained environments that limit scale. We introduce Spatial-SSRL, a self-supervised RL paradigm that derives verifiable signals directly from ordinary RGB or RGB-D images. Spatial-SSRL automatically formulates five pretext tasks that capture 2D and 3D spatial structure: shuffled patch reordering, flipped patch recognition, cropped patch inpainting, regional depth ordering, and relative 3D position prediction. These tasks provide ground-truth answers that are easy to verify and require no human or LVLM annotation. Training on our tasks substantially improves spatial reasoning while preserving general visual capabilities. On seven spatial understanding benchmarks in both image and video settings, Spatial-SSRL delivers average accuracy gains of 4.63% (3B) and 3.89% (7B) over the Qwen2.5-VL baselines. Our results show that simple, intrinsic supervision enables RLVR at scale and provides a practical route to stronger spatial intelligence in LVLMs.
$\text{G}^2$RPO: Granular GRPO for Precise Reward in Flow Models
Oct 02, 2025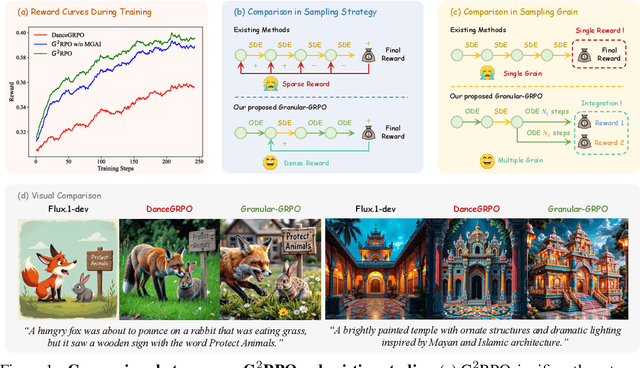
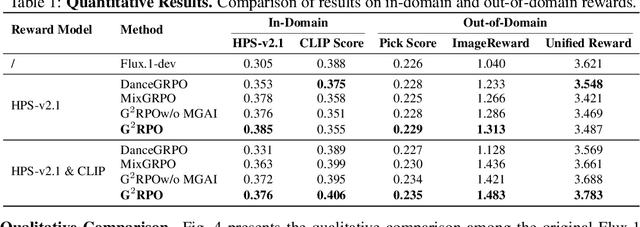
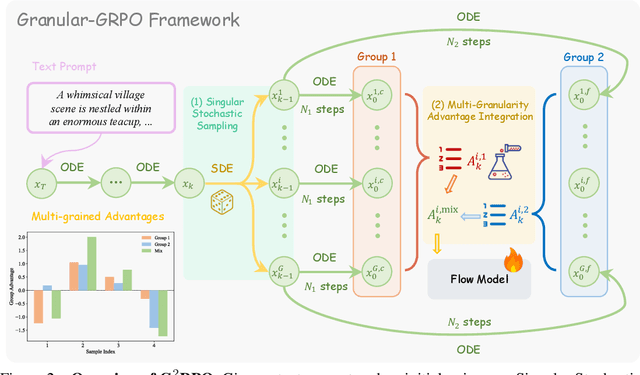
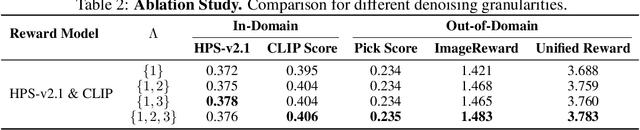
The integration of online reinforcement learning (RL) into diffusion and flow models has recently emerged as a promising approach for aligning generative models with human preferences. Stochastic sampling via Stochastic Differential Equations (SDE) is employed during the denoising process to generate diverse denoising directions for RL exploration. While existing methods effectively explore potential high-value samples, they suffer from sub-optimal preference alignment due to sparse and narrow reward signals. To address these challenges, we propose a novel Granular-GRPO ($\text{G}^2$RPO ) framework that achieves precise and comprehensive reward assessments of sampling directions in reinforcement learning of flow models. Specifically, a Singular Stochastic Sampling strategy is introduced to support step-wise stochastic exploration while enforcing a high correlation between the reward and the injected noise, thereby facilitating a faithful reward for each SDE perturbation. Concurrently, to eliminate the bias inherent in fixed-granularity denoising, we introduce a Multi-Granularity Advantage Integration module that aggregates advantages computed at multiple diffusion scales, producing a more comprehensive and robust evaluation of the sampling directions. Experiments conducted on various reward models, including both in-domain and out-of-domain evaluations, demonstrate that our $\text{G}^2$RPO significantly outperforms existing flow-based GRPO baselines,highlighting its effectiveness and robustness.
CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning
Sep 26, 2025Image captioning is a fundamental task that bridges the visual and linguistic domains, playing a critical role in pre-training Large Vision-Language Models (LVLMs). Current state-of-the-art captioning models are typically trained with Supervised Fine-Tuning (SFT), a paradigm that relies on expensive, non-scalable data annotated by humans or proprietary models. This approach often leads to models that memorize specific ground-truth answers, limiting their generality and ability to generate diverse, creative descriptions. To overcome the limitation of SFT, we propose applying the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm to the open-ended task of image captioning. A primary challenge, however, is designing an objective reward function for the inherently subjective nature of what constitutes a "good" caption. We introduce Captioning Reinforcement Learning (CapRL), a novel training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding image. CapRL employs a decoupled two-stage pipeline where an LVLM generates a caption, and the objective reward is derived from the accuracy of a separate, vision-free LLM answering Multiple-Choice Questions based solely on that caption. As the first study to apply RLVR to the subjective image captioning task, we demonstrate that CapRL significantly enhances multiple settings. Pretraining on the CapRL-5M caption dataset annotated by CapRL-3B results in substantial gains across 12 benchmarks. Moreover, within the Prism Framework for caption quality evaluation, CapRL achieves performance comparable to Qwen2.5-VL-72B, while exceeding the baseline by an average margin of 8.4%. Code is available here: https://github.com/InternLM/CapRL.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
SPARK: Synergistic Policy And Reward Co-Evolving Framework
Sep 26, 2025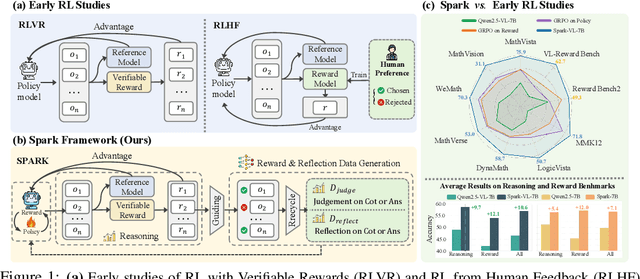
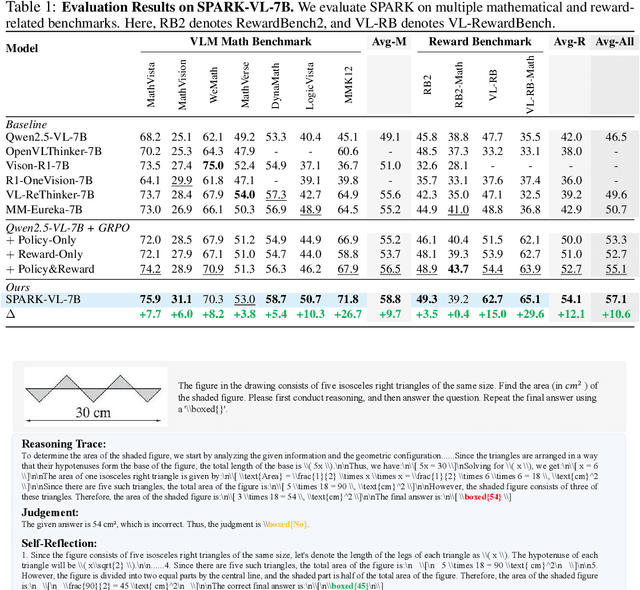
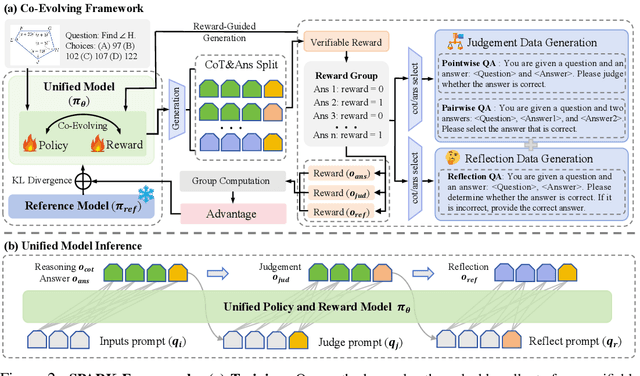
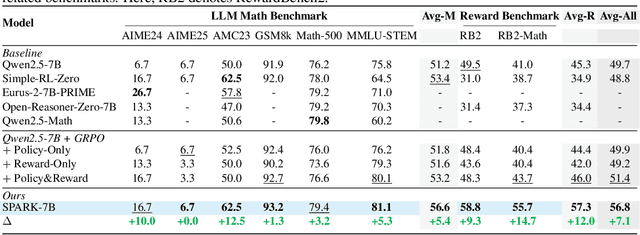
Recent Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) increasingly use Reinforcement Learning (RL) for post-pretraining, such as RL with Verifiable Rewards (RLVR) for objective tasks and RL from Human Feedback (RLHF) for subjective tasks. However, RLHF incurs high costs and potential reward-policy mismatch due to reliance on human preferences, while RLVR still wastes supervision by discarding rollouts and correctness signals after each update. To address these challenges, we introduce the Synergistic Policy And Reward Co-Evolving Framework (SPARK), an efficient, on-policy, and stable method that builds on RLVR. Instead of discarding rollouts and correctness data, SPARK recycles this valuable information to simultaneously train the model itself as a generative reward model. This auxiliary training uses a mix of objectives, such as pointwise reward score, pairwise comparison, and evaluation conditioned on further-reflection responses, to teach the model to evaluate and improve its own responses. Our process eliminates the need for a separate reward model and costly human preference data. SPARK creates a positive co-evolving feedback loop: improved reward accuracy yields better policy gradients, which in turn produce higher-quality rollouts that further refine the reward model. Our unified framework supports test-time scaling via self-reflection without external reward models and their associated costs. We show that SPARK achieves significant performance gains on multiple LLM and LVLM models and multiple reasoning, reward models, and general benchmarks. For example, SPARK-VL-7B achieves an average 9.7% gain on 7 reasoning benchmarks, 12.1% on 2 reward benchmarks, and 1.5% on 8 general benchmarks over the baselines, demonstrating robustness and broad generalization.
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Aug 28, 2025Recent advancements highlight the importance of GRPO-based reinforcement learning methods and benchmarking in enhancing text-to-image (T2I) generation. However, current methods using pointwise reward models (RM) for scoring generated images are susceptible to reward hacking. We reveal that this happens when minimal score differences between images are amplified after normalization, creating illusory advantages that drive the model to over-optimize for trivial gains, ultimately destabilizing the image generation process. To address this, we propose Pref-GRPO, a pairwise preference reward-based GRPO method that shifts the optimization objective from score maximization to preference fitting, ensuring more stable training. In Pref-GRPO, images are pairwise compared within each group using preference RM, and the win rate is used as the reward signal. Extensive experiments demonstrate that PREF-GRPO differentiates subtle image quality differences, providing more stable advantages and mitigating reward hacking. Additionally, existing T2I benchmarks are limited by coarse evaluation criteria, hindering comprehensive model assessment. To solve this, we introduce UniGenBench, a unified T2I benchmark comprising 600 prompts across 5 main themes and 20 subthemes. It evaluates semantic consistency through 10 primary and 27 sub-criteria, leveraging MLLM for benchmark construction and evaluation. Our benchmarks uncover the strengths and weaknesses of both open and closed-source T2I models and validate the effectiveness of Pref-GRPO.