 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetCon: Towards Open-Ended Referring Segmentation via Set-Level Concept Prediction
May 19, 2026Referring segmentation grounds natural-language queries to pixel-level masks, but extending it to complex scenarios with multiple instances, cross-category groups, or open-ended target sets remains challenging. Previous Large Vision Language Model (LVLM)-based methods represent referred targets with one or more special tokens sequentially, treating multiple targets as separate outputs rather than a coherent set and offering little incentive to capture set-level properties such as completeness and mutual exclusivity. We reformulate open-ended referring segmentation as explicit set-level concept prediction and propose Set-Concept Segmentation (SetCon), which uses LVLM-generated natural-language concepts, instead of segmentation-specific tokens, as semantic conditions for joint mask-set decoding. A hierarchical semantic decomposition first predicts a shared set-level concept defining the target scope and then refines it into fine-grained concept groups aligned with target subsets. To support this, a two-stage annotation pipeline augments existing reasoning segmentation datasets with hierarchical semantic supervision (236k samples, 784k concept phrases). SetCon achieves state-of-the-art results on image benchmarks (+3.3 gIoU on gRefCOCO, +12.1 gIoU on MUSE), with margins that grow as the number of referred targets increases. The concept interface also transfers to video under a detect-and-track setting, yielding new state-of-the-art results on seven referring video benchmarks, including +10.9 J&F on MeViS and +12.4 J&F on Ref-SeCVOS.
WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
May 11, 2026Large language and vision-language models increasingly power agents that act on a user's behalf through command-line interface (CLI) harnesses. However, most agent benchmarks still rely on synthetic sandboxes, short-horizon tasks, mock-service APIs, and final-answer checks, leaving open whether agents can complete realistic long-horizon work in the runtimes where they are deployed. This work presents WildClawBench, a native-runtime benchmark of 60 human-authored, bilingual, multimodal tasks spanning six thematic categories. Each task averages roughly 8 minutes of wall-clock time and over 20 tool calls, and runs inside a reproducible Docker container hosting an actual CLI agent harness (OpenClaw, Claude Code, Codex, or Hermes Agent) with access to real tools rather than mock services. Grading is hybrid, combining deterministic rule-based checks, environment-state auditing of side effects, and an LLM/VLM judge for semantic verification. Across 19 frontier models, the best, Claude Opus 4.7, reaches only 62.2% overall under OpenClaw, while every other model stays below 60%, and switching harness alone shifts a single model by up to 18 points. These results show that long-horizon, native-runtime agent evaluation remains a far-from-resolved task for current frontier models. We release the tasks, code, and containerized tooling to support reproducible evaluation.
Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
Feb 09, 2026Despite the growing video understanding capabilities of recent Multimodal Large Language Models (MLLMs), existing video benchmarks primarily assess understanding based on models' static, internal knowledge, rather than their ability to learn and adapt from dynamic, novel contexts from few examples. To bridge this gap, we present Demo-driven Video In-Context Learning, a novel task focused on learning from in-context demonstrations to answer questions about the target videos. Alongside this, we propose Demo-ICL-Bench, a challenging benchmark designed to evaluate demo-driven video in-context learning capabilities. Demo-ICL-Bench is constructed from 1200 instructional YouTube videos with associated questions, from which two types of demonstrations are derived: (i) summarizing video subtitles for text demonstration; and (ii) corresponding instructional videos as video demonstrations. To effectively tackle this new challenge, we develop Demo-ICL, an MLLM with a two-stage training strategy: video-supervised fine-tuning and information-assisted direct preference optimization, jointly enhancing the model's ability to learn from in-context examples. Extensive experiments with state-of-the-art MLLMs confirm the difficulty of Demo-ICL-Bench, demonstrate the effectiveness of Demo-ICL, and thereby unveil future research directions.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
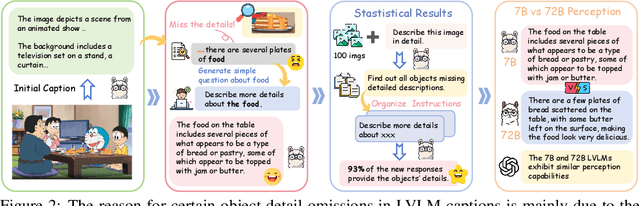


This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
SongGen: A Single Stage Auto-regressive Transformer for Text-to-Song Generation
Feb 18, 2025Text-to-song generation, the task of creating vocals and accompaniment from textual inputs, poses significant challenges due to domain complexity and data scarcity. Existing approaches often employ multi-stage generation procedures, resulting in cumbersome training and inference pipelines. In this paper, we propose SongGen, a fully open-source, single-stage auto-regressive transformer designed for controllable song generation. The proposed model facilitates fine-grained control over diverse musical attributes, including lyrics and textual descriptions of instrumentation, genre, mood, and timbre, while also offering an optional three-second reference clip for voice cloning. Within a unified auto-regressive framework, SongGen supports two output modes: mixed mode, which generates a mixture of vocals and accompaniment directly, and dual-track mode, which synthesizes them separately for greater flexibility in downstream applications. We explore diverse token pattern strategies for each mode, leading to notable improvements and valuable insights. Furthermore, we design an automated data preprocessing pipeline with effective quality control. To foster community engagement and future research, we will release our model weights, training code, annotated data, and preprocessing pipeline. The generated samples are showcased on our project page at https://liuzh-19.github.io/SongGen/ , and the code will be available at https://github.com/LiuZH-19/SongGen .
OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
Jan 09, 2025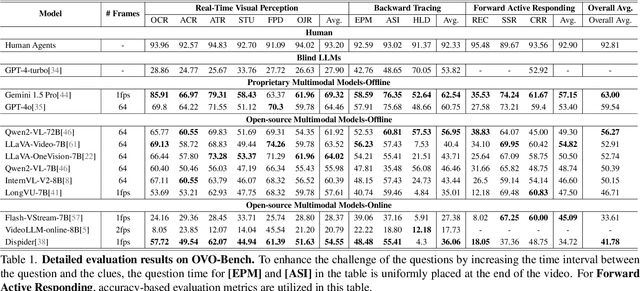
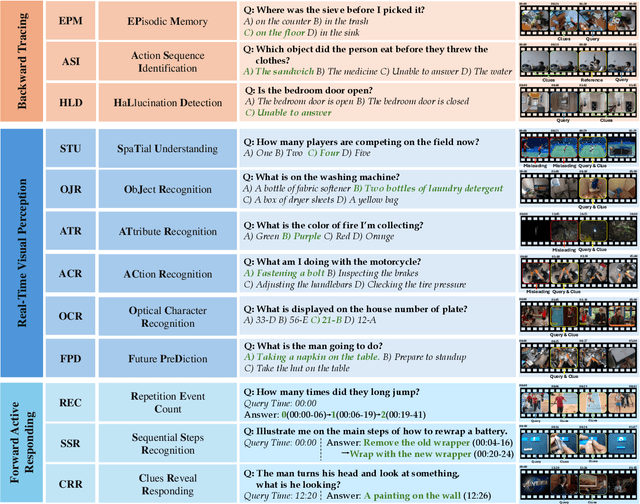
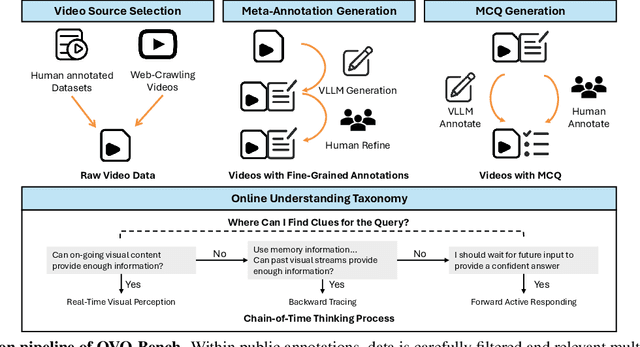
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.
Dispider: Enabling Video LLMs with Active Real-Time Interaction via Disentangled Perception, Decision, and Reaction
Jan 06, 2025



Active Real-time interaction with video LLMs introduces a new paradigm for human-computer interaction, where the model not only understands user intent but also responds while continuously processing streaming video on the fly. Unlike offline video LLMs, which analyze the entire video before answering questions, active real-time interaction requires three capabilities: 1) Perception: real-time video monitoring and interaction capturing. 2) Decision: raising proactive interaction in proper situations, 3) Reaction: continuous interaction with users. However, inherent conflicts exist among the desired capabilities. The Decision and Reaction require a contrary Perception scale and grain, and the autoregressive decoding blocks the real-time Perception and Decision during the Reaction. To unify the conflicted capabilities within a harmonious system, we present Dispider, a system that disentangles Perception, Decision, and Reaction. Dispider features a lightweight proactive streaming video processing module that tracks the video stream and identifies optimal moments for interaction. Once the interaction is triggered, an asynchronous interaction module provides detailed responses, while the processing module continues to monitor the video in the meantime. Our disentangled and asynchronous design ensures timely, contextually accurate, and computationally efficient responses, making Dispider ideal for active real-time interaction for long-duration video streams. Experiments show that Dispider not only maintains strong performance in conventional video QA tasks, but also significantly surpasses previous online models in streaming scenario responses, thereby validating the effectiveness of our architecture. The code and model are released at \url{https://github.com/Mark12Ding/Dispider}.
InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal System for Long-term Streaming Video and Audio Interactions
Dec 12, 2024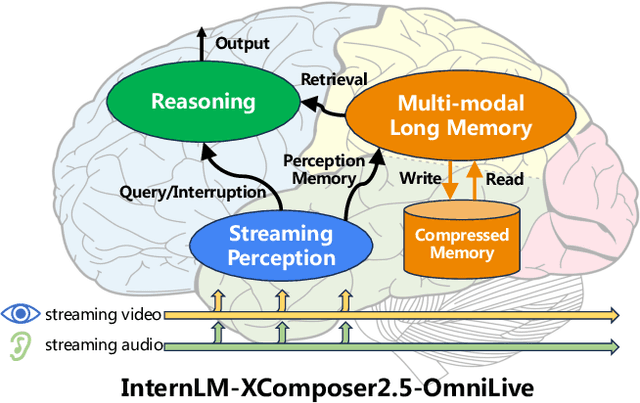
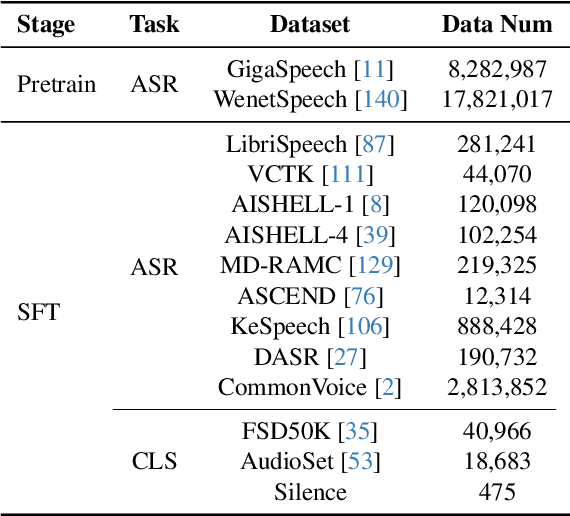
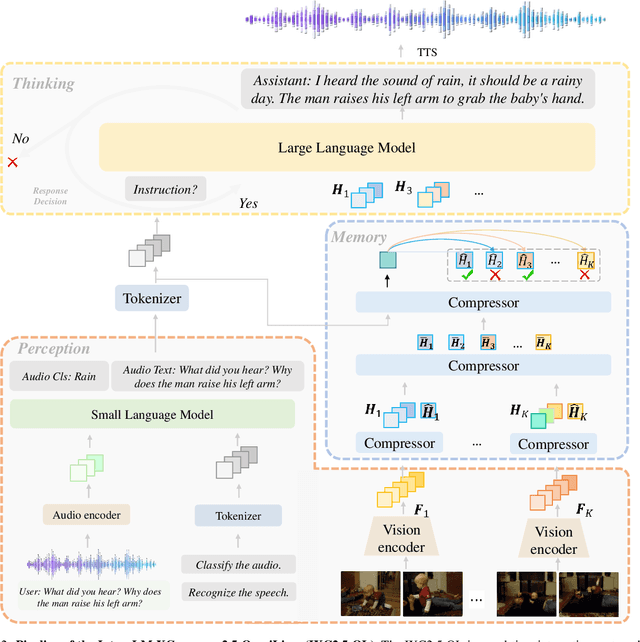

Creating AI systems that can interact with environments over long periods, similar to human cognition, has been a longstanding research goal. Recent advancements in multimodal large language models (MLLMs) have made significant strides in open-world understanding. However, the challenge of continuous and simultaneous streaming perception, memory, and reasoning remains largely unexplored. Current MLLMs are constrained by their sequence-to-sequence architecture, which limits their ability to process inputs and generate responses simultaneously, akin to being unable to think while perceiving. Furthermore, relying on long contexts to store historical data is impractical for long-term interactions, as retaining all information becomes costly and inefficient. Therefore, rather than relying on a single foundation model to perform all functions, this project draws inspiration from the concept of the Specialized Generalist AI and introduces disentangled streaming perception, reasoning, and memory mechanisms, enabling real-time interaction with streaming video and audio input. The proposed framework InternLM-XComposer2.5-OmniLive (IXC2.5-OL) consists of three key modules: (1) Streaming Perception Module: Processes multimodal information in real-time, storing key details in memory and triggering reasoning in response to user queries. (2) Multi-modal Long Memory Module: Integrates short-term and long-term memory, compressing short-term memories into long-term ones for efficient retrieval and improved accuracy. (3) Reasoning Module: Responds to queries and executes reasoning tasks, coordinating with the perception and memory modules. This project simulates human-like cognition, enabling multimodal large language models to provide continuous and adaptive service over time.
SAM2Long: Enhancing SAM 2 for Long Video Segmentation with a Training-Free Memory Tree
Oct 21, 2024The Segment Anything Model 2 (SAM 2) has emerged as a powerful foundation model for object segmentation in both images and videos, paving the way for various downstream video applications. The crucial design of SAM 2 for video segmentation is its memory module, which prompts object-aware memories from previous frames for current frame prediction. However, its greedy-selection memory design suffers from the "error accumulation" problem, where an errored or missed mask will cascade and influence the segmentation of the subsequent frames, which limits the performance of SAM 2 toward complex long-term videos. To this end, we introduce SAM2Long, an improved training-free video object segmentation strategy, which considers the segmentation uncertainty within each frame and chooses the video-level optimal results from multiple segmentation pathways in a constrained tree search manner. In practice, we maintain a fixed number of segmentation pathways throughout the video. For each frame, multiple masks are proposed based on the existing pathways, creating various candidate branches. We then select the same fixed number of branches with higher cumulative scores as the new pathways for the next frame. After processing the final frame, the pathway with the highest cumulative score is chosen as the final segmentation result. Benefiting from its heuristic search design, SAM2Long is robust toward occlusions and object reappearances, and can effectively segment and track objects for complex long-term videos. Notably, SAM2Long achieves an average improvement of 3.0 points across all 24 head-to-head comparisons, with gains of up to 5.3 points in J&F on long-term video object segmentation benchmarks such as SA-V and LVOS. The code is released at https://github.com/Mark12Ding/SAM2Long.
Image Compression for Machine and Human Vision with Spatial-Frequency Adaptation
Jul 13, 2024



Image compression for machine and human vision (ICMH) has gained increasing attention in recent years. Existing ICMH methods are limited by high training and storage overheads due to heavy design of task-specific networks. To address this issue, in this paper, we develop a novel lightweight adapter-based tuning framework for ICMH, named Adapt-ICMH, that better balances task performance and bitrates with reduced overheads. We propose a spatial-frequency modulation adapter (SFMA) that simultaneously eliminates non-semantic redundancy with a spatial modulation adapter, and enhances task-relevant frequency components and suppresses task-irrelevant frequency components with a frequency modulation adapter. The proposed adapter is plug-and-play and compatible with almost all existing learned image compression models without compromising the performance of pre-trained models. Experiments demonstrate that Adapt-ICMH consistently outperforms existing ICMH frameworks on various machine vision tasks with fewer fine-tuned parameters and reduced computational complexity. Code will be released at https://github.com/qingshi9974/ECCV2024-AdpatICMH .