 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretic Optimization for Task-Adapted Compressed Sensing Magnetic Resonance Imaging
Apr 14, 2026Task-adapted compressed sensing magnetic resonance imaging (CS-MRI) is emerging to address the specific demands of downstream clinical tasks with significantly fewer k-space measurements than required by Nyquist sampling. However, existing task-adapted CS-MRI methods suffer from the uncertainty problem for medical diagnosis and cannot achieve adaptive sampling in end-to-end optimization with reconstruction or clinical tasks. To address these limitations, we propose the first task-adapted CS-MRI from the information-theoretic perspective to simultaneously achieve probabilistic inference for uncertainty prediction and adapt to arbitrary sampling ratios and versatile clinical applications. Specifically, we formalize the task-adapted CS-MRI optimization problem by maximizing the mutual information between undersampled k-space measurements and clinical tasks to enable probabilistic inference for addressing the uncertainty problem. We leverage amortized optimization and construct tractable variational bounds for mutual information to jointly optimize sampling, reconstruction, and task-inference models, which enables flexible sampling ratio control using a single end-to-end trained model. Furthermore, the proposed framework addresses two kinds of distinct clinical scenarios within a unified approach, i.e., i) joint task and reconstruction, where reconstruction serves as an auxiliary process to enhance task performance; and ii) task implementation with suppressed reconstruction, applicable for privacy protection. Extensive experiments on large-scale MRI datasets demonstrate that the proposed framework achieves highly competitive performance on standard metrics like Dice compared to deterministic counterpart but provides better distribution matching to the ground-truth posterior distribution as measured by the generalized energy distance (GED).
Towards Holistic Modeling for Video Frame Interpolation with Auto-regressive Diffusion Transformers
Jan 21, 2026Existing video frame interpolation (VFI) methods often adopt a frame-centric approach, processing videos as independent short segments (e.g., triplets), which leads to temporal inconsistencies and motion artifacts. To overcome this, we propose a holistic, video-centric paradigm named \textbf{L}ocal \textbf{D}iffusion \textbf{F}orcing for \textbf{V}ideo \textbf{F}rame \textbf{I}nterpolation (LDF-VFI). Our framework is built upon an auto-regressive diffusion transformer that models the entire video sequence to ensure long-range temporal coherence. To mitigate error accumulation inherent in auto-regressive generation, we introduce a novel skip-concatenate sampling strategy that effectively maintains temporal stability. Furthermore, LDF-VFI incorporates sparse, local attention and tiled VAE encoding, a combination that not only enables efficient processing of long sequences but also allows generalization to arbitrary spatial resolutions (e.g., 4K) at inference without retraining. An enhanced conditional VAE decoder, which leverages multi-scale features from the input video, further improves reconstruction fidelity. Empirically, LDF-VFI achieves state-of-the-art performance on challenging long-sequence benchmarks, demonstrating superior per-frame quality and temporal consistency, especially in scenes with large motion. The source code is available at https://github.com/xypeng9903/LDF-VFI.
Error-Propagation-Free Learned Video Compression With Dual-Domain Progressive Temporal Alignment
Dec 11, 2025Existing frameworks for learned video compression suffer from a dilemma between inaccurate temporal alignment and error propagation for motion estimation and compensation (ME/MC). The separate-transform framework employs distinct transforms for intra-frame and inter-frame compression to yield impressive rate-distortion (R-D) performance but causes evident error propagation, while the unified-transform framework eliminates error propagation via shared transforms but is inferior in ME/MC in shared latent domains. To address this limitation, in this paper, we propose a novel unifiedtransform framework with dual-domain progressive temporal alignment and quality-conditioned mixture-of-expert (QCMoE) to enable quality-consistent and error-propagation-free streaming for learned video compression. Specifically, we propose dualdomain progressive temporal alignment for ME/MC that leverages coarse pixel-domain alignment and refined latent-domain alignment to significantly enhance temporal context modeling in a coarse-to-fine fashion. The coarse pixel-domain alignment efficiently handles simple motion patterns with optical flow estimated from a single reference frame, while the refined latent-domain alignment develops a Flow-Guided Deformable Transformer (FGDT) over latents from multiple reference frames to achieve long-term motion refinement (LTMR) for complex motion patterns. Furthermore, we design a QCMoE module for continuous bit-rate adaptation that dynamically assigns different experts to adjust quantization steps per pixel based on target quality and content rather than relies on a single quantization step. QCMoE allows continuous and consistent rate control with appealing R-D performance. Experimental results show that the proposed method achieves competitive R-D performance compared with the state-of-the-arts, while successfully eliminating error propagation.
3DGabSplat: 3D Gabor Splatting for Frequency-adaptive Radiance Field Rendering
Aug 07, 2025Recent prominence in 3D Gaussian Splatting (3DGS) has enabled real-time rendering while maintaining high-fidelity novel view synthesis. However, 3DGS resorts to the Gaussian function that is low-pass by nature and is restricted in representing high-frequency details in 3D scenes. Moreover, it causes redundant primitives with degraded training and rendering efficiency and excessive memory overhead. To overcome these limitations, we propose 3D Gabor Splatting (3DGabSplat) that leverages a novel 3D Gabor-based primitive with multiple directional 3D frequency responses for radiance field representation supervised by multi-view images. The proposed 3D Gabor-based primitive forms a filter bank incorporating multiple 3D Gabor kernels at different frequencies to enhance flexibility and efficiency in capturing fine 3D details. Furthermore, to achieve novel view rendering, an efficient CUDA-based rasterizer is developed to project the multiple directional 3D frequency components characterized by 3D Gabor-based primitives onto the 2D image plane, and a frequency-adaptive mechanism is presented for adaptive joint optimization of primitives. 3DGabSplat is scalable to be a plug-and-play kernel for seamless integration into existing 3DGS paradigms to enhance both efficiency and quality of novel view synthesis. Extensive experiments demonstrate that 3DGabSplat outperforms 3DGS and its variants using alternative primitives, and achieves state-of-the-art rendering quality across both real-world and synthetic scenes. Remarkably, we achieve up to 1.35 dB PSNR gain over 3DGS with simultaneously reduced number of primitives and memory consumption.
Noise Conditional Variational Score Distillation
Jun 11, 2025
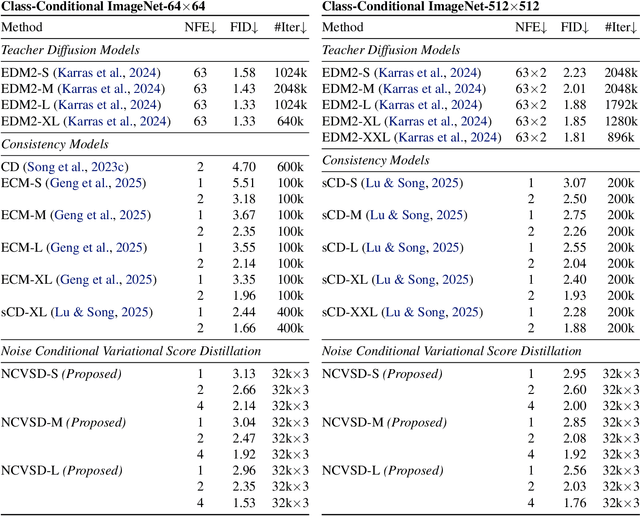
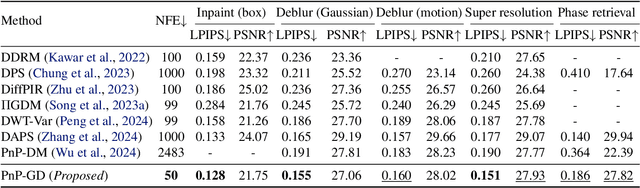

We propose Noise Conditional Variational Score Distillation (NCVSD), a novel method for distilling pretrained diffusion models into generative denoisers. We achieve this by revealing that the unconditional score function implicitly characterizes the score function of denoising posterior distributions. By integrating this insight into the Variational Score Distillation (VSD) framework, we enable scalable learning of generative denoisers capable of approximating samples from the denoising posterior distribution across a wide range of noise levels. The proposed generative denoisers exhibit desirable properties that allow fast generation while preserve the benefit of iterative refinement: (1) fast one-step generation through sampling from pure Gaussian noise at high noise levels; (2) improved sample quality by scaling the test-time compute with multi-step sampling; and (3) zero-shot probabilistic inference for flexible and controllable sampling. We evaluate NCVSD through extensive experiments, including class-conditional image generation and inverse problem solving. By scaling the test-time compute, our method outperforms teacher diffusion models and is on par with consistency models of larger sizes. Additionally, with significantly fewer NFEs than diffusion-based methods, we achieve record-breaking LPIPS on inverse problems.
HiPART: Hierarchical Pose AutoRegressive Transformer for Occluded 3D Human Pose Estimation
Mar 30, 2025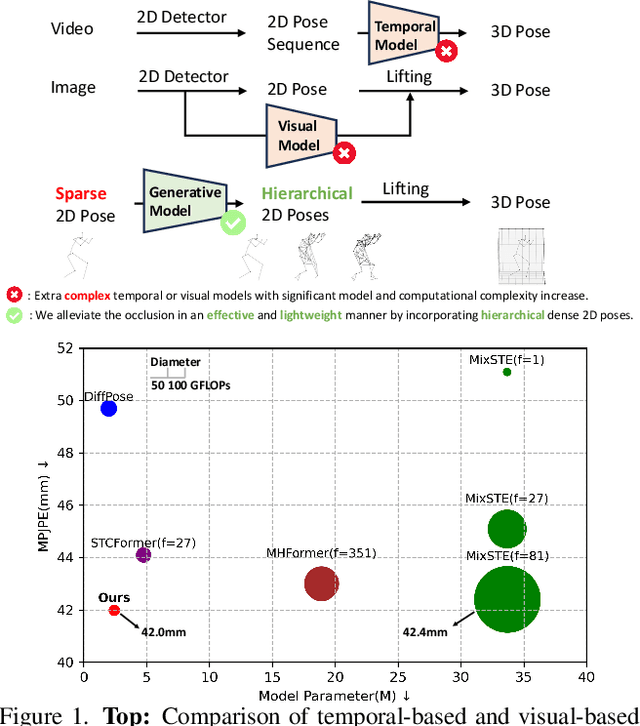
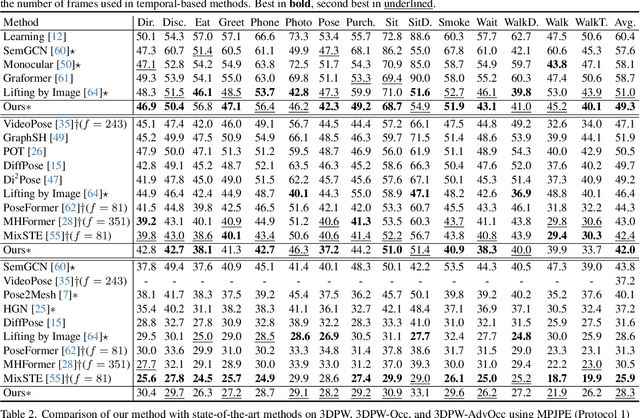
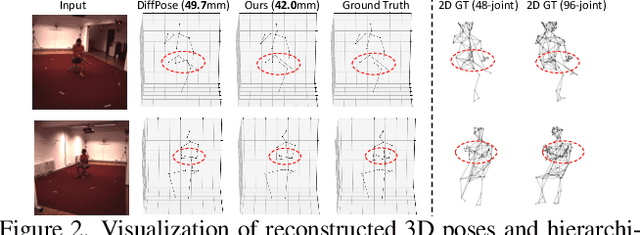
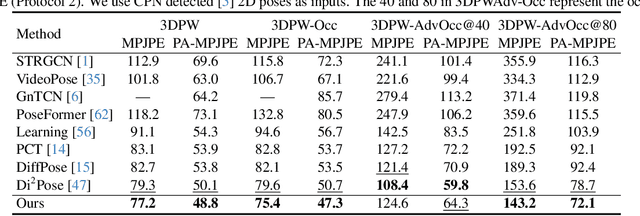
Existing 2D-to-3D human pose estimation (HPE) methods struggle with the occlusion issue by enriching information like temporal and visual cues in the lifting stage. In this paper, we argue that these methods ignore the limitation of the sparse skeleton 2D input representation, which fundamentally restricts the 2D-to-3D lifting and worsens the occlusion issue. To address these, we propose a novel two-stage generative densification method, named Hierarchical Pose AutoRegressive Transformer (HiPART), to generate hierarchical 2D dense poses from the original sparse 2D pose. Specifically, we first develop a multi-scale skeleton tokenization module to quantize the highly dense 2D pose into hierarchical tokens and propose a Skeleton-aware Alignment to strengthen token connections. We then develop a Hierarchical AutoRegressive Modeling scheme for hierarchical 2D pose generation. With generated hierarchical poses as inputs for 2D-to-3D lifting, the proposed method shows strong robustness in occluded scenarios and achieves state-of-the-art performance on the single-frame-based 3D HPE. Moreover, it outperforms numerous multi-frame methods while reducing parameter and computational complexity and can also complement them to further enhance performance and robustness.
On Disentangled Training for Nonlinear Transform in Learned Image Compression
Jan 23, 2025Learned image compression (LIC) has demonstrated superior rate-distortion (R-D) performance compared to traditional codecs, but is challenged by training inefficiency that could incur more than two weeks to train a state-of-the-art model from scratch. Existing LIC methods overlook the slow convergence caused by compacting energy in learning nonlinear transforms. In this paper, we first reveal that such energy compaction consists of two components, i.e., feature decorrelation and uneven energy modulation. On such basis, we propose a linear auxiliary transform (AuxT) to disentangle energy compaction in training nonlinear transforms. The proposed AuxT obtains coarse approximation to achieve efficient energy compaction such that distribution fitting with the nonlinear transforms can be simplified to fine details. We then develop wavelet-based linear shortcuts (WLSs) for AuxT that leverages wavelet-based downsampling and orthogonal linear projection for feature decorrelation and subband-aware scaling for uneven energy modulation. AuxT is lightweight and plug-and-play to be integrated into diverse LIC models to address the slow convergence issue. Experimental results demonstrate that the proposed approach can accelerate training of LIC models by 2 times and simultaneously achieves an average 1\% BD-rate reduction. To our best knowledge, this is one of the first successful attempt that can significantly improve the convergence of LIC with comparable or superior rate-distortion performance. Code will be released at \url{https://github.com/qingshi9974/AuxT}
Point Cloud Denoising With Fine-Granularity Dynamic Graph Convolutional Networks
Nov 21, 2024Due to limitations in acquisition equipment, noise perturbations often corrupt 3-D point clouds, hindering down-stream tasks such as surface reconstruction, rendering, and further processing. Existing 3-D point cloud denoising methods typically fail to reliably fit the underlying continuous surface, resulting in a degradation of reconstruction performance. This paper introduces fine-granularity dynamic graph convolutional networks called GD-GCN, a novel approach to denoising in 3-D point clouds. The GD-GCN employs micro-step temporal graph convolution (MST-GConv) to perform feature learning in a gradual manner. Compared with the conventional GCN, which commonly uses discrete integer-step graph convolution, this modification introduces a more adaptable and nuanced approach to feature learning within graph convolution networks. It more accurately depicts the process of fitting the point cloud with noise to the underlying surface by and the learning process for MST-GConv acts like a changing system and is managed through a type of neural network known as neural Partial Differential Equations (PDEs). This means it can adapt and improve over time. GD-GCN approximates the Riemannian metric, calculating distances between points along a low-dimensional manifold. This capability allows it to understand the local geometric structure and effectively capture diverse relationships between points from different geometric regions through geometric graph construction based on Riemannian distances. Additionally, GD-GCN incorporates robust graph spectral filters based on the Bernstein polynomial approximation, which modulate eigenvalues for complex and arbitrary spectral responses, providing theoretical guarantees for BIBO stability. Symmetric channel mixing matrices further enhance filter flexibility by enabling channel-level scaling and shifting in the spectral domain.
Point Cloud Resampling with Learnable Heat Diffusion
Nov 21, 2024Generative diffusion models have shown empirical successes in point cloud resampling, generating a denser and more uniform distribution of points from sparse or noisy 3D point clouds by progressively refining noise into structure. However, existing diffusion models employ manually predefined schemes, which often fail to recover the underlying point cloud structure due to the rigid and disruptive nature of the geometric degradation. To address this issue, we propose a novel learnable heat diffusion framework for point cloud resampling, which directly parameterizes the marginal distribution for the forward process by learning the adaptive heat diffusion schedules and local filtering scales of the time-varying heat kernel, and consequently, generates an adaptive conditional prior for the reverse process. Unlike previous diffusion models with a fixed prior, the adaptive conditional prior selectively preserves geometric features of the point cloud by minimizing a refined variational lower bound, guiding the points to evolve towards the underlying surface during the reverse process. Extensive experimental results demonstrate that the proposed point cloud resampling achieves state-of-the-art performance in representative reconstruction tasks including point cloud denoising and upsampling.
Image Compression for Machine and Human Vision with Spatial-Frequency Adaptation
Jul 13, 2024



Image compression for machine and human vision (ICMH) has gained increasing attention in recent years. Existing ICMH methods are limited by high training and storage overheads due to heavy design of task-specific networks. To address this issue, in this paper, we develop a novel lightweight adapter-based tuning framework for ICMH, named Adapt-ICMH, that better balances task performance and bitrates with reduced overheads. We propose a spatial-frequency modulation adapter (SFMA) that simultaneously eliminates non-semantic redundancy with a spatial modulation adapter, and enhances task-relevant frequency components and suppresses task-irrelevant frequency components with a frequency modulation adapter. The proposed adapter is plug-and-play and compatible with almost all existing learned image compression models without compromising the performance of pre-trained models. Experiments demonstrate that Adapt-ICMH consistently outperforms existing ICMH frameworks on various machine vision tasks with fewer fine-tuned parameters and reduced computational complexity. Code will be released at https://github.com/qingshi9974/ECCV2024-AdpatICMH .