 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Holistic Modeling for Video Frame Interpolation with Auto-regressive Diffusion Transformers
Jan 21, 2026Existing video frame interpolation (VFI) methods often adopt a frame-centric approach, processing videos as independent short segments (e.g., triplets), which leads to temporal inconsistencies and motion artifacts. To overcome this, we propose a holistic, video-centric paradigm named \textbf{L}ocal \textbf{D}iffusion \textbf{F}orcing for \textbf{V}ideo \textbf{F}rame \textbf{I}nterpolation (LDF-VFI). Our framework is built upon an auto-regressive diffusion transformer that models the entire video sequence to ensure long-range temporal coherence. To mitigate error accumulation inherent in auto-regressive generation, we introduce a novel skip-concatenate sampling strategy that effectively maintains temporal stability. Furthermore, LDF-VFI incorporates sparse, local attention and tiled VAE encoding, a combination that not only enables efficient processing of long sequences but also allows generalization to arbitrary spatial resolutions (e.g., 4K) at inference without retraining. An enhanced conditional VAE decoder, which leverages multi-scale features from the input video, further improves reconstruction fidelity. Empirically, LDF-VFI achieves state-of-the-art performance on challenging long-sequence benchmarks, demonstrating superior per-frame quality and temporal consistency, especially in scenes with large motion. The source code is available at https://github.com/xypeng9903/LDF-VFI.
DynamicRTL: RTL Representation Learning for Dynamic Circuit Behavior
Nov 12, 2025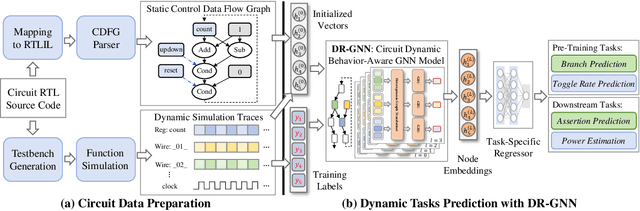

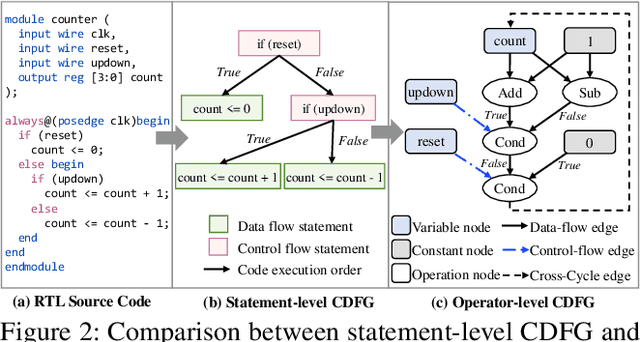

There is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of circuits, focusing primarily on their static characteristics. However, these models fail to capture circuit runtime behavior, which is crucial for tasks like circuit verification and optimization. To address this limitation, we introduce DR-GNN (DynamicRTL-GNN), a novel approach that learns RTL circuit representations by incorporating both static structures and multi-cycle execution behaviors. DR-GNN leverages an operator-level Control Data Flow Graph (CDFG) to represent Register Transfer Level (RTL) circuits, enabling the model to capture dynamic dependencies and runtime execution. To train and evaluate DR-GNN, we build the first comprehensive dynamic circuit dataset, comprising over 6,300 Verilog designs and 63,000 simulation traces. Our results demonstrate that DR-GNN outperforms existing models in branch hit prediction and toggle rate prediction. Furthermore, its learned representations transfer effectively to related dynamic circuit tasks, achieving strong performance in power estimation and assertion prediction.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025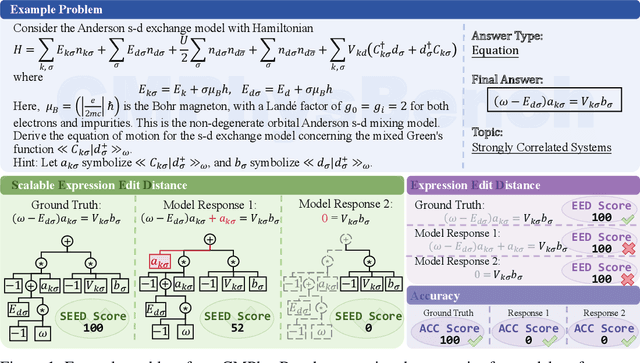
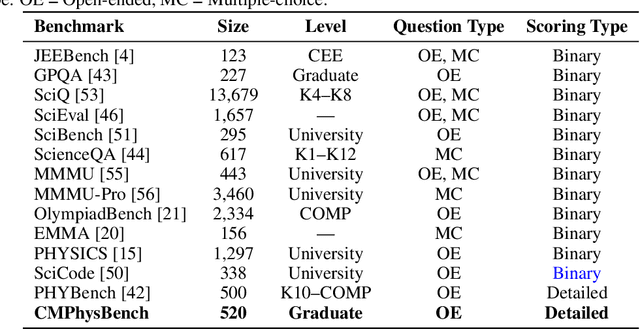
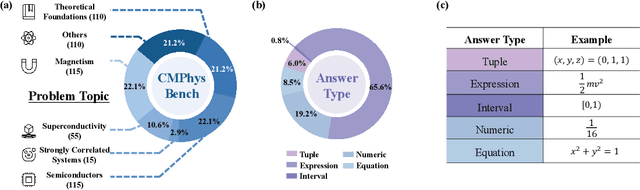

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
3DGabSplat: 3D Gabor Splatting for Frequency-adaptive Radiance Field Rendering
Aug 07, 2025Recent prominence in 3D Gaussian Splatting (3DGS) has enabled real-time rendering while maintaining high-fidelity novel view synthesis. However, 3DGS resorts to the Gaussian function that is low-pass by nature and is restricted in representing high-frequency details in 3D scenes. Moreover, it causes redundant primitives with degraded training and rendering efficiency and excessive memory overhead. To overcome these limitations, we propose 3D Gabor Splatting (3DGabSplat) that leverages a novel 3D Gabor-based primitive with multiple directional 3D frequency responses for radiance field representation supervised by multi-view images. The proposed 3D Gabor-based primitive forms a filter bank incorporating multiple 3D Gabor kernels at different frequencies to enhance flexibility and efficiency in capturing fine 3D details. Furthermore, to achieve novel view rendering, an efficient CUDA-based rasterizer is developed to project the multiple directional 3D frequency components characterized by 3D Gabor-based primitives onto the 2D image plane, and a frequency-adaptive mechanism is presented for adaptive joint optimization of primitives. 3DGabSplat is scalable to be a plug-and-play kernel for seamless integration into existing 3DGS paradigms to enhance both efficiency and quality of novel view synthesis. Extensive experiments demonstrate that 3DGabSplat outperforms 3DGS and its variants using alternative primitives, and achieves state-of-the-art rendering quality across both real-world and synthetic scenes. Remarkably, we achieve up to 1.35 dB PSNR gain over 3DGS with simultaneously reduced number of primitives and memory consumption.
Circuit-Aware SAT Solving: Guiding CDCL via Conditional Probabilities
Aug 06, 2025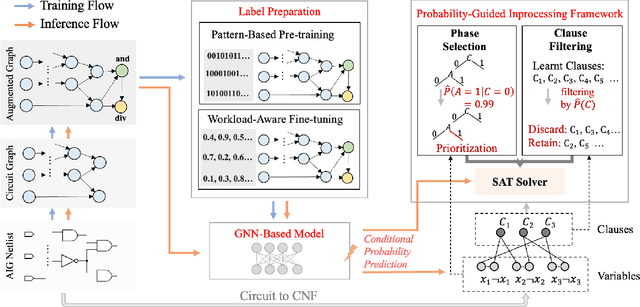

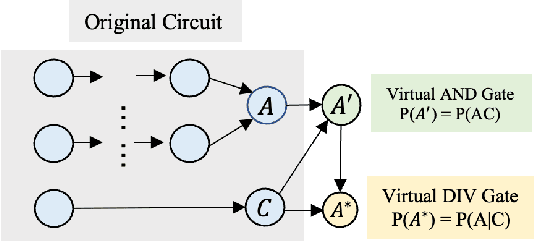

Circuit Satisfiability (CSAT) plays a pivotal role in Electronic Design Automation. The standard workflow for solving CSAT problems converts circuits into Conjunctive Normal Form (CNF) and employs generic SAT solvers powered by Conflict-Driven Clause Learning (CDCL). However, this process inherently discards rich structural and functional information, leading to suboptimal solver performance. To address this limitation, we introduce CASCAD, a novel circuit-aware SAT solving framework that directly leverages circuit-level conditional probabilities computed via Graph Neural Networks (GNNs). By explicitly modeling gate-level conditional probabilities, CASCAD dynamically guides two critical CDCL heuristics -- variable phase selection and clause managementto significantly enhance solver efficiency. Extensive evaluations on challenging real-world Logical Equivalence Checking (LEC) benchmarks demonstrate that CASCAD reduces solving times by up to 10x compared to state-of-the-art CNF-based approaches, achieving an additional 23.5% runtime reduction via our probability-guided clause filtering strategy. Our results underscore the importance of preserving circuit-level structural insights within SAT solvers, providing a robust foundation for future improvements in SAT-solving efficiency and EDA tool design.
Noise Conditional Variational Score Distillation
Jun 11, 2025
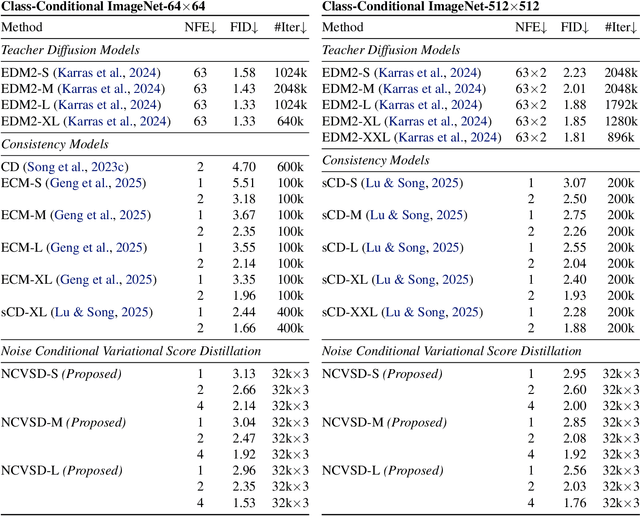
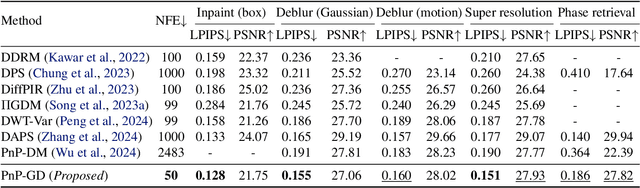

We propose Noise Conditional Variational Score Distillation (NCVSD), a novel method for distilling pretrained diffusion models into generative denoisers. We achieve this by revealing that the unconditional score function implicitly characterizes the score function of denoising posterior distributions. By integrating this insight into the Variational Score Distillation (VSD) framework, we enable scalable learning of generative denoisers capable of approximating samples from the denoising posterior distribution across a wide range of noise levels. The proposed generative denoisers exhibit desirable properties that allow fast generation while preserve the benefit of iterative refinement: (1) fast one-step generation through sampling from pure Gaussian noise at high noise levels; (2) improved sample quality by scaling the test-time compute with multi-step sampling; and (3) zero-shot probabilistic inference for flexible and controllable sampling. We evaluate NCVSD through extensive experiments, including class-conditional image generation and inverse problem solving. By scaling the test-time compute, our method outperforms teacher diffusion models and is on par with consistency models of larger sizes. Additionally, with significantly fewer NFEs than diffusion-based methods, we achieve record-breaking LPIPS on inverse problems.
Functional Matching of Logic Subgraphs: Beyond Structural Isomorphism
May 28, 2025Subgraph matching in logic circuits is foundational for numerous Electronic Design Automation (EDA) applications, including datapath optimization, arithmetic verification, and hardware trojan detection. However, existing techniques rely primarily on structural graph isomorphism and thus fail to identify function-related subgraphs when synthesis transformations substantially alter circuit topology. To overcome this critical limitation, we introduce the concept of functional subgraph matching, a novel approach that identifies whether a given logic function is implicitly present within a larger circuit, irrespective of structural variations induced by synthesis or technology mapping. Specifically, we propose a two-stage multi-modal framework: (1) learning robust functional embeddings across AIG and post-mapping netlists for functional subgraph detection, and (2) identifying fuzzy boundaries using a graph segmentation approach. Evaluations on standard benchmarks (ITC99, OpenABCD, ForgeEDA) demonstrate significant performance improvements over existing structural methods, with average $93.8\%$ accuracy in functional subgraph detection and a dice score of $91.3\%$ in fuzzy boundary identification.
HiPART: Hierarchical Pose AutoRegressive Transformer for Occluded 3D Human Pose Estimation
Mar 30, 2025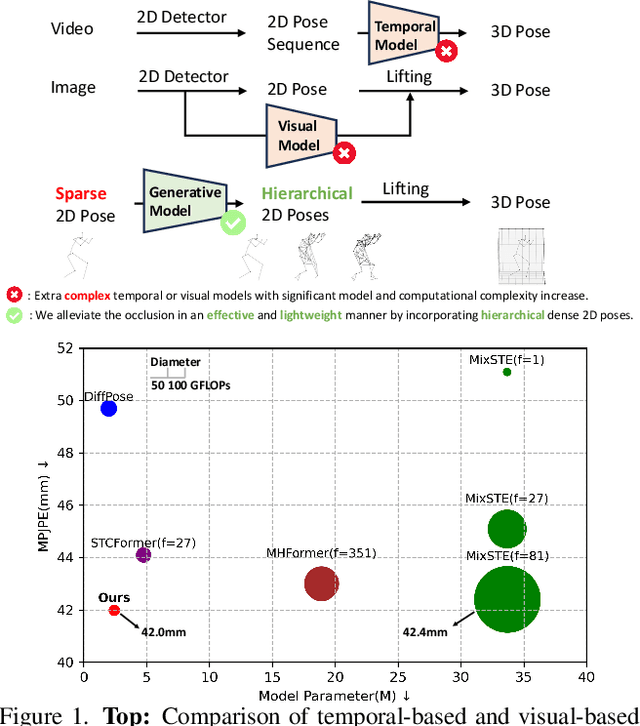
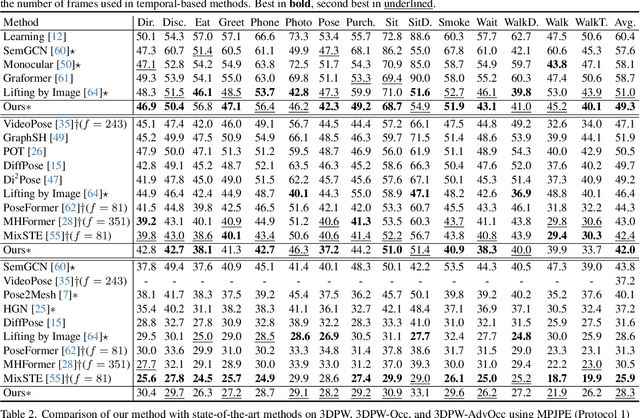
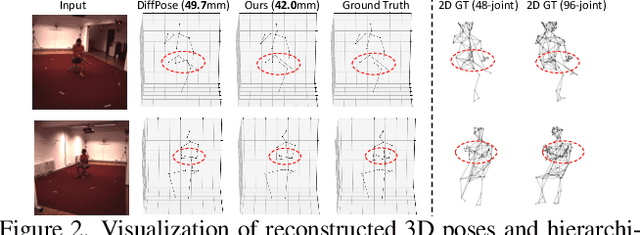
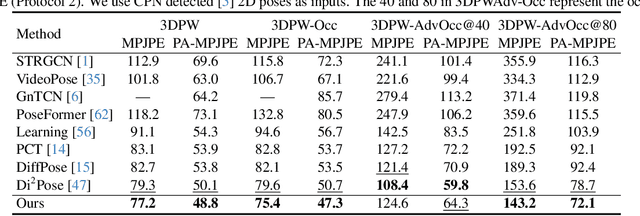
Existing 2D-to-3D human pose estimation (HPE) methods struggle with the occlusion issue by enriching information like temporal and visual cues in the lifting stage. In this paper, we argue that these methods ignore the limitation of the sparse skeleton 2D input representation, which fundamentally restricts the 2D-to-3D lifting and worsens the occlusion issue. To address these, we propose a novel two-stage generative densification method, named Hierarchical Pose AutoRegressive Transformer (HiPART), to generate hierarchical 2D dense poses from the original sparse 2D pose. Specifically, we first develop a multi-scale skeleton tokenization module to quantize the highly dense 2D pose into hierarchical tokens and propose a Skeleton-aware Alignment to strengthen token connections. We then develop a Hierarchical AutoRegressive Modeling scheme for hierarchical 2D pose generation. With generated hierarchical poses as inputs for 2D-to-3D lifting, the proposed method shows strong robustness in occluded scenarios and achieves state-of-the-art performance on the single-frame-based 3D HPE. Moreover, it outperforms numerous multi-frame methods while reducing parameter and computational complexity and can also complement them to further enhance performance and robustness.
Point Cloud Resampling with Learnable Heat Diffusion
Nov 21, 2024Generative diffusion models have shown empirical successes in point cloud resampling, generating a denser and more uniform distribution of points from sparse or noisy 3D point clouds by progressively refining noise into structure. However, existing diffusion models employ manually predefined schemes, which often fail to recover the underlying point cloud structure due to the rigid and disruptive nature of the geometric degradation. To address this issue, we propose a novel learnable heat diffusion framework for point cloud resampling, which directly parameterizes the marginal distribution for the forward process by learning the adaptive heat diffusion schedules and local filtering scales of the time-varying heat kernel, and consequently, generates an adaptive conditional prior for the reverse process. Unlike previous diffusion models with a fixed prior, the adaptive conditional prior selectively preserves geometric features of the point cloud by minimizing a refined variational lower bound, guiding the points to evolve towards the underlying surface during the reverse process. Extensive experimental results demonstrate that the proposed point cloud resampling achieves state-of-the-art performance in representative reconstruction tasks including point cloud denoising and upsampling.
Point Cloud Denoising With Fine-Granularity Dynamic Graph Convolutional Networks
Nov 21, 2024Due to limitations in acquisition equipment, noise perturbations often corrupt 3-D point clouds, hindering down-stream tasks such as surface reconstruction, rendering, and further processing. Existing 3-D point cloud denoising methods typically fail to reliably fit the underlying continuous surface, resulting in a degradation of reconstruction performance. This paper introduces fine-granularity dynamic graph convolutional networks called GD-GCN, a novel approach to denoising in 3-D point clouds. The GD-GCN employs micro-step temporal graph convolution (MST-GConv) to perform feature learning in a gradual manner. Compared with the conventional GCN, which commonly uses discrete integer-step graph convolution, this modification introduces a more adaptable and nuanced approach to feature learning within graph convolution networks. It more accurately depicts the process of fitting the point cloud with noise to the underlying surface by and the learning process for MST-GConv acts like a changing system and is managed through a type of neural network known as neural Partial Differential Equations (PDEs). This means it can adapt and improve over time. GD-GCN approximates the Riemannian metric, calculating distances between points along a low-dimensional manifold. This capability allows it to understand the local geometric structure and effectively capture diverse relationships between points from different geometric regions through geometric graph construction based on Riemannian distances. Additionally, GD-GCN incorporates robust graph spectral filters based on the Bernstein polynomial approximation, which modulate eigenvalues for complex and arbitrary spectral responses, providing theoretical guarantees for BIBO stability. Symmetric channel mixing matrices further enhance filter flexibility by enabling channel-level scaling and shifting in the spectral domain.