 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseMLLM: Standard Multimodal LLMs are Intrinsic Dense Predictors
Feb 15, 2026Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in high-level visual understanding. However, extending these models to fine-grained dense prediction tasks, such as semantic segmentation and depth estimation, typically necessitates the incorporation of complex, task-specific decoders and other customizations. This architectural fragmentation increases model complexity and deviates from the generalist design of MLLMs, ultimately limiting their practicality. In this work, we challenge this paradigm by accommodating standard MLLMs to perform dense predictions without requiring additional task-specific decoders. The proposed model is called DenseMLLM, grounded in the standard architecture with a novel vision token supervision strategy for multiple labels and tasks. Despite its minimalist design, our model achieves highly competitive performance across a wide range of dense prediction and vision-language benchmarks, demonstrating that a standard, general-purpose MLLM can effectively support dense perception without architectural specialization.
Multi-Modal Explainable Medical AI Assistant for Trustworthy Human-AI Collaboration
May 11, 2025Generalist Medical AI (GMAI) systems have demonstrated expert-level performance in biomedical perception tasks, yet their clinical utility remains limited by inadequate multi-modal explainability and suboptimal prognostic capabilities. Here, we present XMedGPT, a clinician-centric, multi-modal AI assistant that integrates textual and visual interpretability to support transparent and trustworthy medical decision-making. XMedGPT not only produces accurate diagnostic and descriptive outputs, but also grounds referenced anatomical sites within medical images, bridging critical gaps in interpretability and enhancing clinician usability. To support real-world deployment, we introduce a reliability indexing mechanism that quantifies uncertainty through consistency-based assessment via interactive question-answering. We validate XMedGPT across four pillars: multi-modal interpretability, uncertainty quantification, and prognostic modeling, and rigorous benchmarking. The model achieves an IoU of 0.703 across 141 anatomical regions, and a Kendall's tau-b of 0.479, demonstrating strong alignment between visual rationales and clinical outcomes. For uncertainty estimation, it attains an AUC of 0.862 on visual question answering and 0.764 on radiology report generation. In survival and recurrence prediction for lung and glioma cancers, it surpasses prior leading models by 26.9%, and outperforms GPT-4o by 25.0%. Rigorous benchmarking across 347 datasets covers 40 imaging modalities and external validation spans 4 anatomical systems confirming exceptional generalizability, with performance gains surpassing existing GMAI by 20.7% for in-domain evaluation and 16.7% on 11,530 in-house data evaluation. Together, XMedGPT represents a significant leap forward in clinician-centric AI integration, offering trustworthy and scalable support for diverse healthcare applications.
PaMi-VDPO: Mitigating Video Hallucinations by Prompt-Aware Multi-Instance Video Preference Learning
Apr 08, 2025



Direct Preference Optimization (DPO) helps reduce hallucinations in Video Multimodal Large Language Models (VLLMs), but its reliance on offline preference data limits adaptability and fails to capture true video-response misalignment. We propose Video Direct Preference Optimization (VDPO), an online preference learning framework that eliminates the need for preference annotation by leveraging video augmentations to generate rejected samples while keeping responses fixed. However, selecting effective augmentations is non-trivial, as some clips may be semantically identical to the original under specific prompts, leading to false rejections and disrupting alignment. To address this, we introduce Prompt-aware Multi-instance Learning VDPO (PaMi-VDPO), which selects augmentations based on prompt context. Instead of a single rejection, we construct a candidate set of augmented clips and apply a close-to-far selection strategy, initially ensuring all clips are semantically relevant while then prioritizing the most prompt-aware distinct clip. This allows the model to better capture meaningful visual differences, mitigating hallucinations, while avoiding false rejections, and improving alignment. PaMi-VDPOseamlessly integrates into existing VLLMs without additional parameters, GPT-4/human supervision. With only 10k SFT data, it improves the base model by 5.3% on VideoHallucer, surpassing GPT-4o, while maintaining stable performance on general video benchmarks.
Tri-Plane Mamba: Efficiently Adapting Segment Anything Model for 3D Medical Images
Sep 13, 2024General networks for 3D medical image segmentation have recently undergone extensive exploration. Behind the exceptional performance of these networks lies a significant demand for a large volume of pixel-level annotated data, which is time-consuming and labor-intensive. The emergence of the Segment Anything Model (SAM) has enabled this model to achieve superior performance in 2D medical image segmentation tasks via parameter- and data-efficient feature adaptation. However, the introduction of additional depth channels in 3D medical images not only prevents the sharing of 2D pre-trained features but also results in a quadratic increase in the computational cost for adapting SAM. To overcome these challenges, we present the Tri-Plane Mamba (TP-Mamba) adapters tailored for the SAM, featuring two major innovations: 1) multi-scale 3D convolutional adapters, optimized for efficiently processing local depth-level information, 2) a tri-plane mamba module, engineered to capture long-range depth-level representation without significantly increasing computational costs. This approach achieves state-of-the-art performance in 3D CT organ segmentation tasks. Remarkably, this superior performance is maintained even with scarce training data. Specifically using only three CT training samples from the BTCV dataset, it surpasses conventional 3D segmentation networks, attaining a Dice score that is up to 12% higher.
HiRes-LLaVA: Restoring Fragmentation Input in High-Resolution Large Vision-Language Models
Jul 11, 2024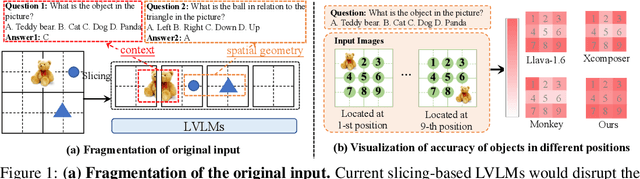
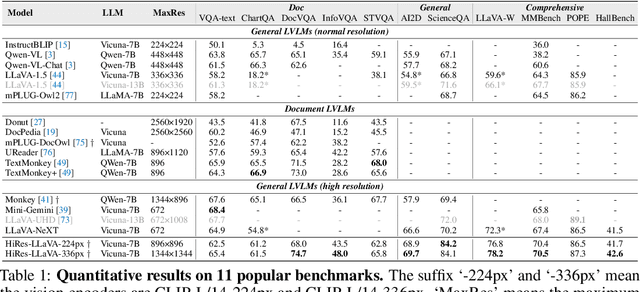
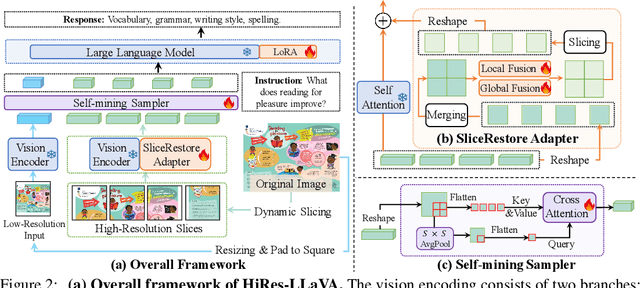

High-resolution inputs enable Large Vision-Language Models (LVLMs) to discern finer visual details, enhancing their comprehension capabilities. To reduce the training and computation costs caused by high-resolution input, one promising direction is to use sliding windows to slice the input into uniform patches, each matching the input size of the well-trained vision encoder. Although efficient, this slicing strategy leads to the fragmentation of original input, i.e., the continuity of contextual information and spatial geometry is lost across patches, adversely affecting performance in cross-patch context perception and position-specific tasks. To overcome these shortcomings, we introduce HiRes-LLaVA, a novel framework designed to efficiently process any size of high-resolution input without altering the original contextual and geometric information. HiRes-LLaVA comprises two innovative components: (i) a SliceRestore adapter that reconstructs sliced patches into their original form, efficiently extracting both global and local features via down-up-sampling and convolution layers, and (ii) a Self-Mining Sampler to compresses the vision tokens based on themselves, preserving the original context and positional information while reducing training overhead. To assess the ability of handling context fragmentation, we construct a new benchmark, EntityGrid-QA, consisting of edge-related and position-related tasks. Our comprehensive experiments demonstrate the superiority of HiRes-LLaVA on both existing public benchmarks and on EntityGrid-QA, particularly on document-oriented tasks, establishing new standards for handling high-resolution inputs.
C^2RV: Cross-Regional and Cross-View Learning for Sparse-View CBCT Reconstruction
Jun 06, 2024Cone beam computed tomography (CBCT) is an important imaging technology widely used in medical scenarios, such as diagnosis and preoperative planning. Using fewer projection views to reconstruct CT, also known as sparse-view reconstruction, can reduce ionizing radiation and further benefit interventional radiology. Compared with sparse-view reconstruction for traditional parallel/fan-beam CT, CBCT reconstruction is more challenging due to the increased dimensionality caused by the measurement process based on cone-shaped X-ray beams. As a 2D-to-3D reconstruction problem, although implicit neural representations have been introduced to enable efficient training, only local features are considered and different views are processed equally in previous works, resulting in spatial inconsistency and poor performance on complicated anatomies. To this end, we propose C^2RV by leveraging explicit multi-scale volumetric representations to enable cross-regional learning in the 3D space. Additionally, the scale-view cross-attention module is introduced to adaptively aggregate multi-scale and multi-view features. Extensive experiments demonstrate that our C^2RV achieves consistent and significant improvement over previous state-of-the-art methods on datasets with diverse anatomy.
Holistic Autonomous Driving Understanding by Bird's-Eye-View Injected Multi-Modal Large Models
Jan 02, 2024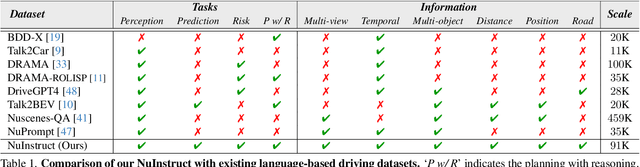
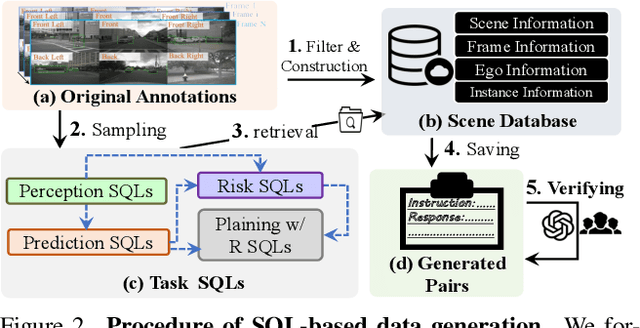
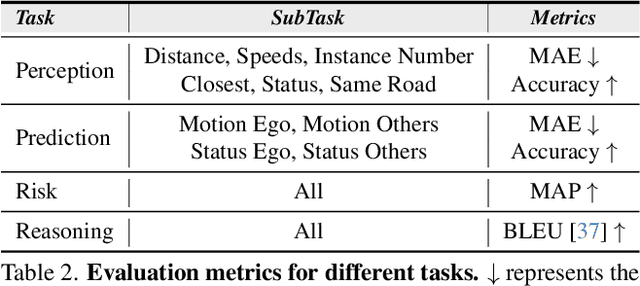
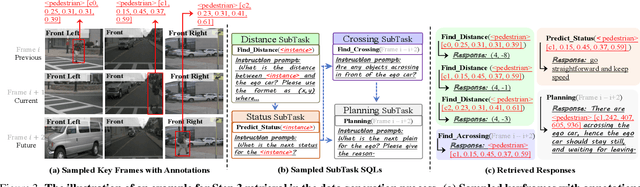
The rise of multimodal large language models (MLLMs) has spurred interest in language-based driving tasks. However, existing research typically focuses on limited tasks and often omits key multi-view and temporal information which is crucial for robust autonomous driving. To bridge these gaps, we introduce NuInstruct, a novel dataset with 91K multi-view video-QA pairs across 17 subtasks, where each task demands holistic information (e.g., temporal, multi-view, and spatial), significantly elevating the challenge level. To obtain NuInstruct, we propose a novel SQL-based method to generate instruction-response pairs automatically, which is inspired by the driving logical progression of humans. We further present BEV-InMLLM, an end-to-end method for efficiently deriving instruction-aware Bird's-Eye-View (BEV) features, language-aligned for large language models. BEV-InMLLM integrates multi-view, spatial awareness, and temporal semantics to enhance MLLMs' capabilities on NuInstruct tasks. Moreover, our proposed BEV injection module is a plug-and-play method for existing MLLMs. Our experiments on NuInstruct demonstrate that BEV-InMLLM significantly outperforms existing MLLMs, e.g. around 9% improvement on various tasks. We plan to release our NuInstruct for future research development.
EtC: Temporal Boundary Expand then Clarify for Weakly Supervised Video Grounding with Multimodal Large Language Model
Dec 05, 2023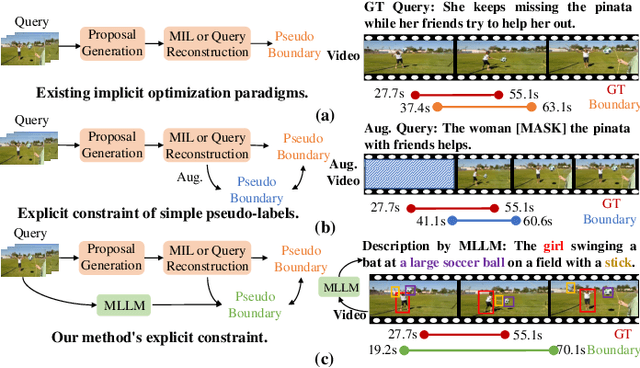
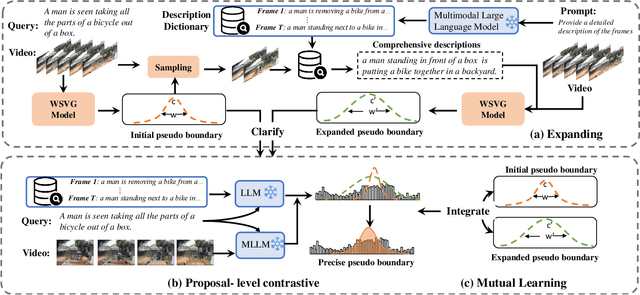
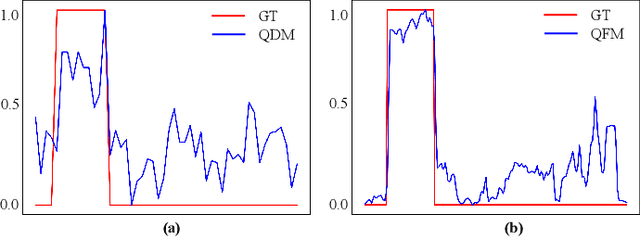

Early weakly supervised video grounding (WSVG) methods often struggle with incomplete boundary detection due to the absence of temporal boundary annotations. To bridge the gap between video-level and boundary-level annotation, explicit-supervision methods, i.e., generating pseudo-temporal boundaries for training, have achieved great success. However, data augmentations in these methods might disrupt critical temporal information, yielding poor pseudo boundaries. In this paper, we propose a new perspective that maintains the integrity of the original temporal content while introducing more valuable information for expanding the incomplete boundaries. To this end, we propose EtC (Expand then Clarify), first use the additional information to expand the initial incomplete pseudo boundaries, and subsequently refine these expanded ones to achieve precise boundaries. Motivated by video continuity, i.e., visual similarity across adjacent frames, we use powerful multimodal large language models (MLLMs) to annotate each frame within initial pseudo boundaries, yielding more comprehensive descriptions for expanded boundaries. To further clarify the noise of expanded boundaries, we combine mutual learning with a tailored proposal-level contrastive objective to use a learnable approach to harmonize a balance between incomplete yet clean (initial) and comprehensive yet noisy (expanded) boundaries for more precise ones. Experiments demonstrate the superiority of our method on two challenging WSVG datasets.
GL-Fusion: Global-Local Fusion Network for Multi-view Echocardiogram Video Segmentation
Sep 20, 2023



Cardiac structure segmentation from echocardiogram videos plays a crucial role in diagnosing heart disease. The combination of multi-view echocardiogram data is essential to enhance the accuracy and robustness of automated methods. However, due to the visual disparity of the data, deriving cross-view context information remains a challenging task, and unsophisticated fusion strategies can even lower performance. In this study, we propose a novel Gobal-Local fusion (GL-Fusion) network to jointly utilize multi-view information globally and locally that improve the accuracy of echocardiogram analysis. Specifically, a Multi-view Global-based Fusion Module (MGFM) is proposed to extract global context information and to explore the cyclic relationship of different heartbeat cycles in an echocardiogram video. Additionally, a Multi-view Local-based Fusion Module (MLFM) is designed to extract correlations of cardiac structures from different views. Furthermore, we collect a multi-view echocardiogram video dataset (MvEVD) to evaluate our method. Our method achieves an 82.29% average dice score, which demonstrates a 7.83% improvement over the baseline method, and outperforms other existing state-of-the-art methods. To our knowledge, this is the first exploration of a multi-view method for echocardiogram video segmentation. Code available at: https://github.com/xmed-lab/GL-Fusion
GraphEcho: Graph-Driven Unsupervised Domain Adaptation for Echocardiogram Video Segmentation
Sep 20, 2023



Echocardiogram video segmentation plays an important role in cardiac disease diagnosis. This paper studies the unsupervised domain adaption (UDA) for echocardiogram video segmentation, where the goal is to generalize the model trained on the source domain to other unlabelled target domains. Existing UDA segmentation methods are not suitable for this task because they do not model local information and the cyclical consistency of heartbeat. In this paper, we introduce a newly collected CardiacUDA dataset and a novel GraphEcho method for cardiac structure segmentation. Our GraphEcho comprises two innovative modules, the Spatial-wise Cross-domain Graph Matching (SCGM) and the Temporal Cycle Consistency (TCC) module, which utilize prior knowledge of echocardiogram videos, i.e., consistent cardiac structure across patients and centers and the heartbeat cyclical consistency, respectively. These two modules can better align global and local features from source and target domains, improving UDA segmentation results. Experimental results showed that our GraphEcho outperforms existing state-of-the-art UDA segmentation methods. Our collected dataset and code will be publicly released upon acceptance. This work will lay a new and solid cornerstone for cardiac structure segmentation from echocardiogram videos. Code and dataset are available at: https://github.com/xmed-lab/GraphEcho