 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchJudge: A Diagnostic Benchmark for Grading Hand-drawn Diagrams with Multimodal Large Language Models
Jan 11, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable progress in visual understanding, they often struggle when faced with the unstructured and ambiguous nature of human-generated sketches. This limitation is particularly pronounced in the underexplored task of visual grading, where models should not only solve a problem but also diagnose errors in hand-drawn diagrams. Such diagnostic capabilities depend on complex structural, semantic, and metacognitive reasoning. To bridge this gap, we introduce SketchJudge, a novel benchmark tailored for evaluating MLLMs as graders of hand-drawn STEM diagrams. SketchJudge encompasses 1,015 hand-drawn student responses across four domains: geometry, physics, charts, and flowcharts, featuring diverse stylistic variations and distinct error types. Evaluations on SketchJudge demonstrate that even advanced MLLMs lag significantly behind humans, validating the benchmark's effectiveness in exposing the fragility of current vision-language alignment in symbolic and noisy contexts. All data, code, and evaluation scripts are publicly available at https://github.com/yuhangsu82/SketchJudge.
StPR: Spatiotemporal Preservation and Routing for Exemplar-Free Video Class-Incremental Learning
May 20, 2025Video Class-Incremental Learning (VCIL) seeks to develop models that continuously learn new action categories over time without forgetting previously acquired knowledge. Unlike traditional Class-Incremental Learning (CIL), VCIL introduces the added complexity of spatiotemporal structures, making it particularly challenging to mitigate catastrophic forgetting while effectively capturing both frame-shared semantics and temporal dynamics. Existing approaches either rely on exemplar rehearsal, raising concerns over memory and privacy, or adapt static image-based methods that neglect temporal modeling. To address these limitations, we propose Spatiotemporal Preservation and Routing (StPR), a unified and exemplar-free VCIL framework that explicitly disentangles and preserves spatiotemporal information. First, we introduce Frame-Shared Semantics Distillation (FSSD), which identifies semantically stable and meaningful channels by jointly considering semantic sensitivity and classification contribution. These important semantic channels are selectively regularized to maintain prior knowledge while allowing for adaptation. Second, we design a Temporal Decomposition-based Mixture-of-Experts (TD-MoE), which dynamically routes task-specific experts based on their temporal dynamics, enabling inference without task ID or stored exemplars. Together, StPR effectively leverages spatial semantics and temporal dynamics, achieving a unified, exemplar-free VCIL framework. Extensive experiments on UCF101, HMDB51, and Kinetics400 show that our method outperforms existing baselines while offering improved interpretability and efficiency in VCIL. Code is available in the supplementary materials.
CLIP-Driven Cloth-Agnostic Feature Learning for Cloth-Changing Person Re-Identification
Jun 13, 2024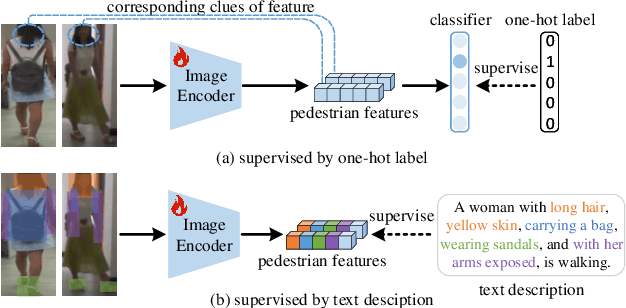

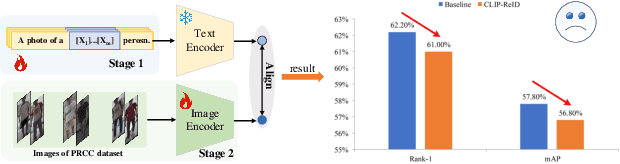
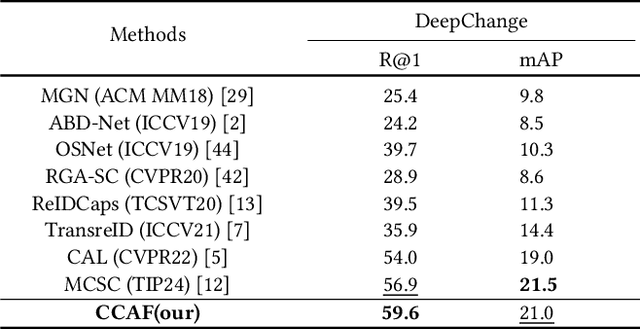
Contrastive Language-Image Pre-Training (CLIP) has shown impressive performance in short-term Person Re-Identification (ReID) due to its ability to extract high-level semantic features of pedestrians, yet its direct application to Cloth-Changing Person Re-Identification (CC-ReID) faces challenges due to CLIP's image encoder overly focusing on clothes clues. To address this, we propose a novel framework called CLIP-Driven Cloth-Agnostic Feature Learning (CCAF) for CC-ReID. Accordingly, two modules were custom-designed: the Invariant Feature Prompting (IFP) and the Clothes Feature Minimization (CFM). These modules guide the model to extract cloth-agnostic features positively and attenuate clothes-related features negatively. Specifically, IFP is designed to extract fine-grained semantic features unrelated to clothes from the raw image, guided by the cloth-agnostic text prompts. This module first covers the clothes in the raw image at the pixel level to obtain the shielding image and then utilizes CLIP's knowledge to generate cloth-agnostic text prompts. Subsequently, it aligns the raw image-text and the raw image-shielding image in the feature space, emphasizing discriminative clues related to identity but unrelated to clothes. Furthermore, CFM is designed to examine and weaken the image encoder's ability to extract clothes features. It first generates text prompts corresponding to clothes pixels. Then, guided by these clothes text prompts, it iteratively examines and disentangles clothes features from pedestrian features, ultimately retaining inherent discriminative features. Extensive experiments have demonstrated the effectiveness of the proposed CCAF, achieving new state-of-the-art performance on several popular CC-ReID benchmarks without any additional inference time.
EtC: Temporal Boundary Expand then Clarify for Weakly Supervised Video Grounding with Multimodal Large Language Model
Dec 05, 2023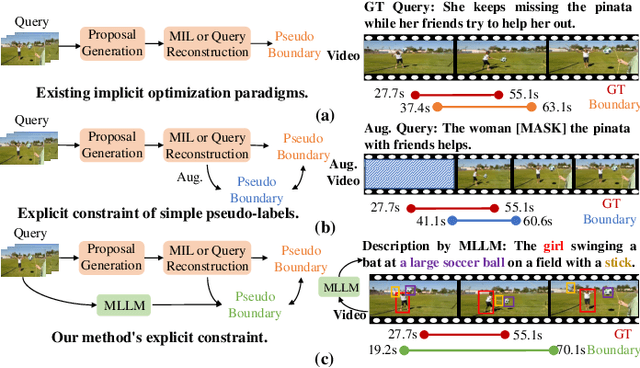
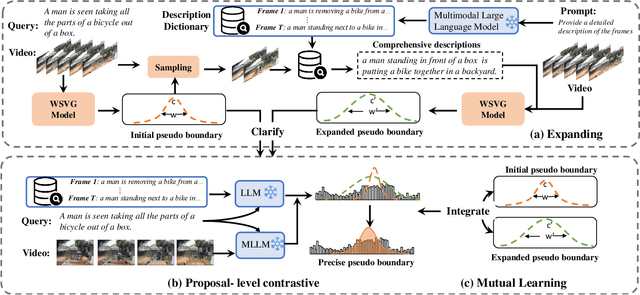
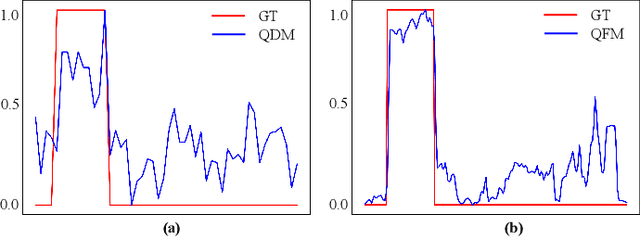

Early weakly supervised video grounding (WSVG) methods often struggle with incomplete boundary detection due to the absence of temporal boundary annotations. To bridge the gap between video-level and boundary-level annotation, explicit-supervision methods, i.e., generating pseudo-temporal boundaries for training, have achieved great success. However, data augmentations in these methods might disrupt critical temporal information, yielding poor pseudo boundaries. In this paper, we propose a new perspective that maintains the integrity of the original temporal content while introducing more valuable information for expanding the incomplete boundaries. To this end, we propose EtC (Expand then Clarify), first use the additional information to expand the initial incomplete pseudo boundaries, and subsequently refine these expanded ones to achieve precise boundaries. Motivated by video continuity, i.e., visual similarity across adjacent frames, we use powerful multimodal large language models (MLLMs) to annotate each frame within initial pseudo boundaries, yielding more comprehensive descriptions for expanded boundaries. To further clarify the noise of expanded boundaries, we combine mutual learning with a tailored proposal-level contrastive objective to use a learnable approach to harmonize a balance between incomplete yet clean (initial) and comprehensive yet noisy (expanded) boundaries for more precise ones. Experiments demonstrate the superiority of our method on two challenging WSVG datasets.
Boosting Weakly-Supervised Temporal Action Localization with Text Information
May 01, 2023Due to the lack of temporal annotation, current Weakly-supervised Temporal Action Localization (WTAL) methods are generally stuck into over-complete or incomplete localization. In this paper, we aim to leverage the text information to boost WTAL from two aspects, i.e., (a) the discriminative objective to enlarge the inter-class difference, thus reducing the over-complete; (b) the generative objective to enhance the intra-class integrity, thus finding more complete temporal boundaries. For the discriminative objective, we propose a Text-Segment Mining (TSM) mechanism, which constructs a text description based on the action class label, and regards the text as the query to mine all class-related segments. Without the temporal annotation of actions, TSM compares the text query with the entire videos across the dataset to mine the best matching segments while ignoring irrelevant ones. Due to the shared sub-actions in different categories of videos, merely applying TSM is too strict to neglect the semantic-related segments, which results in incomplete localization. We further introduce a generative objective named Video-text Language Completion (VLC), which focuses on all semantic-related segments from videos to complete the text sentence. We achieve the state-of-the-art performance on THUMOS14 and ActivityNet1.3. Surprisingly, we also find our proposed method can be seamlessly applied to existing methods, and improve their performances with a clear margin. The code is available at https://github.com/lgzlIlIlI/Boosting-WTAL.
Weakly-Supervised Temporal Action Localization with Bidirectional Semantic Consistency Constraint
Apr 25, 2023Weakly Supervised Temporal Action Localization (WTAL) aims to classify and localize temporal boundaries of actions for the video, given only video-level category labels in the training datasets. Due to the lack of boundary information during training, existing approaches formulate WTAL as a classificationproblem, i.e., generating the temporal class activation map (T-CAM) for localization. However, with only classification loss, the model would be sub-optimized, i.e., the action-related scenes are enough to distinguish different class labels. Regarding other actions in the action-related scene ( i.e., the scene same as positive actions) as co-scene actions, this sub-optimized model would misclassify the co-scene actions as positive actions. To address this misclassification, we propose a simple yet efficient method, named bidirectional semantic consistency constraint (Bi-SCC), to discriminate the positive actions from co-scene actions. The proposed Bi-SCC firstly adopts a temporal context augmentation to generate an augmented video that breaks the correlation between positive actions and their co-scene actions in the inter-video; Then, a semantic consistency constraint (SCC) is used to enforce the predictions of the original video and augmented video to be consistent, hence suppressing the co-scene actions. However, we find that this augmented video would destroy the original temporal context. Simply applying the consistency constraint would affect the completeness of localized positive actions. Hence, we boost the SCC in a bidirectional way to suppress co-scene actions while ensuring the integrity of positive actions, by cross-supervising the original and augmented videos. Finally, our proposed Bi-SCC can be applied to current WTAL approaches, and improve their performance. Experimental results show that our approach outperforms the state-of-the-art methods on THUMOS14 and ActivityNet.